过拟合
拟合程度过高可能会导致模型对新的数据估计失灵。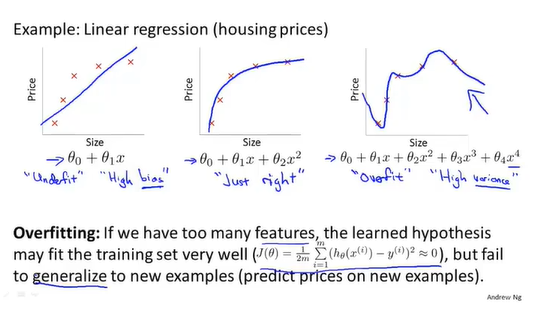
如何解决过拟合的问题?
- 减少特征变值的数量
- 手动选择保留哪些特征变量
- 模型选择算法
- 正则化(避免舍弃重要信息)
- 减少量级或参数

- 使用该种方法,即使特征值很多也不会有影响。每个特征值都对预测值作出一定的贡献
- 减少量级或参数
代价函数的正则化
用一个例子来引入正则化背后的思想
如图所示,左为正常的拟合曲线,右为过拟合的函数曲线。不难发现,由于右图函数多了 这两项,对原本较好的模型带来了一些不好的影响。因此我们想做的就是将
这两项,对原本较好的模型带来了一些不好的影响。因此我们想做的就是将 的权重尽可能减小,以消除过拟合的问题。因此我们在代价函数后加上两个惩罚项,由于我们想让代价函数尽可能小,当我们对的项乘上一个很大的系数后,为使代价函数取得最低值,我们不得不减小的值。由此,我们达到了消除过拟合的目的。
的权重尽可能减小,以消除过拟合的问题。因此我们在代价函数后加上两个惩罚项,由于我们想让代价函数尽可能小,当我们对的项乘上一个很大的系数后,为使代价函数取得最低值,我们不得不减小的值。由此,我们达到了消除过拟合的目的。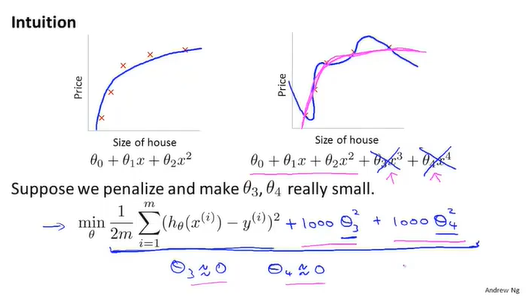
事实上,当我们尽可能地减小 的值时,我们就在简化这个估计函数,也大大地减小了过拟合的可能。
的值时,我们就在简化这个估计函数,也大大地减小了过拟合的可能。
因此正则化代价函数的表达式就为:
其中, 被称为正则化参数。若该参数过大,即惩罚程度过大,则会导致所有参数趋于零,最后在只剩下常数项。这种情况我们称之为欠拟合。
被称为正则化参数。若该参数过大,即惩罚程度过大,则会导致所有参数趋于零,最后在只剩下常数项。这种情况我们称之为欠拟合。
线性回归的正则化
用正则化优化之前学过的梯度下降以及正规矩阵法
- 梯度下降法
对于梯度下降法, 一般单独进行更新。回顾之前的正则化惩罚项,我们也不会去对常数项进行惩罚
一般单独进行更新。回顾之前的正则化惩罚项,我们也不会去对常数项进行惩罚
对前文正则化后的表达式求偏导后,可以得到正则化后的梯度下降公式:
式 通常是一个比1略小的数,如0.99。也就是说,在每次下降时都先把
通常是一个比1略小的数,如0.99。也就是说,在每次下降时都先把 先缩小一点,也就是将的平方范数变小了。除去该式,其余与原先梯度下降算法相同。
先缩小一点,也就是将的平方范数变小了。除去该式,其余与原先梯度下降算法相同。
- 正规方程法
添加一个 维的对角矩阵(但第一行第一列也为0)作为正则项, 同时这可以保证括号内的矩阵是可逆的

Logistic回归的正则化
与线性回归同理,不过注意两者 #card=math&code=h_%5Ctheta%28x%29) 含义的不同


若有收获,就点个赞吧
0 人点赞
