图谱补全
知识图谱的普遍特征:海量、不全(很多边是缺失的)
- 但对于一个大型KG而言,枚举所有可能的联系几乎是不可能的
- 我们能否找到一个方法来预测缺失的边?
可以借助联系以及联系的类型进行对缺失联系的预测
- KG中的边表现为三元组(h,r,t)的形式,即head/relation/tail
- 实体与关系都转化成嵌入向量的形式
- 给定一个三元组(h,r,t),优化的目标是(h,r)的嵌入向量尽可能靠近t的嵌入向量。那么如何获得(h,r)的嵌入向量,以及如何定义距离?
- 关系模式:
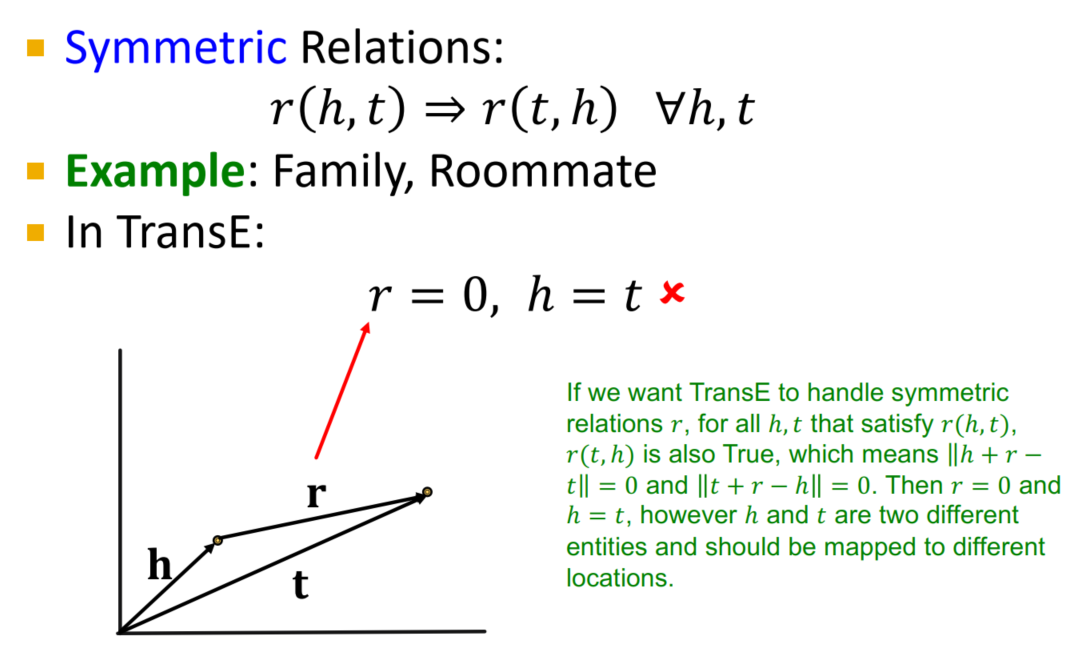
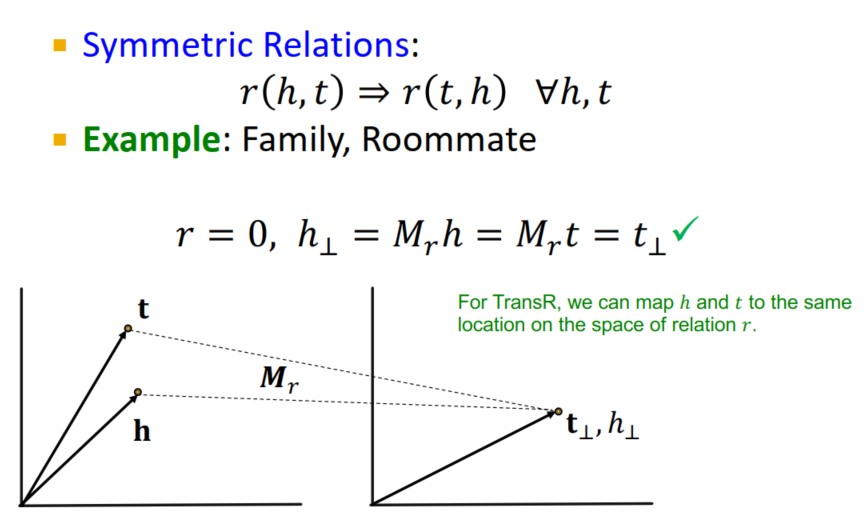
- 对称关系:

- 推导关系:

- 一对多、多对一关系:
 均为真
均为真
- 对称关系:
- TransE 算法:
- 设训练集
 为三元组的集合,实体集合为
为三元组的集合,实体集合为 ,关系集合为
,关系集合为 ,边缘记作
,边缘记作 (有效元组与无效元组所能容忍相距的最小距离),嵌入向量维度为k
(有效元组与无效元组所能容忍相距的最小距离),嵌入向量维度为k - 对所有关系集合中的关系
 ,将其正态初始化,并将它归一化;对所有实体集合中的实体e,也将其正态初始化
,将其正态初始化,并将它归一化;对所有实体集合中的实体e,也将其正态初始化 - 开始循环:进行小批量训练。对于每个batch中的三元组,我们进行一次负采样(负采样得到的结果不在原知识图谱中出现)
- 通过损失函数进行训练,普通样本对于优化是正向的结果,相反负采样得到的结果是反向的结果:
- 设训练集

- 计算完一轮之后继续训练,直到遍历完训练集为止

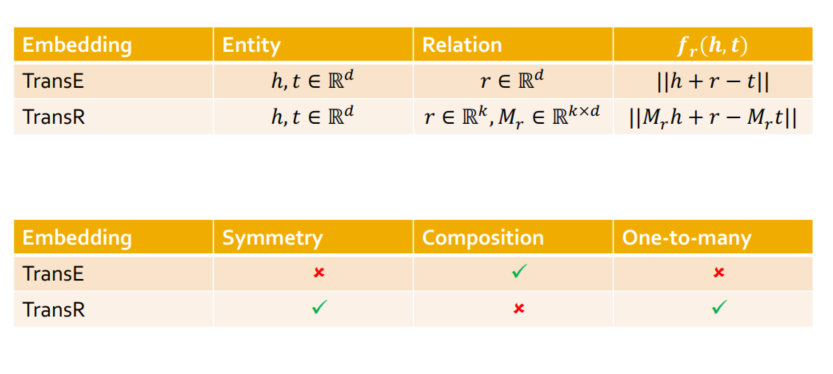
- TransE
- 对一个三元组(h,r,t)而言,理想状态下h+r=t,我们可以定义一个得分函数
 ,得分越小越精确,
,得分越小越精确,
- 更像是一个正则化范数。一旦有效三元组与无效三元组之间的距离大于该值,那么训练就应停止
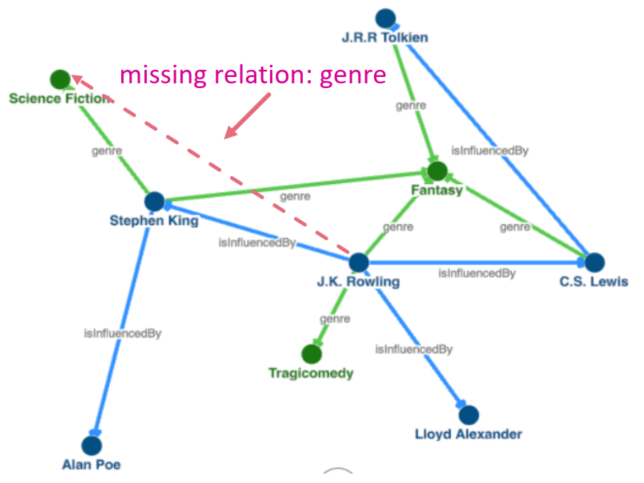
- 关系预测。比如若图灵奖实体指向了某一范围中的实体,那么我们就可以将所有该范围内的实体与图灵奖实体建立联系。
- 对一个三元组(h,r,t)而言,理想状态下h+r=t,我们可以定义一个得分函数
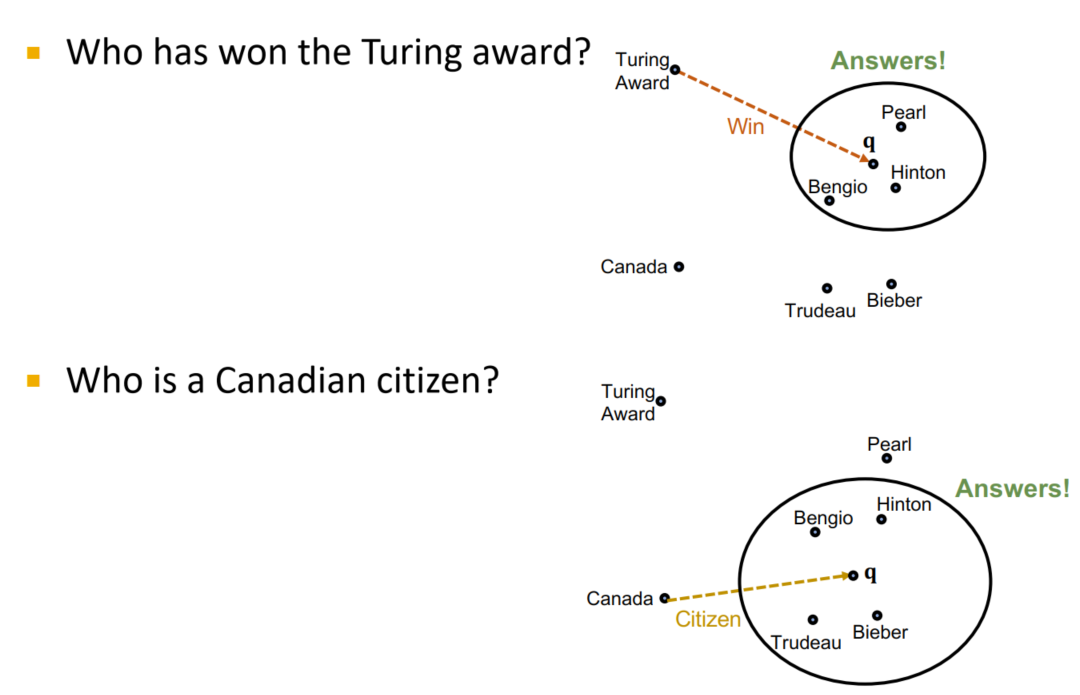
- TransE支持推理机制
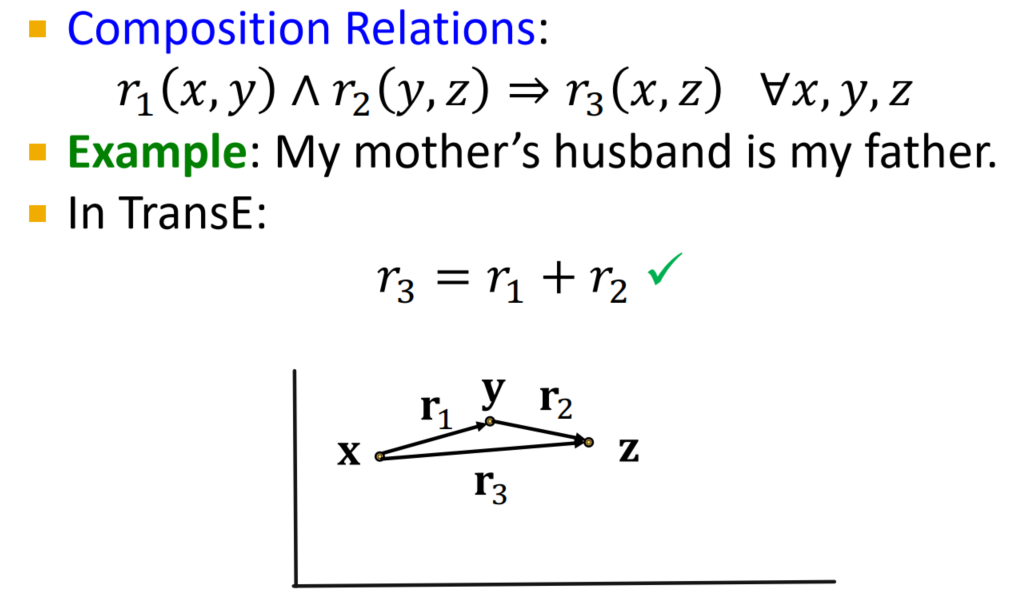
- 局限性:对称性,实体关系多重性均无法表示(若一个实体与多个实体都有着同种类型的关系,那么TransE的推理最终只能指向一个实体)

- TransR:实体的嵌入向量存储在D维实体空间内,而关系的嵌入向量存储在k维关系空间中。
 即映射矩阵
即映射矩阵

- 支持对称性,实体关系多重性的表示

- 所以,两种算法各有各的好处:
Path Queries
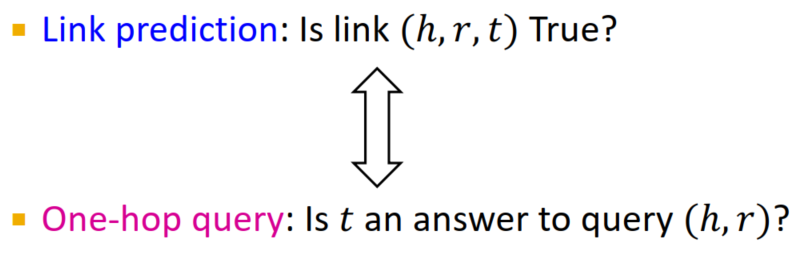
- 路径问答:在一个规模巨大但不全的图谱上如何高效进行多跳推理?
- 实际上,关系预测的工作就是一种单跳的问答
- 通过在链路上增加更多的关系,我们可以将单跳的问句泛化为问句链。问句链q可表示为

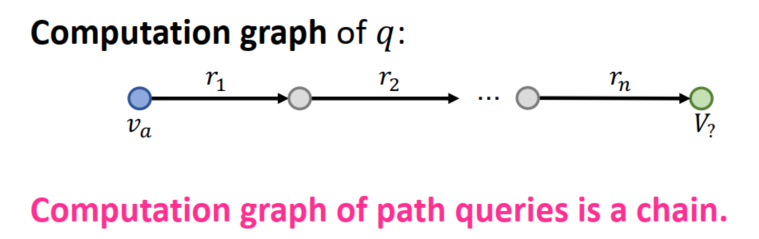
- 对于一个完整的图谱,答案可以由遍历KG获得:
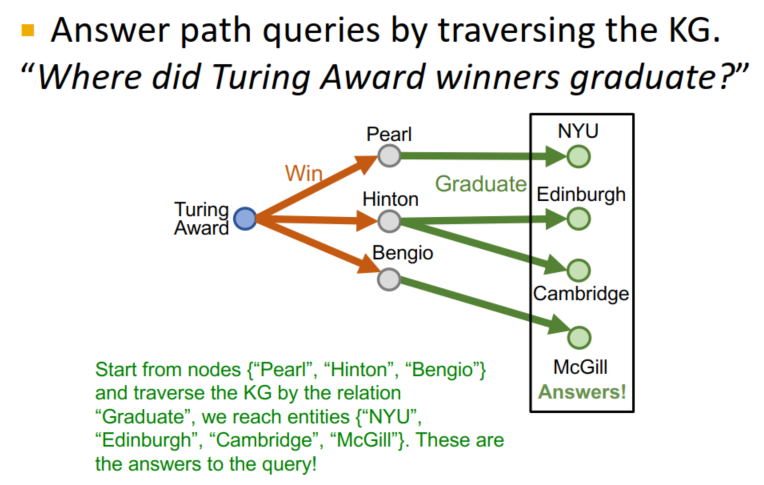
- 那么如何在未补全的图谱上实现推理?
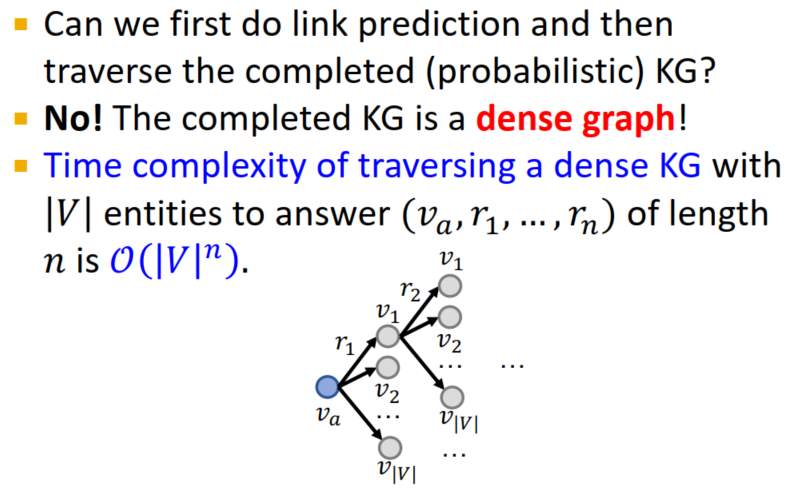
- 能否先对图谱进行补全然后对图谱进行遍历?不行!因为这是一个稠密图,这样做会是指数级的复杂度。
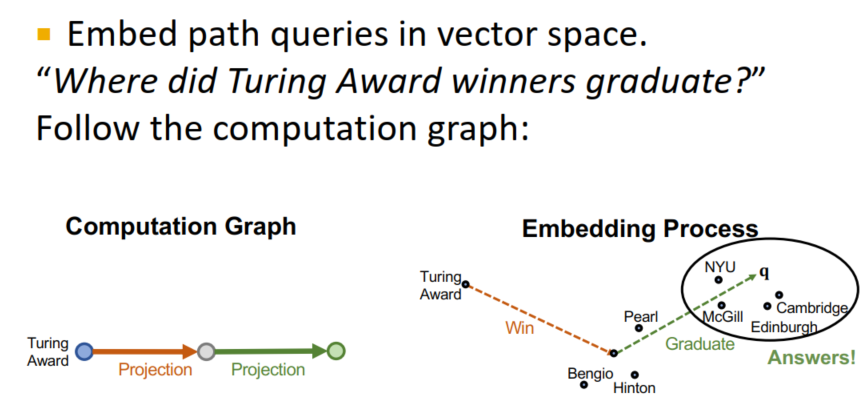
- 嵌入向量再一次发挥了重要作用,只要将链路中所有向量相加即可!这直接将时间复杂度降低到了O(V)!随后我们只要在最终得到的结果附近寻找所有的邻居实体即可得到答案。天才
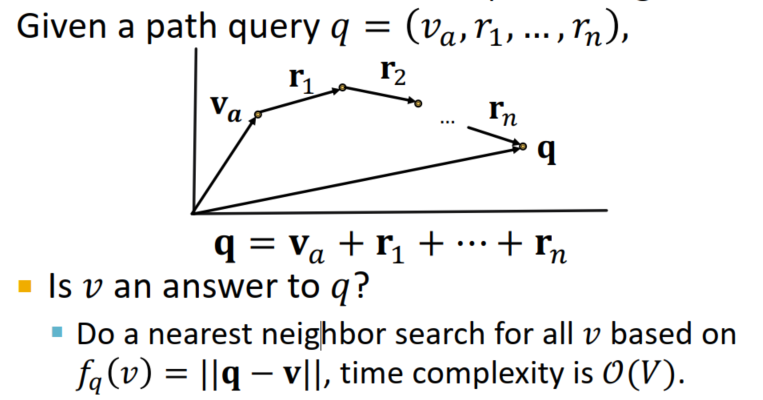
Conjunctive Queries
- 联合查询:从多个实体开始进行联合推理,这比之前更复杂
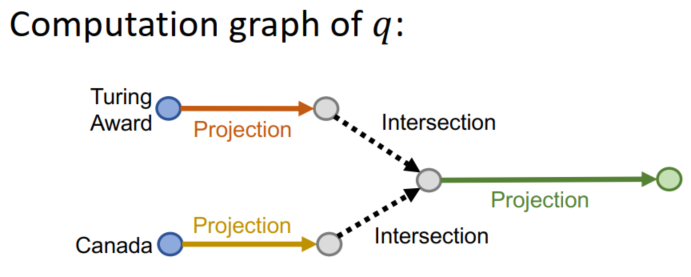
- 通过遍历的方式就是在前面的操作上加入了取交集的操作,很耗时
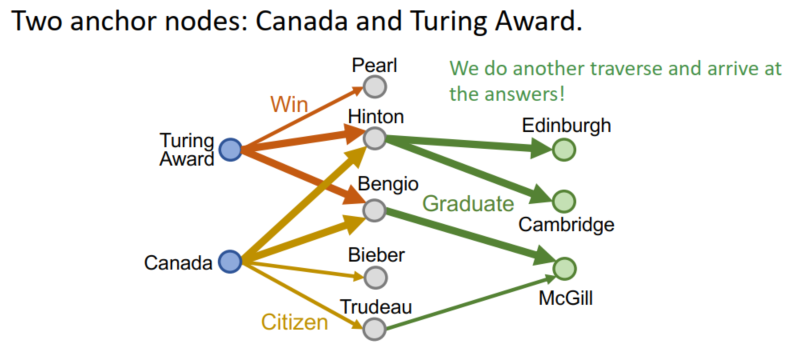
- 在向量空间上如何取交集?
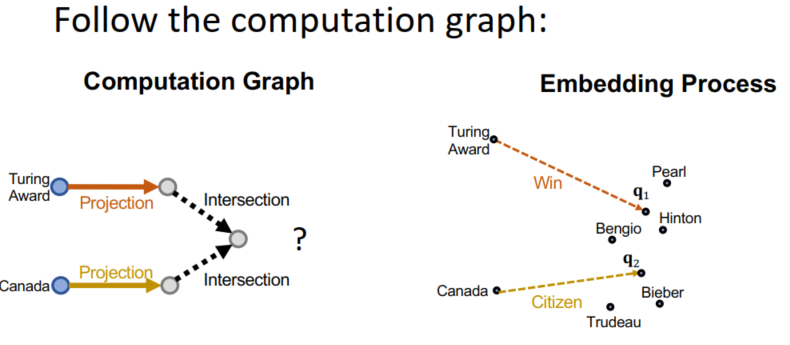
- 这时候就需要借助于神经网络了:
- 网络的输入是目前问句涉及实体的嵌入向量q1,…,1m;网络的输出是一个取过交集的嵌入向量q
- 函数应该是序列位置无关的

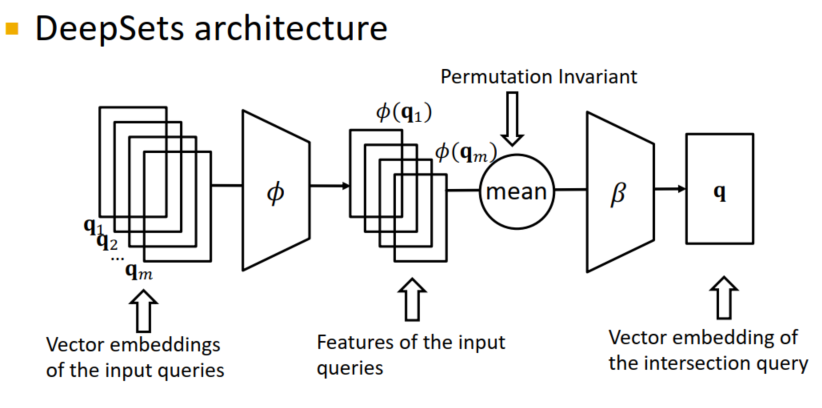
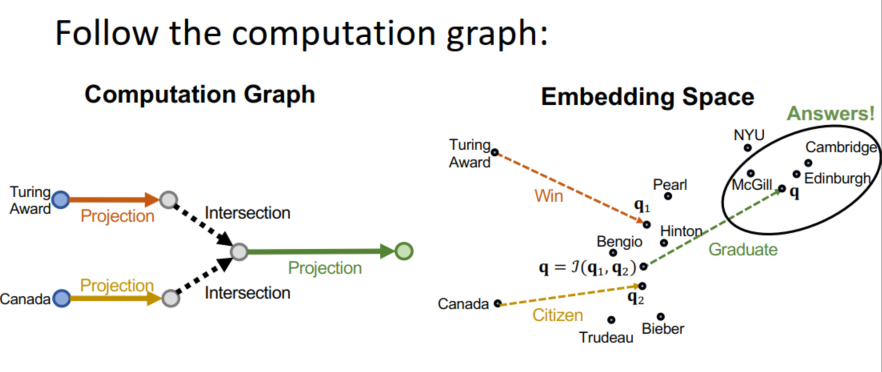
- 训练过程:该网络可以与TransE一同学习


Query2Box:使用盒嵌入进行推理
- Jure组最新的研究成果 有兴趣可以细看

若有收获,就点个赞吧
0 人点赞
