从一元到多元
用矩阵描述多个特征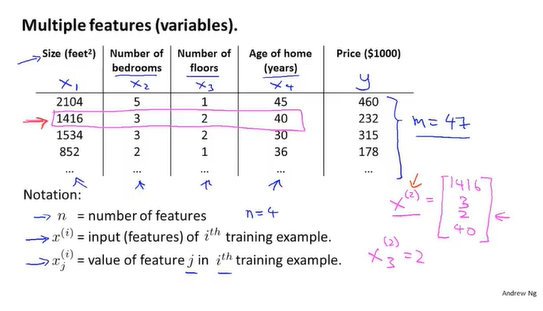
回归函数可转为行向量与列向量相乘的形式
代价函数转为矩阵的形式表达
使用梯度下降时一元与多元求偏导时的异同 其中xi表示第i个样本值,相当于对每一个样本项求偏导,很容易推出
特征缩放
作用:确保这些特征在一个相近的范围之内,这样梯度下降算法能够更快地收敛。想象一下使代价函数的等高线更接近圆
- 比例缩放
尽可能地使特征值局限在一个尽可能小的范围内,从而避免梯度下降步长过大拖慢效率
如图,特征值范围过大可能会使梯度下降路线变得曲折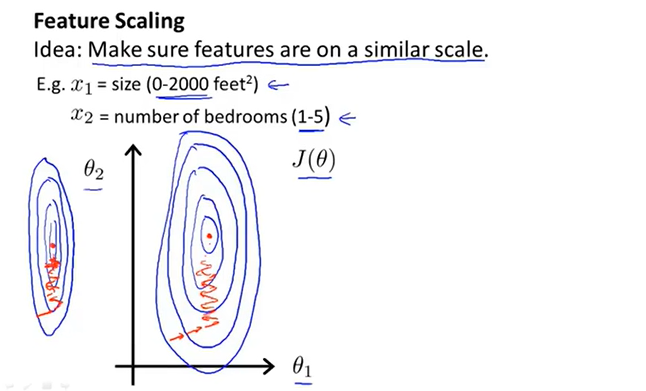
进行特征缩放后,路线与凸函数形状变得正常许多,收敛会更快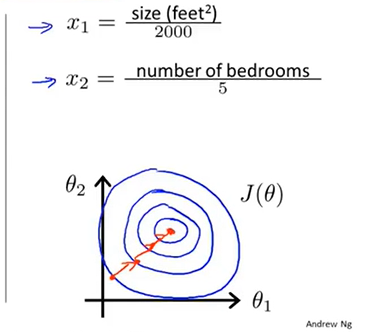
特征缩放的目标是使每一个特征值的范围都大致与[-1,1]近似
- 均值归一化
以x减去均值除以标准差代替x,以达到缩放的目的
学习率
确保梯度下降算法运转正常。若运转正常,则每一次梯度下降将所得参数 代入代价函数所得的值都应该降低直至为0。图中所示,迭代经过一定轮数后曲线趋于平缓,不再下降,已经趋于收敛。
代入代价函数所得的值都应该降低直至为0。图中所示,迭代经过一定轮数后曲线趋于平缓,不再下降,已经趋于收敛。
根据代价函数值与迭代次数关联的函数图像,可以基本评估梯度下降的效率,确定是否收敛,以及是否遇到问题(若代价函数值不降反升,可能由学习率过大导致)。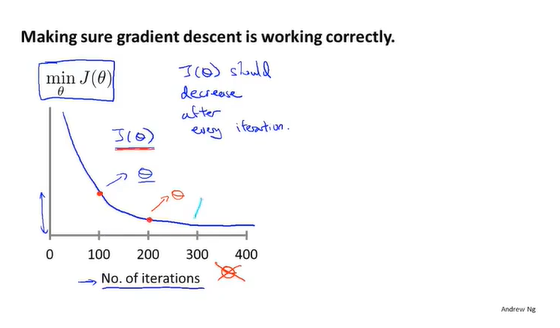
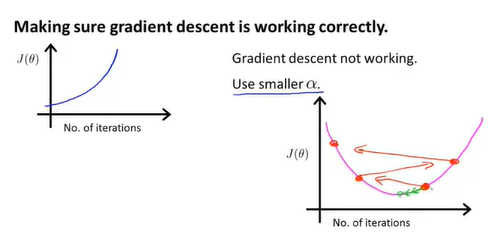
相似地,也可以通过阈值的方法评估是否已经收敛。但阈值的确定比较困难,因此函数图像的方法更好。
多项式回归
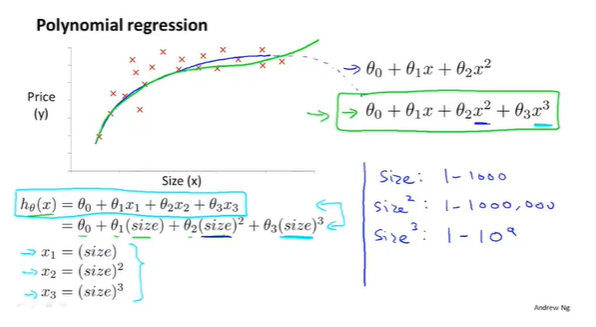
多项式回归其实与多元回归有相似之处,将每项作为新的特征值即可。但是要注意特征缩放的问题。不同次数的项收敛和增长速度有很大区别。
正规方程
可直接通过代价函数算出最小值,只需将所有偏导置零,随后解方程组即可。
根据线性代数的知识,可以直接通过下式求出最小值。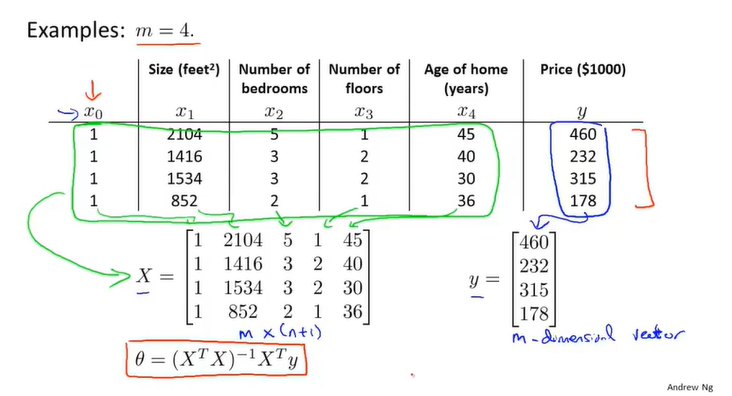
| 梯度下降法 | 正规方程法 |
|---|---|
| 需要学习率 | 不需要设定其他参数,直接求解 |
| 需要多次迭代,适用于各种模型 | 需要计算(XTX)-1,只能用于线性模型 如果特征数量n大则运算代价大,n≤1000 大概O(n)=n^3 |
| n>>10000 | n<10000 |

若有收获,就点个赞吧
0 人点赞
