信息熵
- 信息是对不确定性的消除。一个事件的不确定性越大,其所含的信息量就越多
- 比方说有两个事件,其一是冬天下大雪,其二是夏天下大雪。显然冬天下雪的概率更大,那么它所包含的信息量就更多。
- 引入函数
 来衡量信息量的多少,它具有如下性质:
来衡量信息量的多少,它具有如下性质:- 概率越大的事件,信息量越少
- 概率为1的事件信息量为0
- 概率为0的事件信息量为1
- 对于两个互相独立的事件,它们同时出现的信息量等于两者信息量的算术和
- 为满足以上定义,

- 信息熵用于衡量一个随机系统的总体信息量,那么就可以对系统中每一个事件的信息量求统计平均(期望)

- 假如用一个离散随机变量
 进行建模,则
进行建模,则
- 信息熵具有如下性质,这也决定了以上定义是唯一的
- 连续性
- 等概率时单调性:随机系统等概率分布时,随着集合中元素增加,信息熵单调增加
- 可加性:随机系统的信息熵等于系统中一部分的信息熵加上另一部分的信息熵
另外几条有趣的性质
设观察分布为
 ,预测分布为
,预测分布为 ,则
,则
KL散度实际上就是交叉熵减去信息熵。

生成模型的目的是为了求解数据与隐变量间的联合密度。
 ,此时生成过程变为先验分布
,此时生成过程变为先验分布 生成
生成 ,先验分布
,先验分布 再生成
再生成
- 问题是我们不知道
 的值,其中也有很多过程对我们不可见
的值,其中也有很多过程对我们不可见 - 两个主要难点:
- 边际似然函数积分
 难以计算。没有办法估计边际似然分布,因为其中后验分布
难以计算。没有办法估计边际似然分布,因为其中后验分布 不可知,否则直接使用EM算法来做就可以了
不可知,否则直接使用EM算法来做就可以了 - 数据集很大,直接用蒙特卡洛做会有较大的方差
- 边际似然函数积分

 ,使用近似分布
,使用近似分布 来观测分布
来观测分布 消耗的信息量一定大于
消耗的信息量一定大于 的总体信息量
的总体信息量

- 三个待解决问题
- 高效逼近ML或MAP
- 高效逼近隐变量z的后验推断
- 高效逼近x的先验推断
论文引入一个生成模型 来逼近真正的后验分布
来逼近真正的后验分布 ,其中
,其中 就是编码器,
就是编码器, 就是解码器
就是解码器
变分下限
再次引入EM算法中的似然函数
提取变分下限(EM算法推演也可以这样来做,比Jensen不等式更直观):


由于KL散度始终大于0,因此:
这项 也被称作为ELBO(evidence lower bound)
也被称作为ELBO(evidence lower bound)
回顾一下之前的EM算法,它的本质是什么呢?它直接让这项KL-Divergence取0,接着优化ELBO,这样的话就可以保证似然函数估计一定会上升
但是,EM算法要计算KL-Divergence取0的前提条件,需要 ,然而它在该场景中是不可观测的,我们需要使用别的方法来使似然函数likelihood上升。
,然而它在该场景中是不可观测的,我们需要使用别的方法来使似然函数likelihood上升。
所以找到下限后,需要做的是同时优化 ,找到一个
,找到一个 来使似然函数取得最大值。
来使似然函数取得最大值。
为什么要优化 呢?
呢?
首先, ,这是永远不会变的。现在我们力图最大化
,这是永远不会变的。现在我们力图最大化
假如只优化 ,那么
,那么 是不会变的,因为q和p一点关系都没有。所以,通过优化
是不会变的,因为q和p一点关系都没有。所以,通过优化 提高ELBO等同于减小KL-Divergence。到最后
提高ELBO等同于减小KL-Divergence。到最后 与
与 的分布会完全一致。
的分布会完全一致。
假如只优化 ,那么会出现一个问题,我们让
,那么会出现一个问题,我们让 上升的时候,并不一定会让
上升的时候,并不一定会让 也跟着上升(因为此时没有
也跟着上升(因为此时没有 的约束)
的约束)
所以,同时优化 可以使KL-Divergence尽量小的同时最大化
可以使KL-Divergence尽量小的同时最大化 ,最后达到最大化
,最后达到最大化 的目的。
的目的。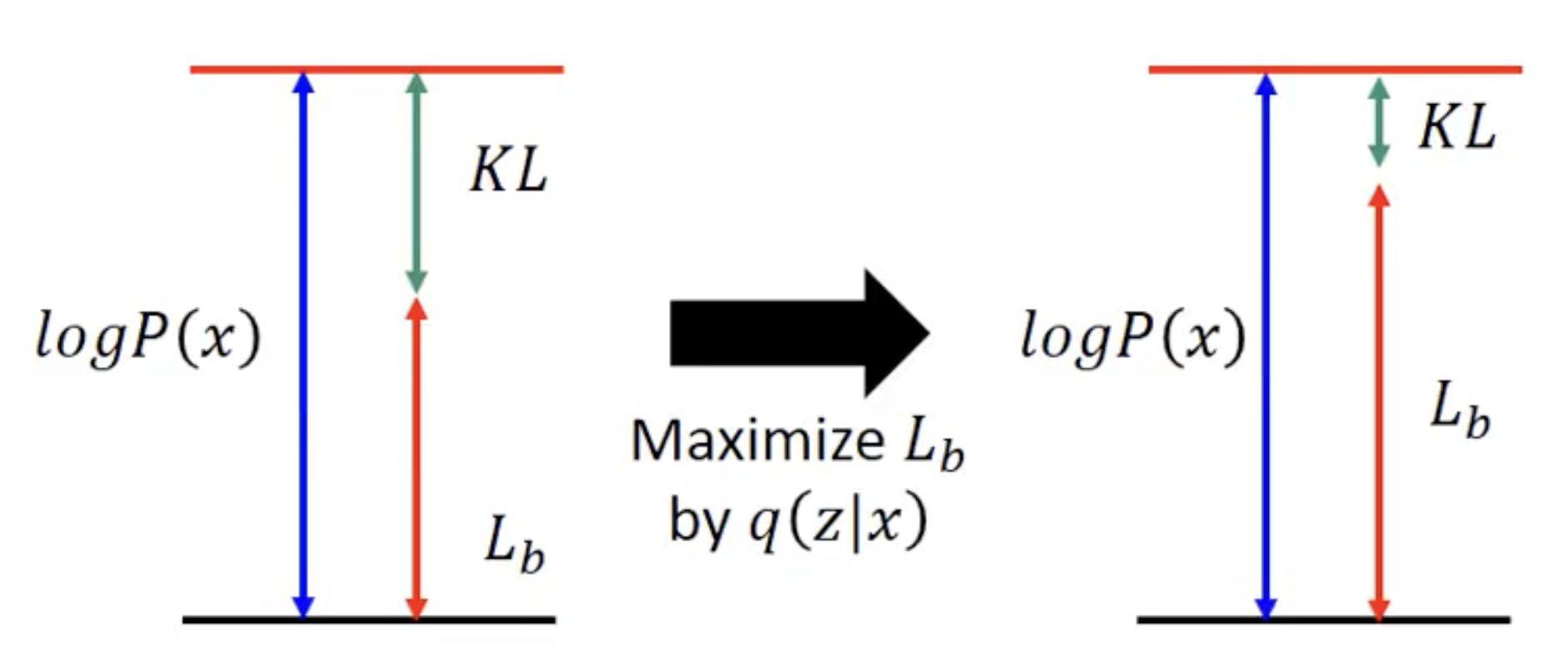


 ,从而使
,从而使 最大化
最大化
Reprameterization Trick
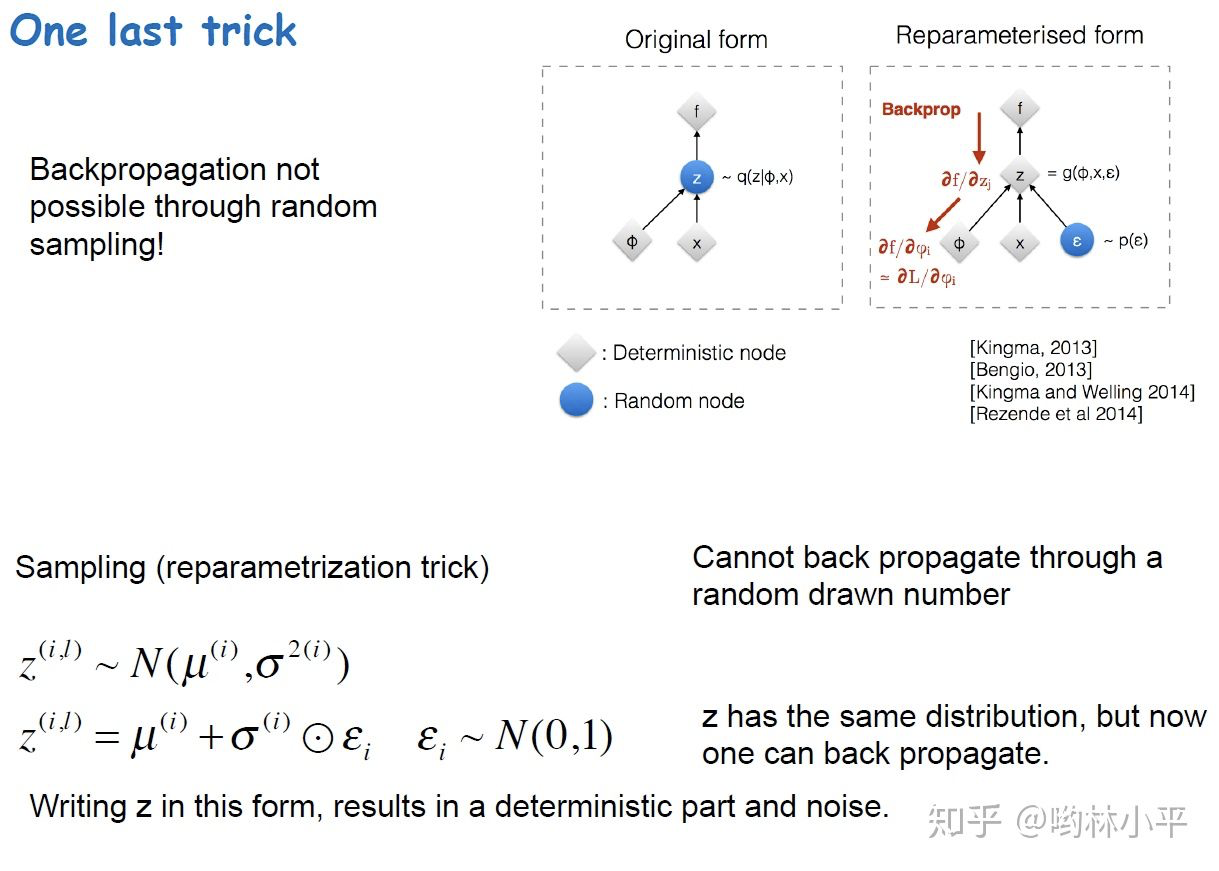
在优化的时候会有一个问题,那就是我们需要从 进行采样。
进行采样。 都是概率,进行采样是一个随机的过程,该操作不可导。所以需要引入一个trick,那就是引入神经网络来模拟采样的过程。
都是概率,进行采样是一个随机的过程,该操作不可导。所以需要引入一个trick,那就是引入神经网络来模拟采样的过程。
设现有x,想要得到的是隐变量z,其中z从 中采样得到。
中采样得到。
接着引入变量 ,
, ,此时z可由x与
,此时z可由x与 推得(如图右侧所示)。这样把随机过程交给
推得(如图右侧所示)。这样把随机过程交给 后,z就不是一个random node,可以进行反向传播。
后,z就不是一个random node,可以进行反向传播。
如何引入神经网络来进行这一过程呢?设 服从正态分布,我们可以让它生成正态分布参数均值及标准差
服从正态分布,我们可以让它生成正态分布参数均值及标准差 。进而
。进而 。由此我们就模拟了从正态分布中采样的过程。
。由此我们就模拟了从正态分布中采样的过程。
SGVB&AEVB
了解了重参数化的动机后,具体来看如何优化
设有函数 ,
, 。
。 ,在进行重参数化后,可得
,在进行重参数化后,可得
假设现有函数 ,我们想要计算它的期望,则可做如下近似估计:
,我们想要计算它的期望,则可做如下近似估计:
之前我们把 拆成了
拆成了 ,我们来关注第一项。仔细想一下,该项实际上就等同于在
,我们来关注第一项。仔细想一下,该项实际上就等同于在 概率分布上求
概率分布上求 的期望。
的期望。
因此:
其中 ,
,
随后就可以使用SGD进行优化了。

Variational Auto Encoder
encoder与decoder其实就是 ,然后就很容易理解了
,然后就很容易理解了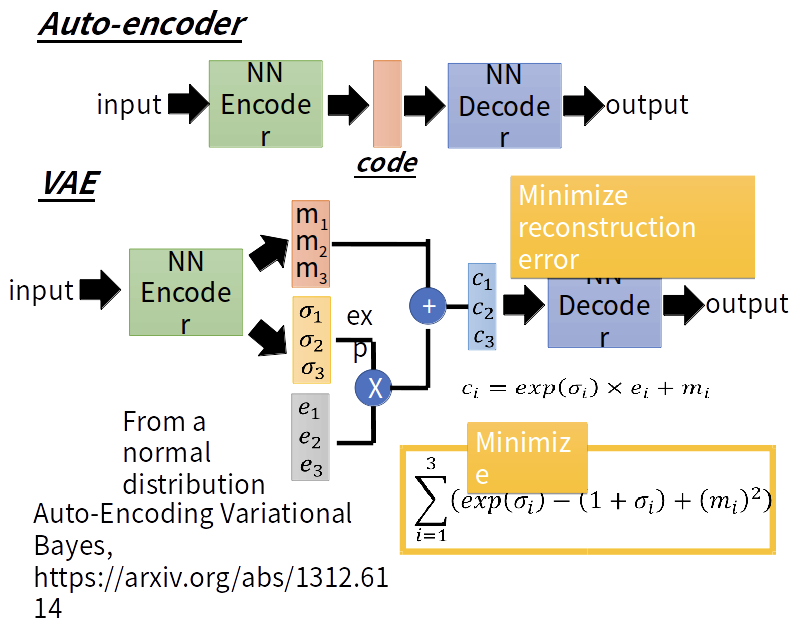
 这一项化简后,可以推出一个正则化项,具体步骤见原文。以此来作为优化时损失函数的约束。
这一项化简后,可以推出一个正则化项,具体步骤见原文。以此来作为优化时损失函数的约束。

若有收获,就点个赞吧
0 人点赞
