OVERVIEW
GAN在生成真实图片的已经取得了很大的成功,但在应用于文本生成领域仍然有很多挑战。在这个工作中,作者提出了一个新的GAN结构——RelGAN用于文本生成,在生成的文本的质量和多样性方面皆优于现有方法。模型主要由3个部分组成:
- a relational memory based generator ——便于长期依赖建模
- Gumbel-Softmax relaxation ——为了能够处理用离散数据训练GAN
- multiple embedded representations in the discriminator——为生成器更新提供更多的信息信号
WHY?
- 目前基于强化学习训练的GAN普遍存在一些问题。首先,它们的性能对随机参数初始化和超参数选择相当敏感。此外,许多GANs大量采用RL启发式方法,如蒙特卡洛搜索和层次RL,使已经很难训练的GANs更加复杂,因此对抗性训练的个别作用不明确。
- 第二个问题是模式单一化,因为生成的文本句子往往不那么多样化,而且在生成长句子时,模式单一化会变得更加严重。可能是由于生成器缺乏表达能力(因为它可能无法覆盖数据分布中许多更复杂的模式),或者是由于鉴别器中信息量较少的指导信号(因为它可能将生成器的更新限制在某些模式内)造成的。
当前的生成器模型普遍采用的是LSTM,但它实际上是GAN的瓶颈。
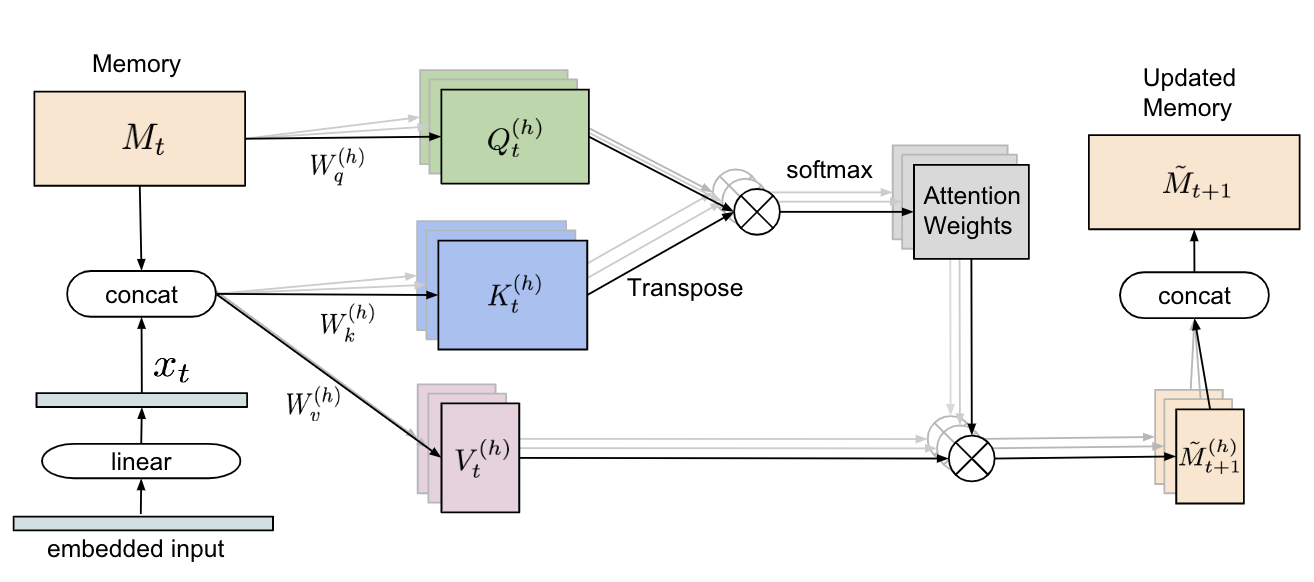
提出了一个更强大的模块(relational memory)作为文本生成模型的生成器。基本思想是引入一组固定的记忆槽(如记忆矩阵),并通过使用self-attention考虑记忆槽之间的相互作用。
- 设
 的每一列都代表一个记忆槽,h代表多头注意力的个数。
的每一列都代表一个记忆槽,h代表多头注意力的个数。 矩阵直接乘上
矩阵直接乘上 矩阵做线性变换得到
矩阵做线性变换得到 ,
, 矩阵与
矩阵与 即t时刻的输入的嵌入向量拼接之后分别乘以
即t时刻的输入的嵌入向量拼接之后分别乘以 矩阵后得到
矩阵后得到 。最终进行self-attention运算得到输出。多头注意力中每个attention输出向量会进行拼接输出
。最终进行self-attention运算得到输出。多头注意力中每个attention输出向量会进行拼接输出 。
。 - 为了得到t时刻的输出并更新隐藏状态,还需要通过MLP与残差连接得到最终的输出:

- 类似于一个引入了self-attention的RNN

Gumbel-Softmax Relaxation
- 设生成器在t时刻的输出为
 ,字母表大小为
,字母表大小为 ,则下一个生成的one hot token
,则下一个生成的one hot token  可通过采样获得:
可通过采样获得: 。普通GAN的激活函数由于不可微分问题难以进行离散序列生成。
。普通GAN的激活函数由于不可微分问题难以进行离散序列生成。 - 应用Gumbel-Softmax松弛技术,它在单纯形上定义了一个连续分布,可以近似于分类分布的样本。该技术包含了两种方法。
- The Gumbel-Max trick:改写了采样方法。其中
 为
为 向量中的第i维,
向量中的第i维, 是从标准Gumbel分布中采样得到的(
是从标准Gumbel分布中采样得到的( ),
), )
)

- Relaxing the discreteness:由于argmax操作仍然是不可微分的,所以我们通过softmax来近似地对“one hot with argmax”操作进行估计。其中,
 ,是一个可调整的参数,叫做逆温度。很明显它的值越大结果越逼近one-hot向量。所以,这个操作得到的结果就可以直接输入判别器中。
,是一个可调整的参数,叫做逆温度。很明显它的值越大结果越逼近one-hot向量。所以,这个操作得到的结果就可以直接输入判别器中。

- Temperature Control:较大的
 会使结果对噪声非常敏感,有助于获得更好的样本多样性,而较小的
会使结果对噪声非常敏感,有助于获得更好的样本多样性,而较小的 则有助于获得更好的样本质量。
则有助于获得更好的样本质量。
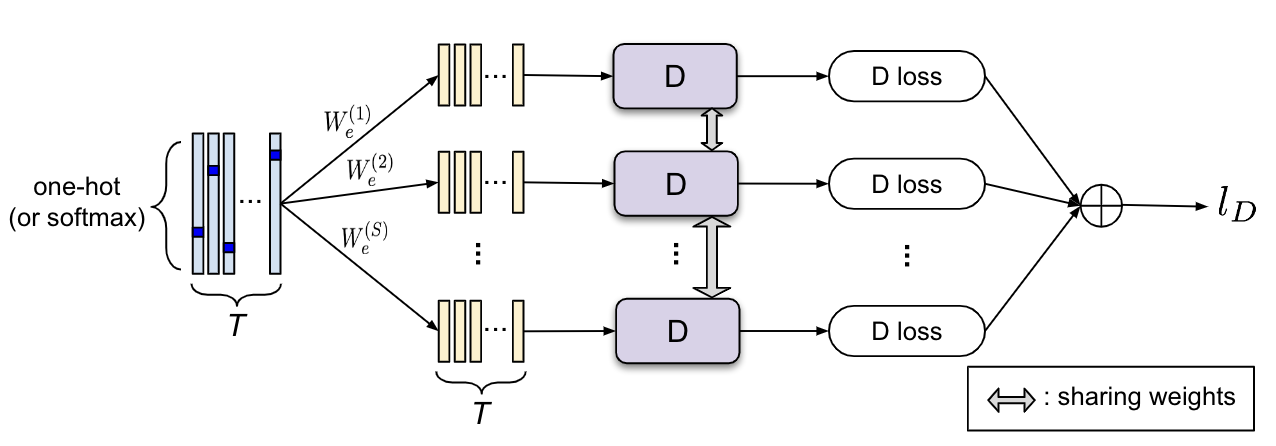
Multiple Embedded Representations in the Discriminator
- 提出了一个新的判别框架,对每个句子应用多个嵌入表示,每个表示向量独立通过上述基于CNN的分类器来获得一个单独的分数。这些单个分数的平均值将作为最终的指导信息来更新生成器。
- 每一个嵌入表示都可能捕捉到输入句子的一个特定方面,而从这些不同角度对真实句子和生成的句子进行比较的判别器可以为生成器的更新提供更多样化和全面的指导信息。
- 这个想法类似于使用多个鉴别器来改善图像生成的GAN。但不同的是,这里只使用输入的多个不同的表征,同时仍然保持一个基于CNN的单一或分权的分类器。(提高运算效率)
- 设
 为第
为第 个真实的one-hot token,
个真实的one-hot token, 为生成的第
为生成的第 个softmax-like token,判别器会把真实数据
个softmax-like token,判别器会把真实数据 或者
或者 映射至
映射至 个嵌入表示
个嵌入表示 中
中 - 这样,真实数据与生成器输出经过判别器得到的输出分别是:

- 损失函数:

Experiments
- 全面优于SeqGAN, RankGAN, LeakGAN

若有收获,就点个赞吧
0 人点赞
