引入
对于logistic回归,我们并不难推出如下结论:若我们想得到更趋于1的 值,那么
值,那么 应远大于0。相反,若我们想得到更趋于0的值,应远小于0。
应远大于0。相反,若我们想得到更趋于0的值,应远小于0。
根据logistic回归的代价函数,我们发现每一个样本x,y都会为总的代价函数增加这样一项: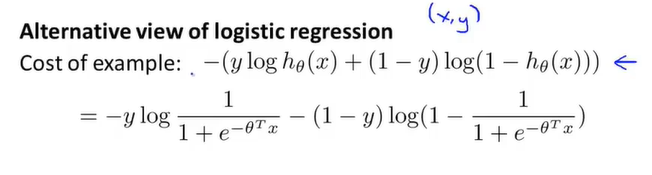
也就是说,这一项代表了单一样本对整个代价函数的贡献。
若y=1,则该项可化简为如下形式。我们看到,当z值,也就是很大时,函数所对应的值非常小,也就是说其对代价函数的影响很小。这也解释了为什么当logistic回归遇见y=1的样本时,会将设成很大的值。这是因为此时下图中函数的值很小。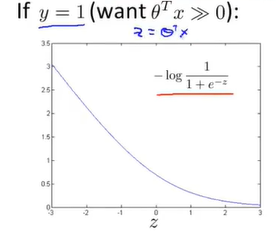
支持向量机的构建从现在开始。选取z=1作为起点,直线右侧区域均与x轴重合,左侧区域参考logistic回归曲线画一条直线。我们可以看到,这两条线段与原函数拟合程度较好。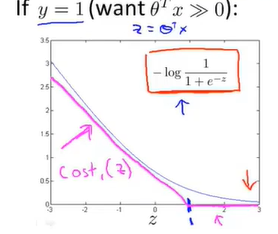
对于y=0的情况,相似地,我们也可做出如下曲线: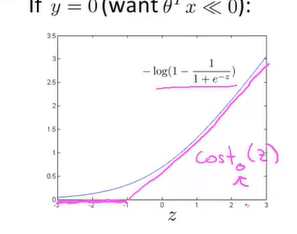
logistic回归的代价函数原先是这样的。现在我们来用刚才求得的 替代原先函数中部分项
替代原先函数中部分项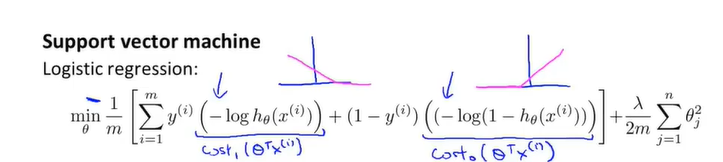
由于m为常数,因此在计算最小值时通常会去掉这两项。
所以,对于logistic函数,我们的目标函数有两项:原先代价函数与正则化项。
我们可以通过设定不同的正则化参数值,以便能够权衡我们在多大程度上去适应训练集,也就是更注重A还是B。支持向量机使用一种不同的参数C。

支持向量机不会输出概率,我们通过优化代价函数的得到一个参数 。通过参数,SVM会进行直接的预测,预测y=1还是0。
。通过参数,SVM会进行直接的预测,预测y=1还是0。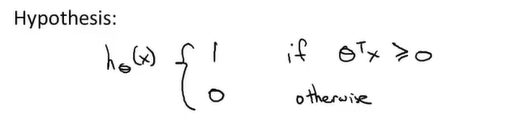
大间隔分类器
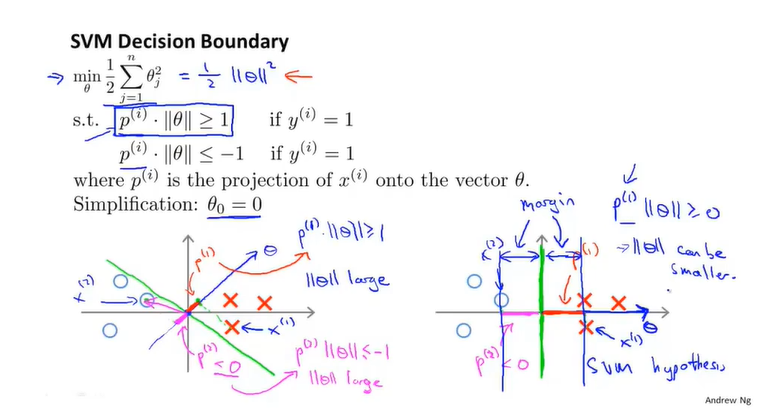
前面已经讲过,这是支持向量机的代价函数。由于我们希望代价函数能够尽可能小,对照cost0与cost1的函数图像,因此当y=1时,我们希望>=1。反之y=0时,我们希望<=-1。
当我们把C设为一个很大的值时,为了使前一项为0,当y=1时,我们使>=1。反之y=0时,我们使<=-1。这样,原式就转变为了 。这样,我们得到了一个有趣的决策边界。
。这样,我们得到了一个有趣的决策边界。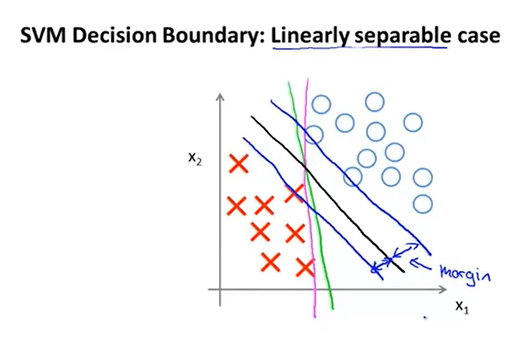
SVM不会选取粉线或者绿线作为决策边界,而是会选择黑线。不难看出,黑线到圆圈样本点与叉样本点的距离都很大。这一距离就是大间隔分类器所指的间隔。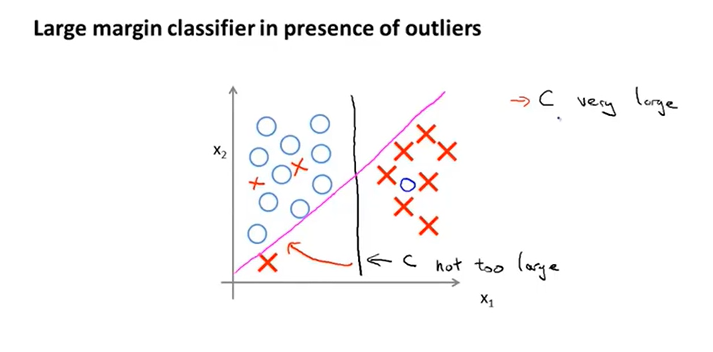
当C非常大时,SVM就会尽可能的画出最精确的决策边界,确保两类样本点都落在相应的半区。但如果C不是很大时,SVM会优先考虑决策边界到两类样本点之间的间隔问题,而去忽略异常点带来的影响。所以即使对于非线性可分的数据,SVM也能做得很好。
数学原理
向量内积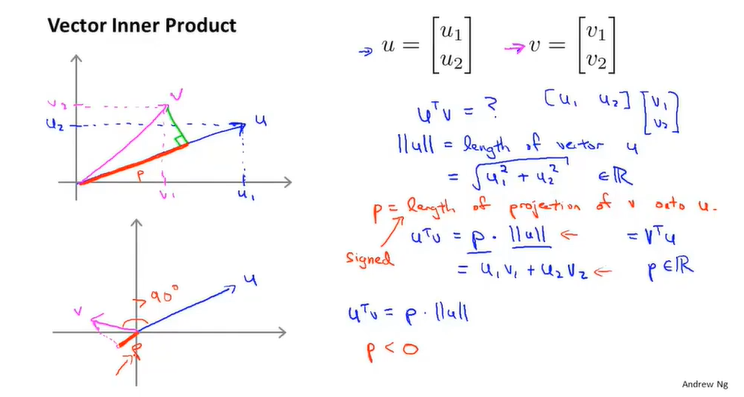
核函数
对于非线性决策边界,我们该如何区别正负实例?一种方法是构造一个复杂多项式特征的集合,如图所示:
形如f1,f2,fn的特征值有没有更好的表示方法?
我们可以定义几个坐标点,像这样定义新的特征

若有收获,就点个赞吧
0 人点赞
