引言
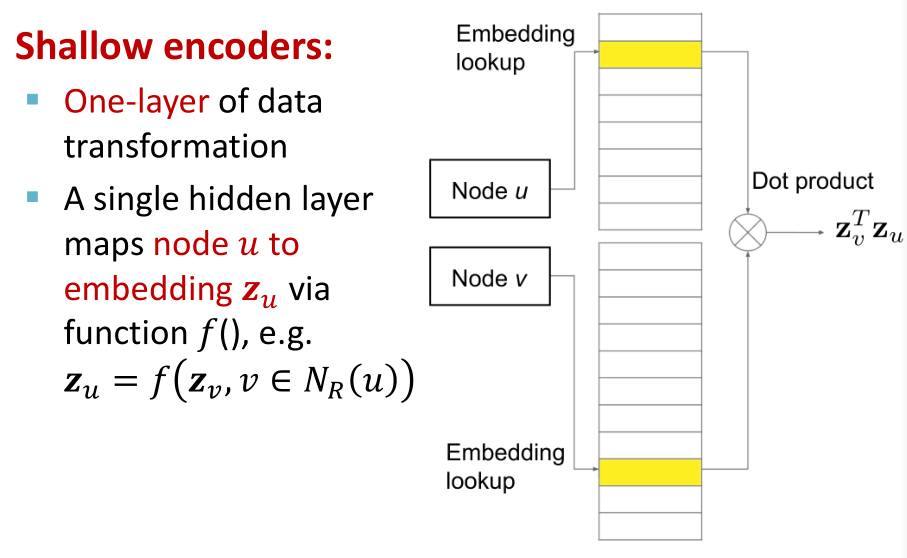
- 之前提到过图嵌入的概念,将一个图中所有结点转变为特征向量表示需要一个映射f,之前我们通过构造嵌入矩阵来实现,也就是所说的“浅”编码。
- 两个结点计算相似度时其实就是一个查找的过程
- 对于每个图都需要将所有结点全部计算一遍
- 训练是直推的,而非半监督。只能为训练时可见的结点生成嵌入向量
- 没有将结点特征纳入考虑
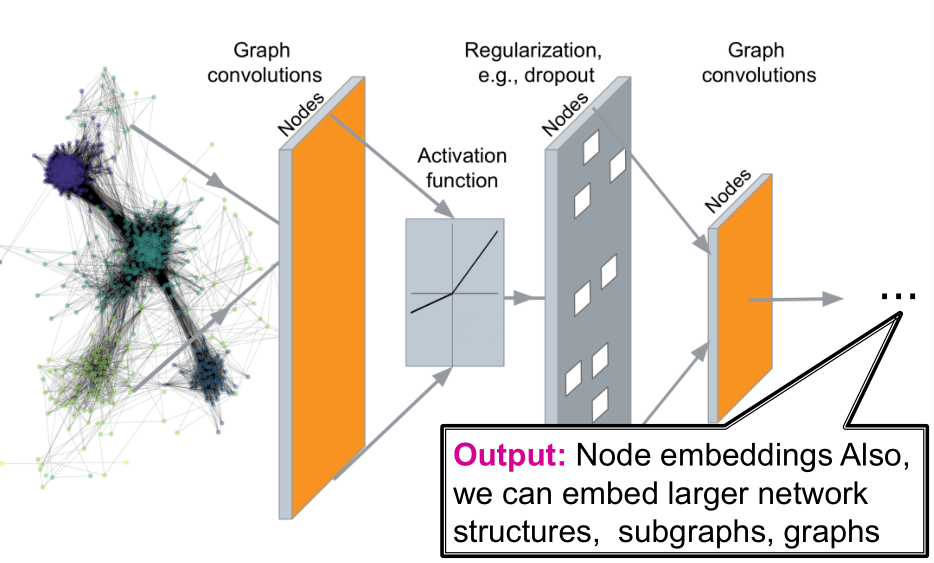
- 在图神经网络中,编码器表现为多层对图结构的非线性变换。同样,这些深层编码器可以与之前计算结点相似度的方法联系在一起。
- 由于图的形状是任意的,且通常具有非常复杂的结构,所以训练起来相当困难
- CNN层与层之间通过卷积进行值的计算,即捕捉像素与周围像素的信息。那么图也可以进行类比,如捕捉结点与其邻居的信息
图深度学习基础
准备:给定一个图G
- V为结点集
- A为邻接矩阵
 为包含结点特征的矩阵(如在社交网络中可表现为用户信息,若无特征可表现使用one-hot向量或每一维度均为常数的向量)
为包含结点特征的矩阵(如在社交网络中可表现为用户信息,若无特征可表现使用one-hot向量或每一维度均为常数的向量)
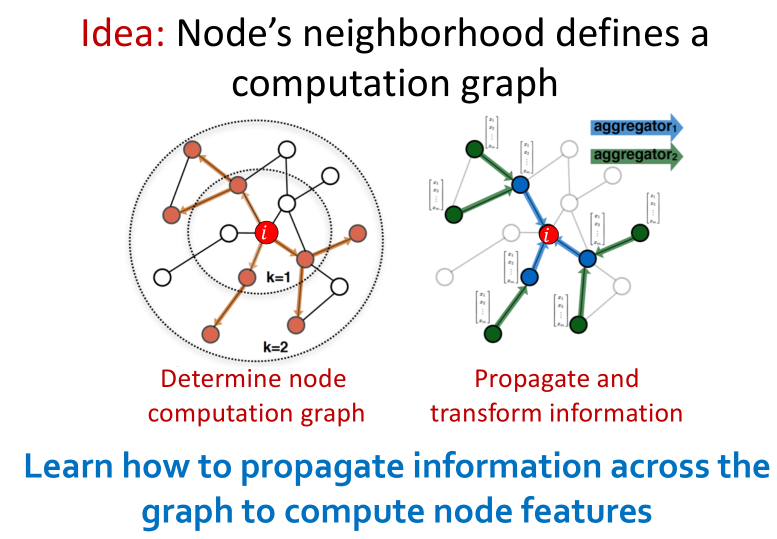
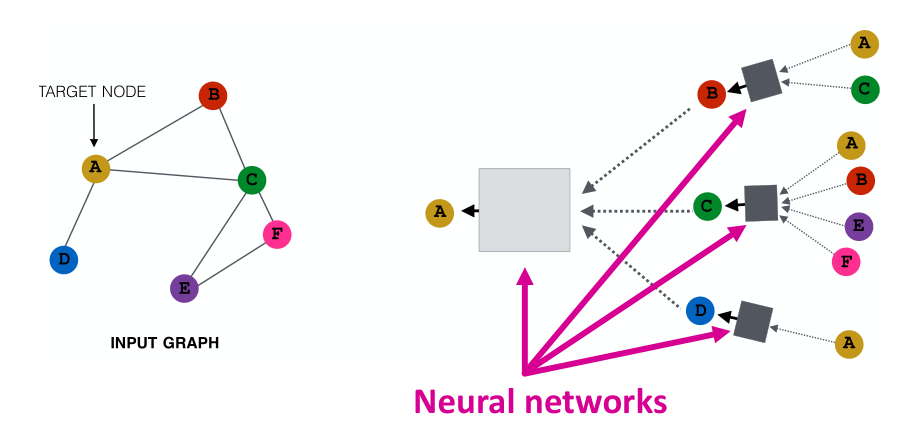
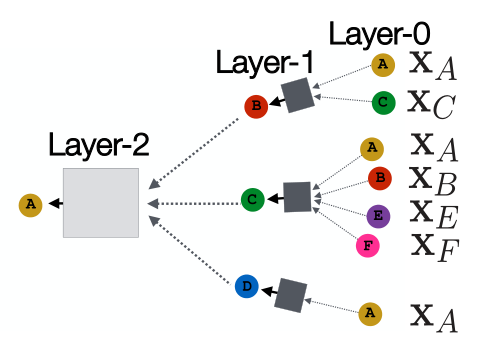
计算图:由每个结点的邻居与其自身构成
- 计算结点特征时的核心思想是对结点周围的邻居特征进行“累计”的操作。如在右图中由于A的邻居是B、C、D,因此输出A的前一层就需要这三个结点的计算结果。而B的邻居又是A与C,以此类推。。
- 这个“累计”的操作可以由简单的计算完成,也可以由神经网络完成
- 模型的深度可以是任意的,在第0层中,结点的嵌入向量就是自身的特征值(输入)。k层网络获得的嵌入向量可以获得一阶邻居到k阶邻居的信息。
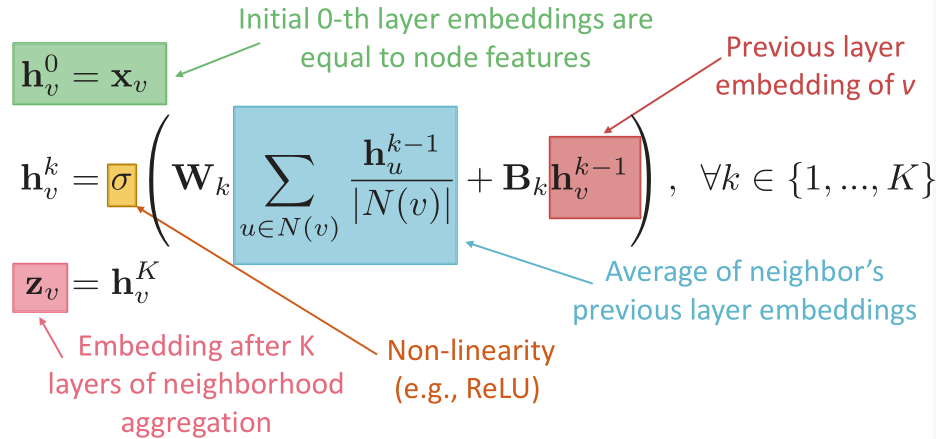
- 数学原理:没什么内容,就是把前一层的输出取一个均值再加一个偏置项,再经过一个普通的激活函数。学习的东西就是权重
 以及偏置项
以及偏置项
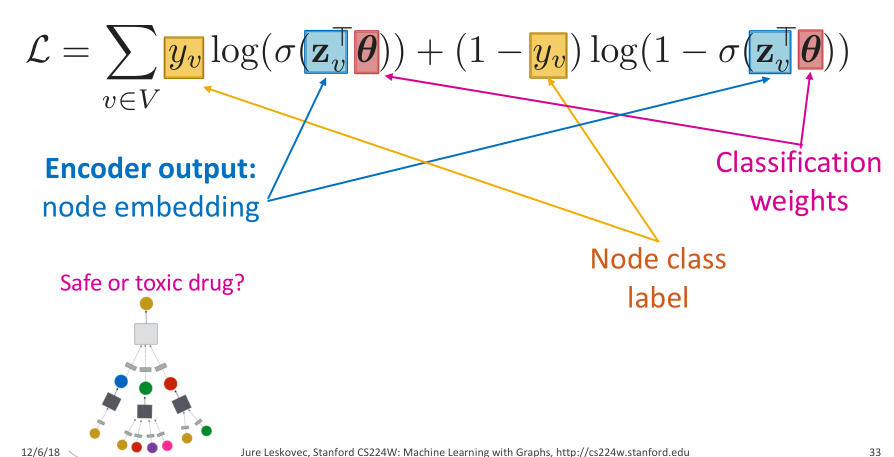
- 训练:可以使用无监督学习,也可以使用监督学习
- 无监督学习的损失函数可以基于随机游走等方法
- 当需要对节点的特征进行分类等操作时,则需要使用交叉熵损失函数
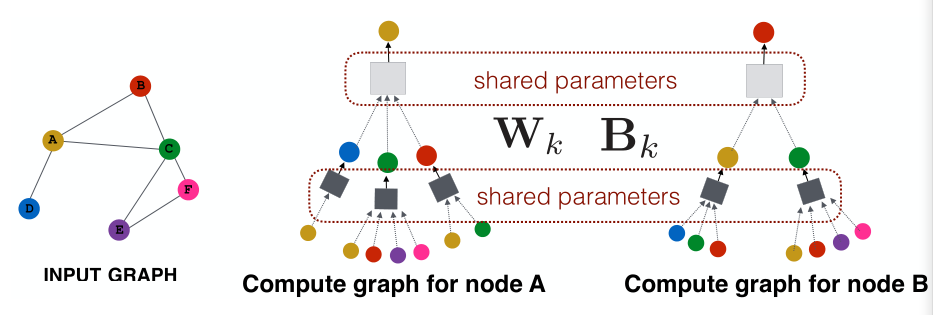
- 总结:
- 同一层数之间层与层之间的参数是完全共享的(但不同层数之间的不是,如计算一阶邻居的隐藏层与计算二阶邻居的隐藏层就不共享)
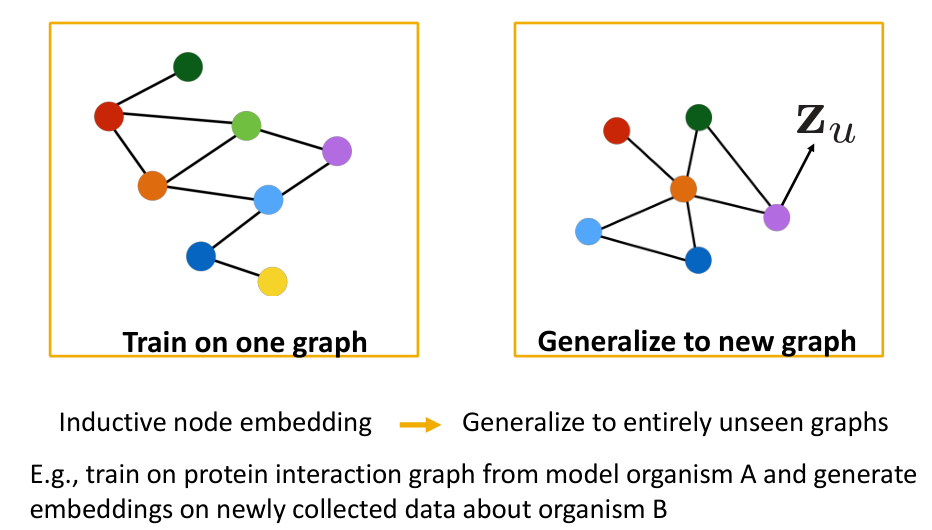
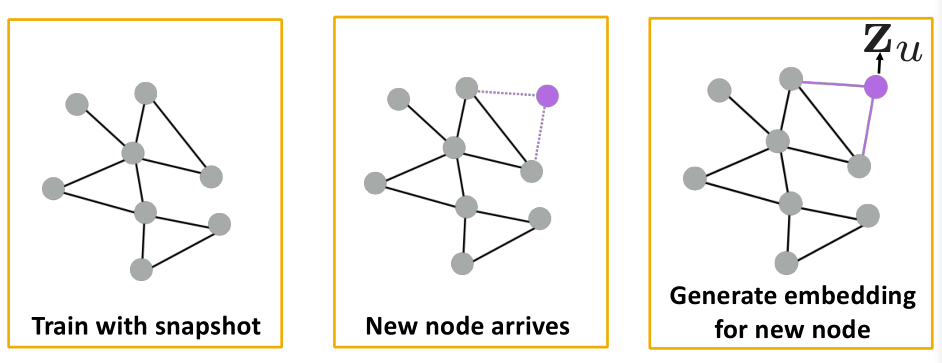
- 每一层的输入个数都是不确定的,具有非常好的泛化性
- 通过训练图的一小个子图就可以达到预测其他部分的目的
- 对于新加入的结点也有很好的适配效果,达到解耦的目的
图卷积网络
- GraphSAGE:就是由Jure老师提出的
- 原始的卷积网络只是简单地把结点信息进行了“累计”的操作,但还可以再进一步
- 我们可以定义许多不同的Aggregate函数,取均值,池化甚至LSTM都可以
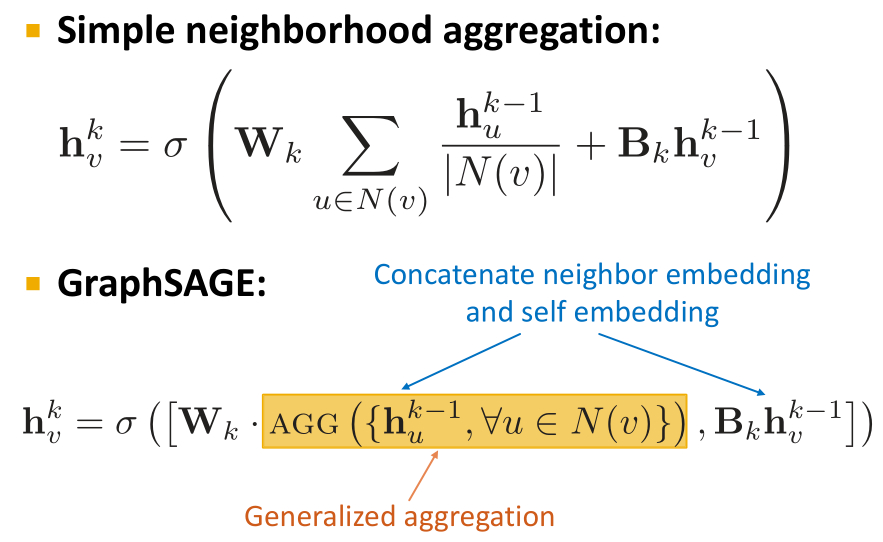

- 提高效率:许多aggregate操作都可以由矩阵变换完成

图注意力网络
引入:在原始GCN中,对于结点v,它的所有邻居的重要性都是等同的;且aggregate操作严格按照图的结构进行计算,每个邻居的权重
 ,是严格定义好的。
,是严格定义好的。- 所以我们希望一个结点周围的邻居重要性是不等同的
我们需要加入注意力机制
 来实现注意力机制
来实现注意力机制- 使用通过结点u、v各自的信息可以计算出注意力系数
 ,这一系数代表了结点u传至结点v信息的重要程度
,这一系数代表了结点u传至结点v信息的重要程度 - 随后我们再将
 经过归一化得出最终的权重
经过归一化得出最终的权重 ,之后就可以得出隐藏层中前向传播的公式了:
,之后就可以得出隐藏层中前向传播的公式了:
- 使用
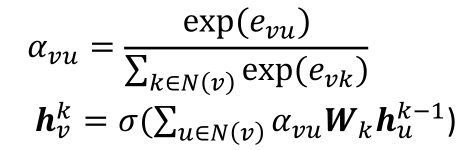
- 注意力机制a可以有很多实现方式(MLP或其他包含参数的网络)。a中的参数是需要学习的,与整个图神经网络一起训练
- 多头注意力机制(Multi-head attention):使注意力机制的学习过程趋于稳定。在给定的一层中注意力操作会独立地重复R次,同时输出会将每次的结果累积起来
- 总结:非常好的方法,这样每个邻居的权重都不同了,比GCN更进一步

若有收获,就点个赞吧
0 人点赞
