引言
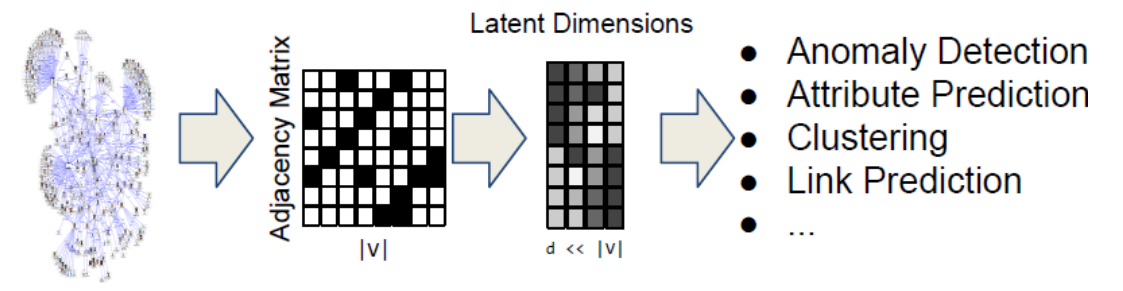
我们都知道机器学习需要经历数据规范化、参数学习再到得出最终模型的过程,而往往将原始数据规范化为结构化数据是最费力的工作。那么图表示学习的目的就是将这一工作自动化完成。
- 就是将每个结点使用一个向量进行表示
为何使用图嵌入?
- 它为所有结点提供了离散的表示方式
- 结点嵌入向量之间的相似度也表示了它们的在网络中的相似度
- 将网络信息进行编码并生成结点的表示方法
- 图嵌入向量可以捕捉到一些潜在的维度,比如某个维度可能代表了motif的从属关系,结点的度等等
- 为何它非常难?
- 拓扑结构非常复杂
- 结点之间不存在序列关系
- 图是动态的,且可能具有多模态特征
结点嵌入
起步:给定一个图G,它包含一个结点集及一个邻接矩阵,它用不到任何其他的结点特征以及额外的信息
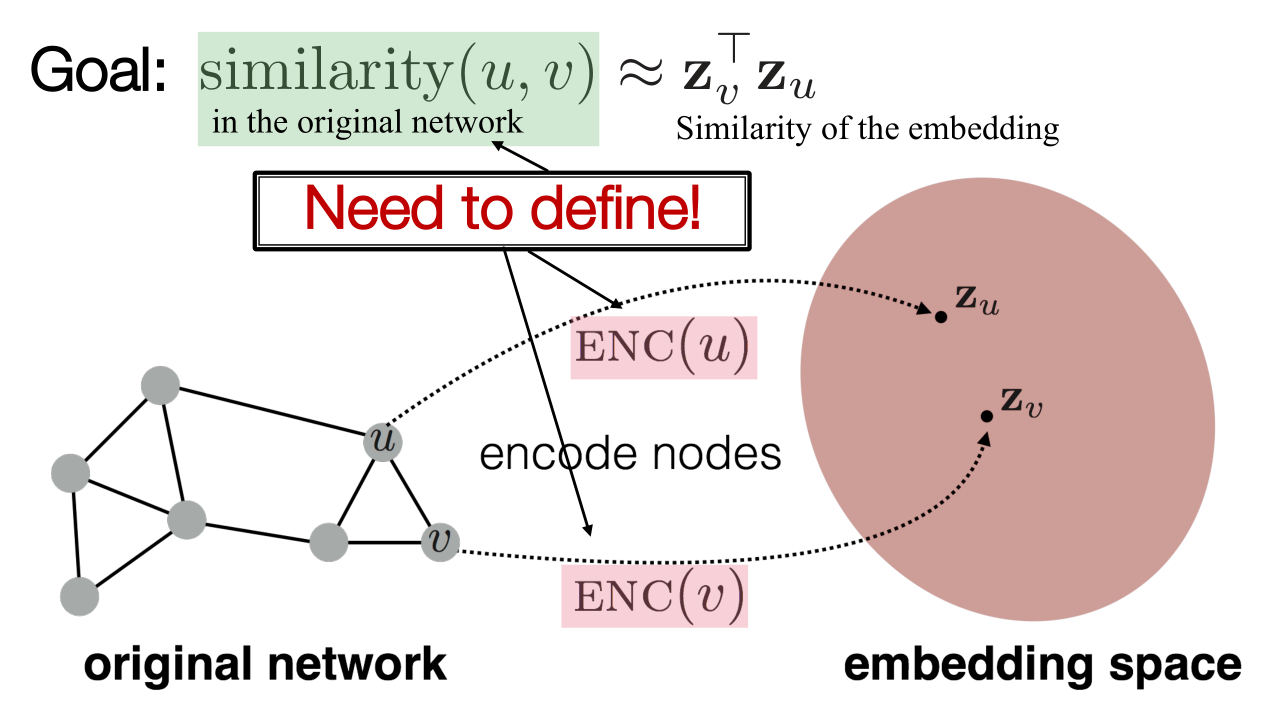
目标:将结点信息进行编码,从而嵌入空间能大致表示原始网络中的相似关系
- 我们还需要先定义衡量相似度的标准
- 所以,首先我们应该定义一个编码器(将结点转化为嵌入向量),然后定义一个计算相似度的函数(在原网络中),最后将参数进行调优,使它无限逼近在原网络中的相似度。

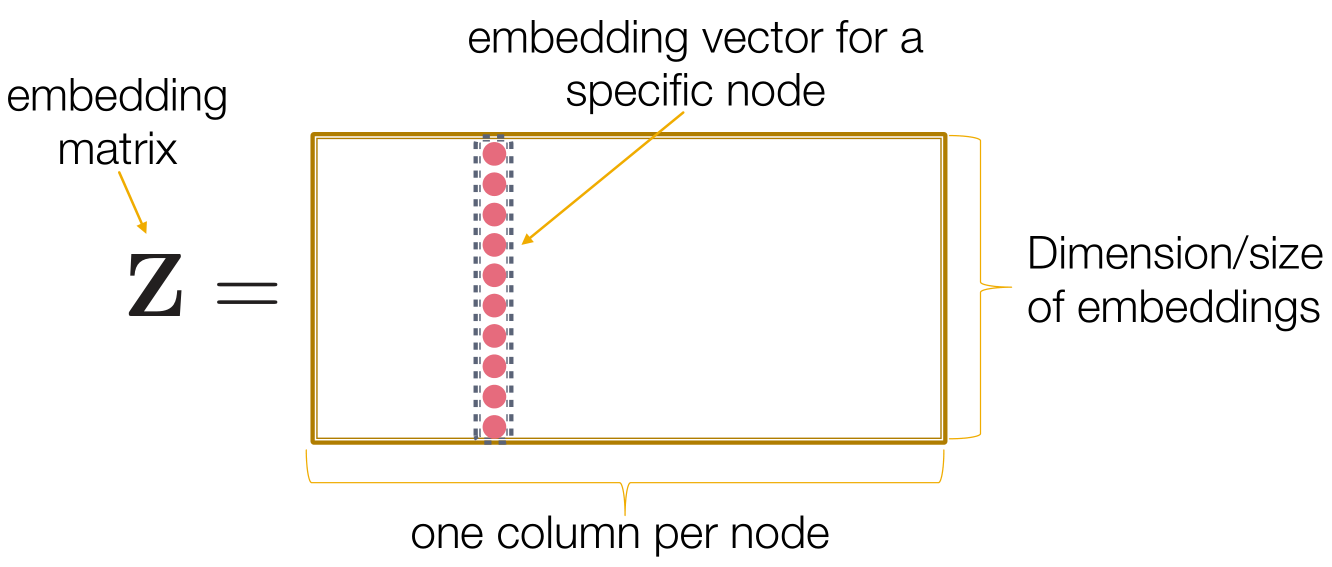
- “浅层”编码:最简单的编码策略,编码器只承担查找的任务,类似哈希表。其实就是把所有嵌入向量拼接起来的嵌入矩阵,需要向量时乘上对应的one hot向量即可。
- DeepWalk、node2vec、TransE都是采用的此类方法
- 最核心的问题就是如何定义结点之间的相似度?两个向量应该在什么情况下被认为是相似的?
- 连通的时候?
- 具有共同邻居的时候?
- 担任共同角色的时候?
随机游走
- 何谓随机游走?就是给定一个图和一个起始点,我们可以随机选择它的一个邻居,然后移动至这个结点上,随后再重复此过程。
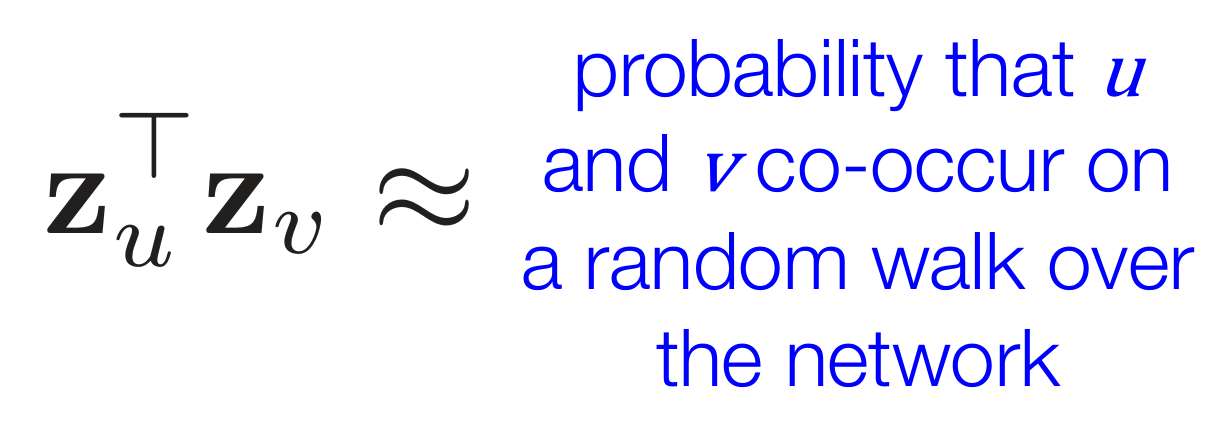
- 实际上,通过随机游走算法求得的两个图嵌入向量
 之积就等于u和v同时出现在一次随机游走的概率大小
之积就等于u和v同时出现在一次随机游走的概率大小 - 在随机游走中,需要计算从结点u开始能到达结点v的条件概率,记为

- 根据随机游走取得的数据对嵌入向量进行优化。比如若两点在网络中相似度很高,那么它们的内积应尽可能趋近于1,余弦相似度尽可能高,夹角尽可能小
- 实际上,通过随机游走算法求得的两个图嵌入向量
为何使用随机游走?
- 表现力:同时表现了结点及高阶邻居的特征信息
- 效率:只需要考虑在随机游走中共现的结点
问题转化
- 给定图
 ,设
,设 为结点u通过随机游走R获得的邻居集合
为结点u通过随机游走R获得的邻居集合 - 我们的目标是学习获得一个映射

- 待优化问题其实就是如何最大化
 ,为随机游走实验中获得的邻居集合,那么理想状况下
,为随机游走实验中获得的邻居集合,那么理想状况下 应等于1,所以我们应该调整嵌入矩阵z,使整个图范围内的概率都趋近于1(这也是为什么使用log,这样所有概率的积就转化为了和的形式)
应等于1,所以我们应该调整嵌入矩阵z,使整个图范围内的概率都趋近于1(这也是为什么使用log,这样所有概率的积就转化为了和的形式) - 对于结点u,我们需要学习在随机游走中共现的邻居的嵌入向量
- 给定图
学习过程
- 首先在图中进行固定长度的随机游走
- 对于每个结点收集集合,即结点u通过随机游走R获得的邻居集合(是一个多重集合,因为可能游走多次)
- 给定u,预测,再与实际收集到的进行比较。实际上就是:

- 优化方法
- 损失函数:
 ,其实就是概率越趋近于1,函数值越小
,其实就是概率越趋近于1,函数值越小 - 将
 参数化:
参数化: , 我们希望这个概率尽可能大,因为分子是从结点u开始能到达结点v的条件概率,而分母是从结点u到达所有其他结点的概率之和(理想情况下为1)。所以在这里我们使用softmax的原因就是我们希望结点v是在所有n个结点中与结点u最相似的结点,而且恰巧
, 我们希望这个概率尽可能大,因为分子是从结点u开始能到达结点v的条件概率,而分母是从结点u到达所有其他结点的概率之和(理想情况下为1)。所以在这里我们使用softmax的原因就是我们希望结点v是在所有n个结点中与结点u最相似的结点,而且恰巧 ,所以这样效果更显著。
,所以这样效果更显著。 - 然而通过这种方法计算相当耗时,而计算时间主要花在
 上
上
- 损失函数:
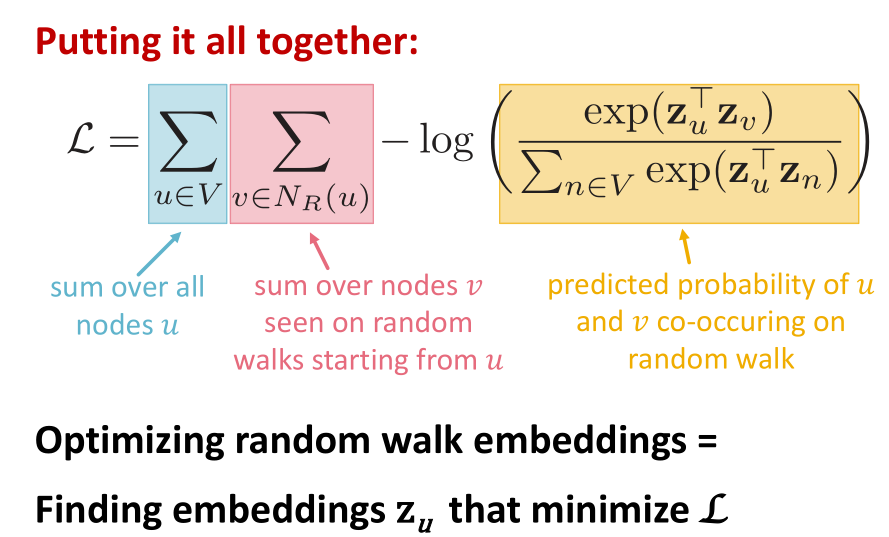
- 负采样
- 为了加快速度而生,核心思想是不需要对整个数据集进行采样,取而代之的是只正态抽取一小部分进行采样。
- 不用再去对所有结点进行归一化,而是只去归一化k个随机的“负样本”
- 根据度按比例取样k个负结点

node2vec概览
- deepwalk的一个很大的问题是只要两个结点在图中相距足够远,即使它们处在两个相似的聚类中,它们的余弦相似度仍然很低,node2vec解决了这一问题
- 网络邻居可以有着丰富的结点嵌入表示。node2vec提出了第二种带偏随机游走方法来寻找u的邻居
- 正是出自CS224W的团队
带偏随机游走
- 最大的特点在于可以在对网络的本地视角与全局视角之间做出权衡。显然BFS的游走方式更偏向于本地视角,而DFS的游走方式更能捕捉到全局信息
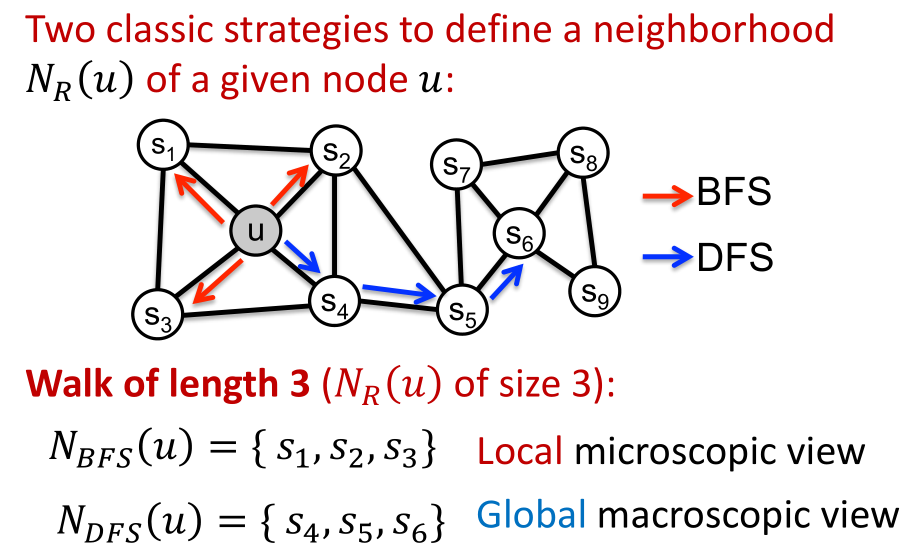
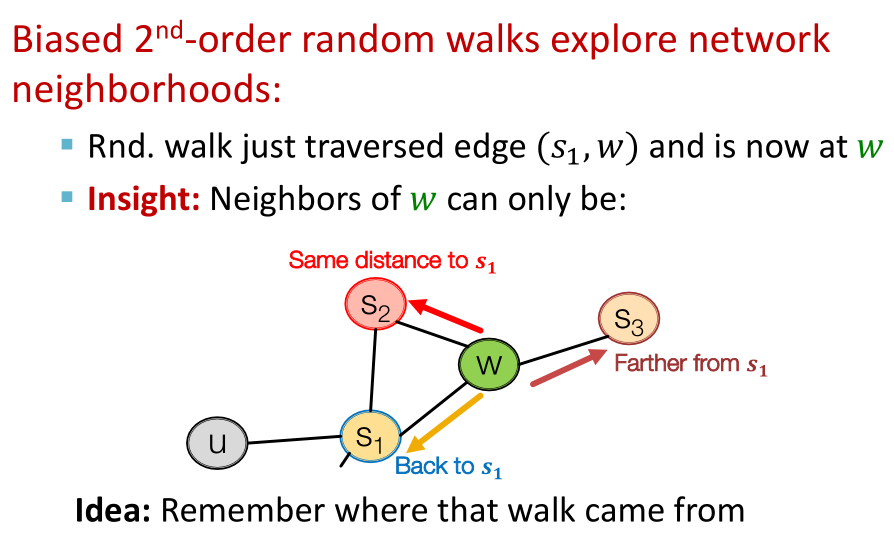
- 为了实现带偏随机游走,我们需要引入两个参数:返回参数p(在游走时返回上一个结点)、进出参数q(可控制到底是进行DFS还是BFS,是一个“比例”)
- 至于为什么带偏随机游走是“2nd”的,这是因为对于走过的每一个结点,它都有一个返回的概率。
- 到达结点w后,再往哪走是一个概率问题,要注意这里的几个概率取值都是未归一化的,使用时需要先归一化。如果我们设定的p值较小,那么我们就可以进行近似BFS的游走,如果我们设定的q值较小,那么就可以进行近似DFS的游走。
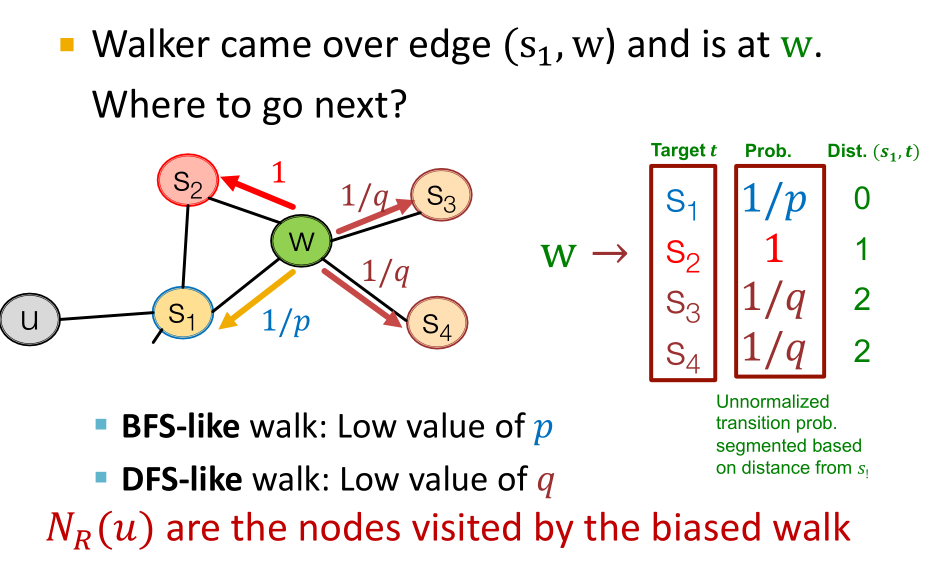
node2vec算法:
- 首先计算随机游走的概率
- 从每个结点u开始模拟长为l的随机游走
- 使用SGD进行优化
词嵌入的用途:

为多联系数据生成嵌入(Trans-E)
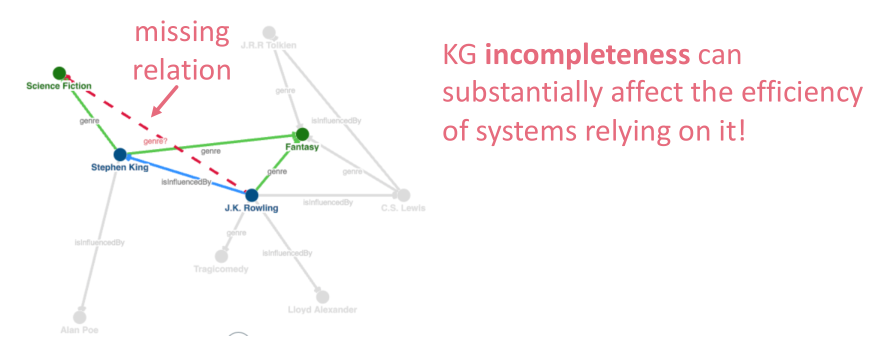
- 知识图谱的补全一直是KG的最大问题,实体之间丢失的联系往往可能造成性能的严重损失。所以我们需要找到一个对实体之间的关系进行预测的方法,而且最好还要对关系的类型进行预测



若有收获,就点个赞吧
0 人点赞
