特征表示
我们知道,在机器学习过程中,模型接受的是一个特征向量。我们在处理图像时可以直接把图像作为一组向量来输入,然而像句子、音频等等呢?第一步的特征工程即需要把每条样本表示为向量,即特征向量。不论输入是非数值类型(图片、语音、文字、逻辑表示等),或者本身就是数值类型,我们都需要将输入数字化为特征向量。
因为特征工程决定着算法上限。所以我们不仅要转为特征向量,而且希望转成的特征向量也足够好。因此,基于自动编码器(Auto-encoder)和词嵌入(Word-Embedding)的启发,我们期望转换后的特征向量(或者叫Embedding),能够自带节点信息(例如在特征空间上,相似的节点会离得特别近),这将非常有利于机器学习的任务。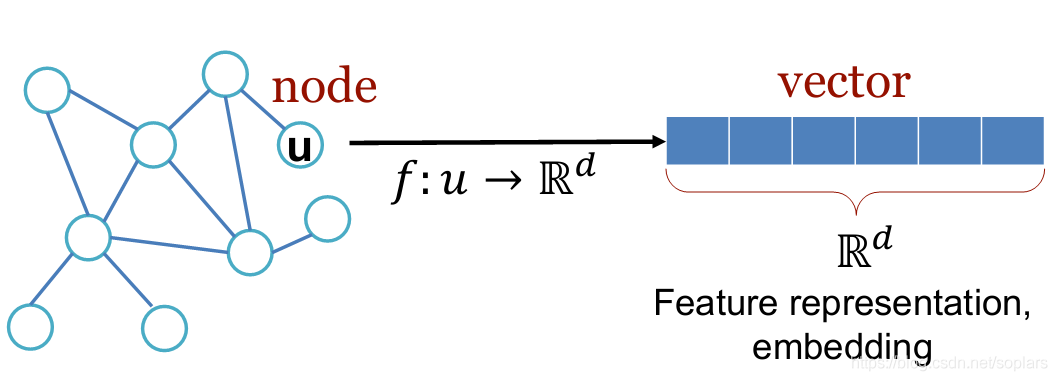
图片、文字较为容易表示为特征向量,因为它们都是固定的线性一维或二维结构,但图有以下不同:
- 图的结构无关节点位置,只有连接关系有关,因此结构可以任意变化
节点具有无序性,节点可以以任意方式标号,只要总的连接关系没变,图就没有改变
解决方法
线性化思路:通过图(graph)结构里的遍历,生成节点的序列,来创造“句子”语料,然后再使用Word2Vec的思想。如 Node2Vec、DeepWalk。
- 图神经网络:用周围节点来编码中心节点,相当于通过训练一个虚拟网络(Network),把每个节点周围的结构信息储存在了这个虚拟网络(Network)里,而输入周围节点后这个网络输出的向量,正是这个中心节点的embedding。
- 知识图谱:传统的知识图谱表示方法是采用OWL、RDF等本体语言进行描述;随着深度学习的发展与应用,我们期望采用一种更为简单的方式表示,那就是向量,采用向量形式可以方便我们进行之后的各种工作,比如:推理,所以,我们现在的目标就是把每条简单的三元组< subject, relation, object > 编码为一个低维分布式向量。

若有收获,就点个赞吧
0 人点赞
