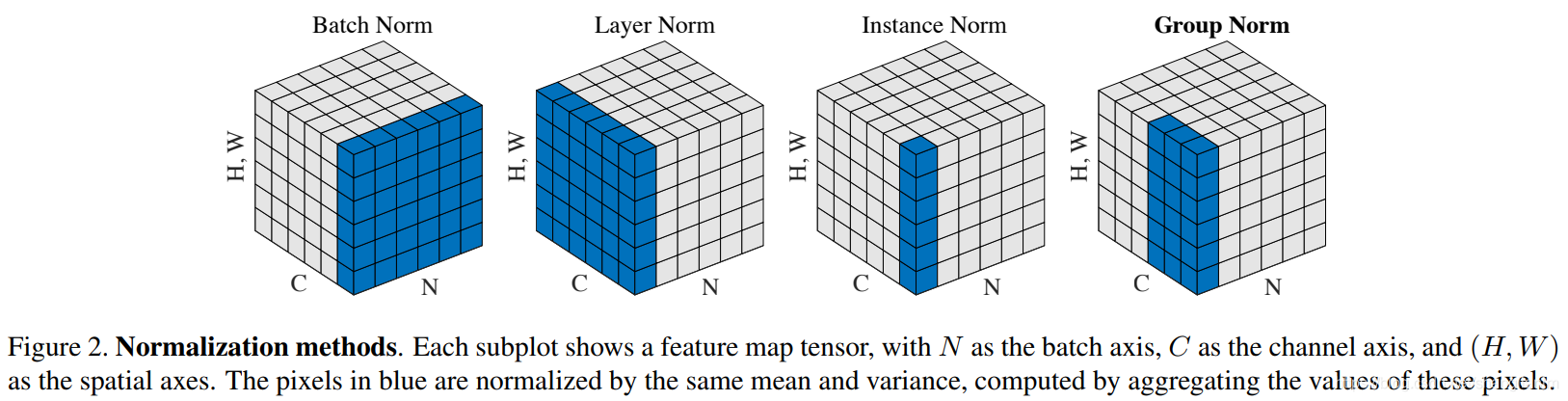
BN,LN,IN,GN从学术化上解释差异:
- BatchNorm:batch方向做归一化,算NHW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布
- LayerNorm:channel方向做归一化,算CHW的均值,主要对RNN作用明显;
- InstanceNorm:一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
- GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束。
- SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。

torch.nn.LayerNorm(normalized_shape: Union[int, List[int], torch.Size],eps: float = 1e-05,elementwise_affine: bool = True)
normalized_shape: 想要进行归一化的形状,若输入为整数,则必须与tensor最后一个维度大小相等;若输入为形状,则会在给定形状上计算均值与方差,并进行归一化
ensor = torch.FloatTensor([[1, 2, 4, 1],[6, 3, 2, 4],[2, 4, 6, 1]])
此时
 ,
, (有偏样本方差),归一化后的值如下,举例说明:第0行第2列的数字4,减去第0行的均值2.0等于2,然后除以
(有偏样本方差),归一化后的值如下,举例说明:第0行第2列的数字4,减去第0行的均值2.0等于2,然后除以 即2/1.224749≈1.6330。
即2/1.224749≈1.6330。[[-0.8165, 0.0000, 1.6330, -0.8165],[ 1.5213, -0.5071, -1.1832, 0.1690],[-0.6509, 0.3906, 1.4321, -1.1717]]
eps: 防止除0为分母加上的值
- elementwise_affine: 如果设为False,则LayerNorm层不含有任何可学习参数。否则包含
 这两个可学习参数
这两个可学习参数
参考:https://blog.csdn.net/weixin_39228381/article/details/107939602

若有收获,就点个赞吧
0 人点赞
