概览
待解决问题:给定一个已为一些结点打好标签的网络,如何为剩下的结点打上标签?
- 例如一个网络有可信结点以及不可信结点,如何进行区分?
- 半监督学习过程
- 利用网络中存在的关联关系
- 三种技术:关系分类、迭代分类、置信传播
网络中存在的三种相互作用的关系:
- 个体的个性促成共性
- 共性可反作用于个体


通常,相似的结点在网络上通常靠得很近或者直接连接。所以,在进行分类时我们不仅要使用当前结点O的特性,还需要结合结点O邻居的标签以及特性。
连坐(Guilt by Association):给定一个网络以及一些打好标签的结点,假设该网络具有同质性(homophily),如何找出剩下具有特定标签的结点?

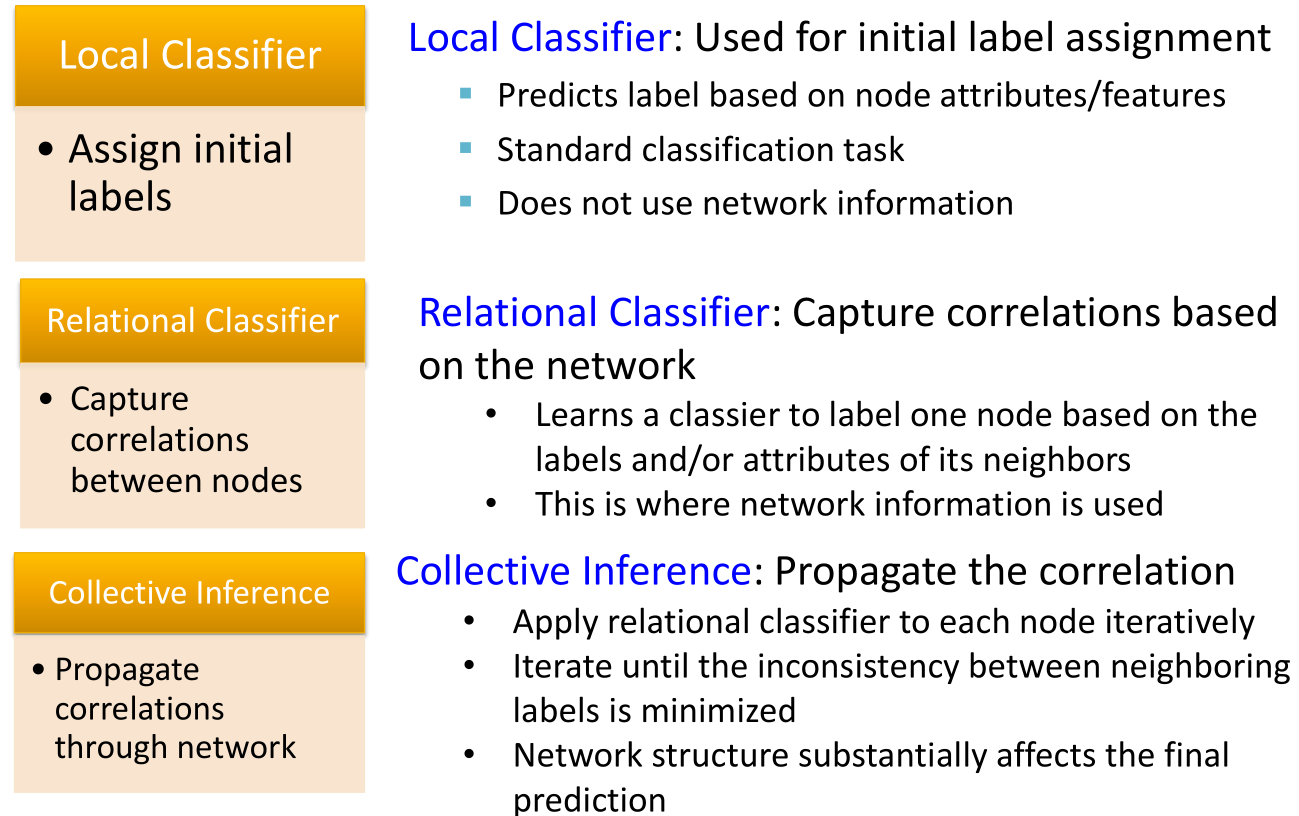
- 集体分类(Collective Classification):使用相关联的互连结点做同时的分类。做了一个马尔可夫假设:一个结点i的标签Yi取决于它的邻居Ni的标签。
 包含三个步骤,如图所示。
包含三个步骤,如图所示。- 注意集体分类是一个迭代的过程,在于不断地对结点使用关系分类(Relational Classifier)
- 对网络进行确切的推断是一个np难问题,因此三种方法(关系分类、迭代分类、置信传播)都是做近似推断,且都是迭代算法
- 基于概率的关系分类器:核心思想即结点i标签取Yi的概率为它所有的邻居相应概率的均值。
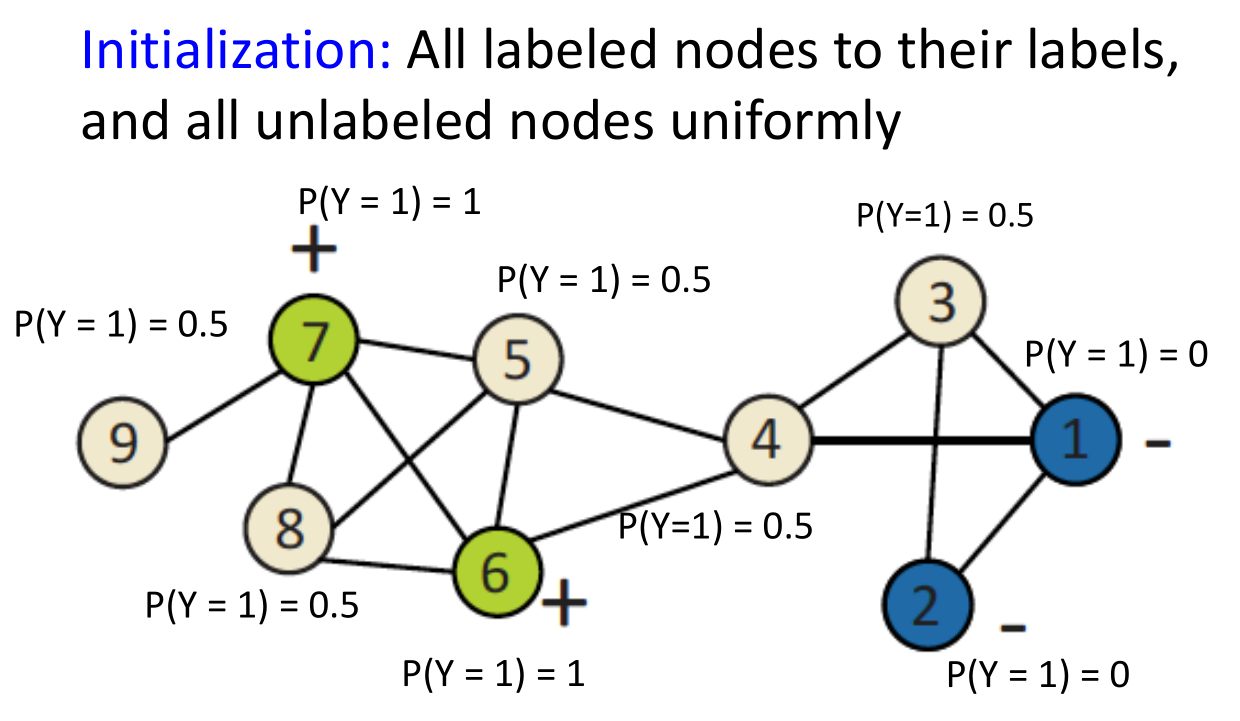
- 对于已打好标签的结点,初始化它的Y值,对于未打标签的结点,正态初始化Y的值。随机地更新所有的结点,直到所有值都已收敛或迭代次数达到最大。
 ,其中
,其中 即结点i到结点j边的权值,
即结点i到结点j边的权值, 是结点i的邻居数目
是结点i的邻居数目- 挑战:首先,并不能保证一定能够收敛,模型不能利用结点的特征信息(只利用了网络的特征信息)
- 步骤非常简单,如先将所有未打标签的结点初始化为0.5,然后任取一个结点,计算并更新它的值,并依次传播下去,这称之为一次迭代。再任取一个结点进行这一过程,可以进行下一次迭代。过程如图所示:
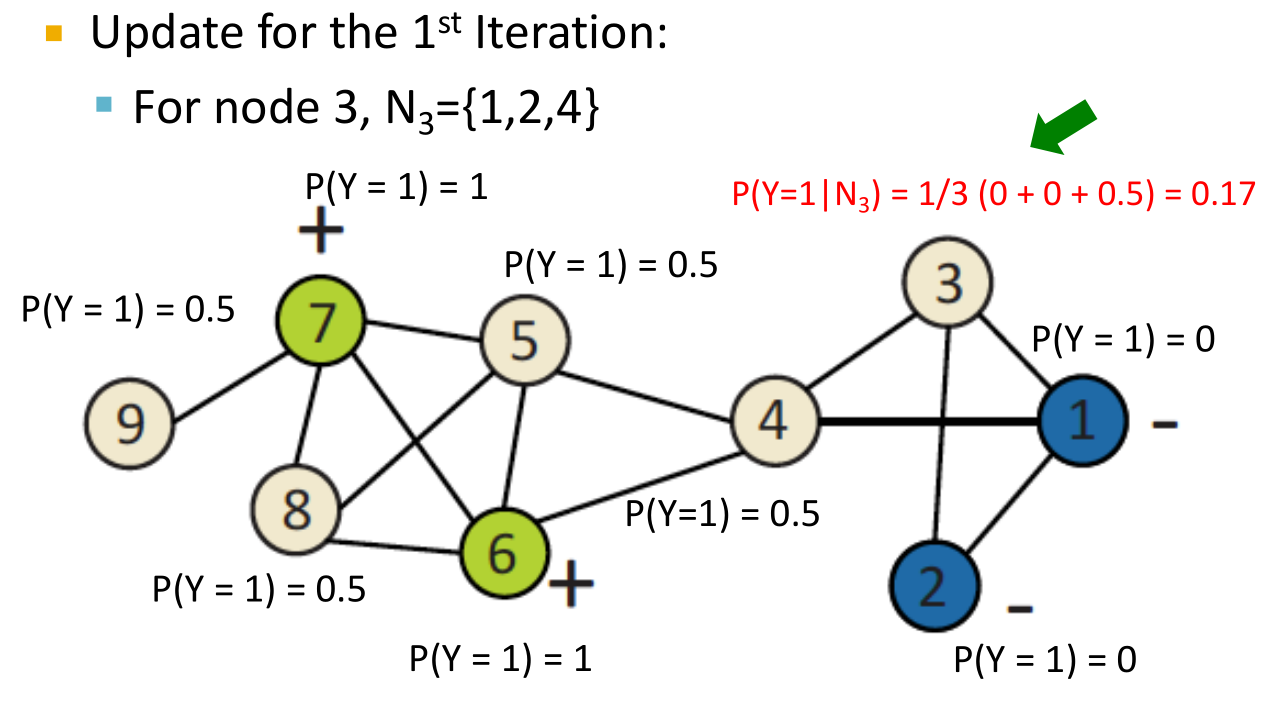

- 最终结果如下。以0.5作为阈值,就可以对结点进行预测了。
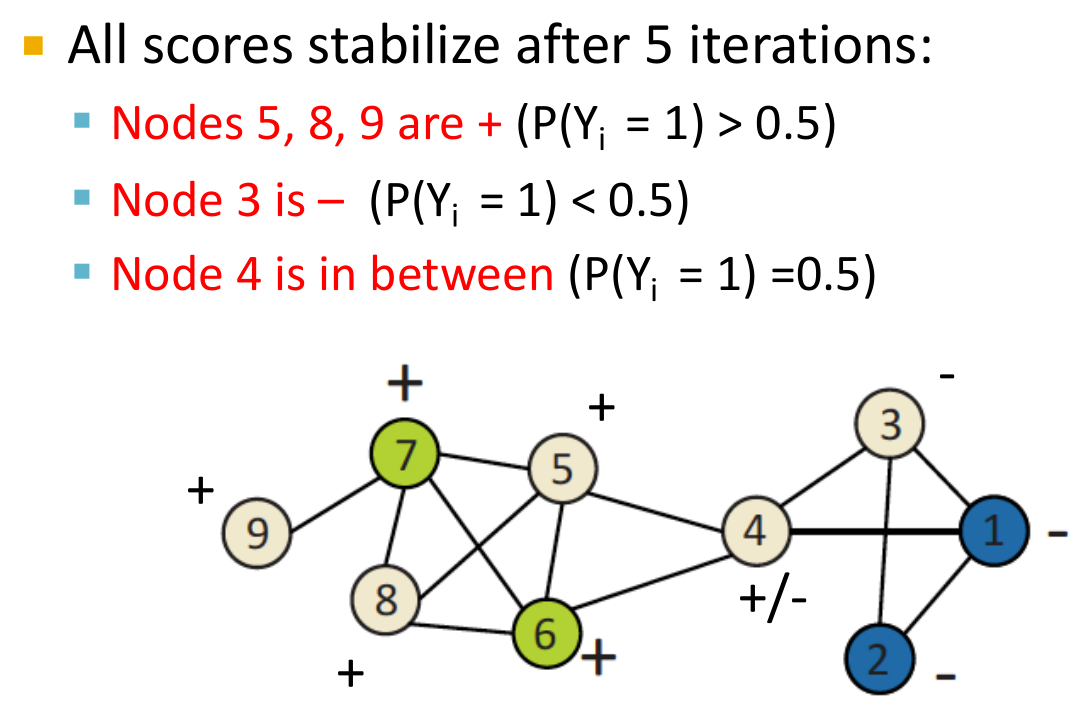
- 迭代分类:关系分类没有利用到结点特征,这是最大的缺陷。因此迭代分类在关系分类的基础上加上了对于结点特征的考虑。
- 为每个节点生成一个向量
 ,随后使用
,随后使用 训练一个分类器。结点可能会有很多邻居,所以我们可以使用累加、均值等操作(图神经也会用到这些技术)整合这些信息。
训练一个分类器。结点可能会有很多邻居,所以我们可以使用累加、均值等操作(图神经也会用到这些技术)整合这些信息。 - 起步步骤:将每个结点i转化成一个向量,随后使用分类器(SVM、kNN等)计算出Yi的最佳值。
- 迭代步骤:迭代直到收敛为止,与之前相似。对于每一个结点,更新它的向量,并将Yi使用分类器进行更新。同样,直到所有分类稳定下来或者达到了最大迭代次数。
- 要注意的是,并不能保证最后完成收敛。
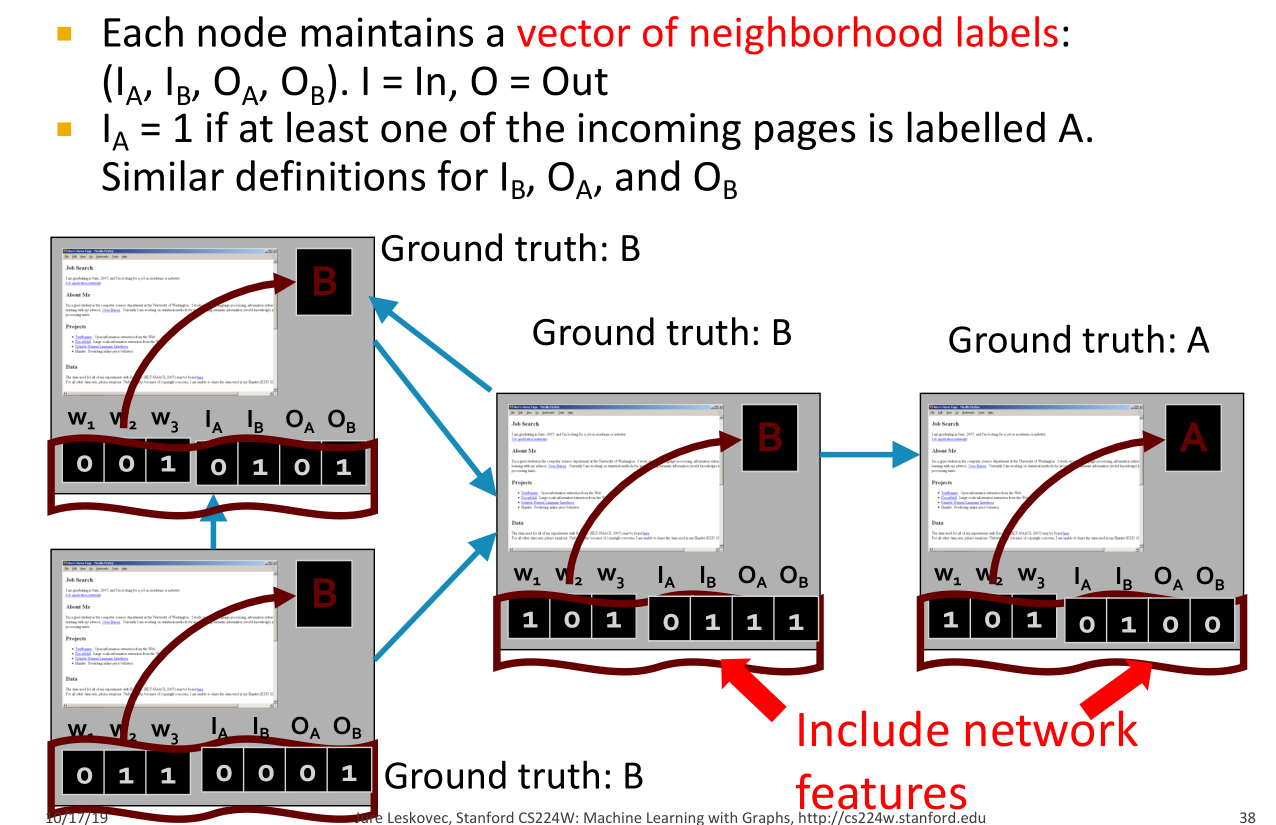
- 下面可以来看一个对网页质量进行分类的例子:首先可以基于出现的词对于网页进行分类。但只考虑词显然是不够的,也可能会造成误分类现象(如图1)。这时我们可以将页面之间的互联关系也纳入考虑,可为每个页面建立一个向量
 ,A为好,B为坏,I为1表示具有该入度,O为1就表示具有该出度。所以我们需要建立两个分类器,一个仅仅基于单词进行分类,另一个使用两者连接得到的向量进行分类。
,A为好,B为坏,I为1表示具有该入度,O为1就表示具有该出度。所以我们需要建立两个分类器,一个仅仅基于单词进行分类,另一个使用两者连接得到的向量进行分类。 - 具体步骤:首先对训练集训练两个分类器。在测试集上,首先利用训练好的词分类器进行初步分类,随后将页面之间的联系加入到特性中,再使用第二个分类器进行分类。再不断更新向量直至收敛。
- 为每个节点生成一个向量


置信传播(Belief Propagation)
这一算法在整幅图的范围内进行条件概率的计算,结点与结点之间传递(我认为你的状态为…的概率是…)的信息
传递过程的类比:
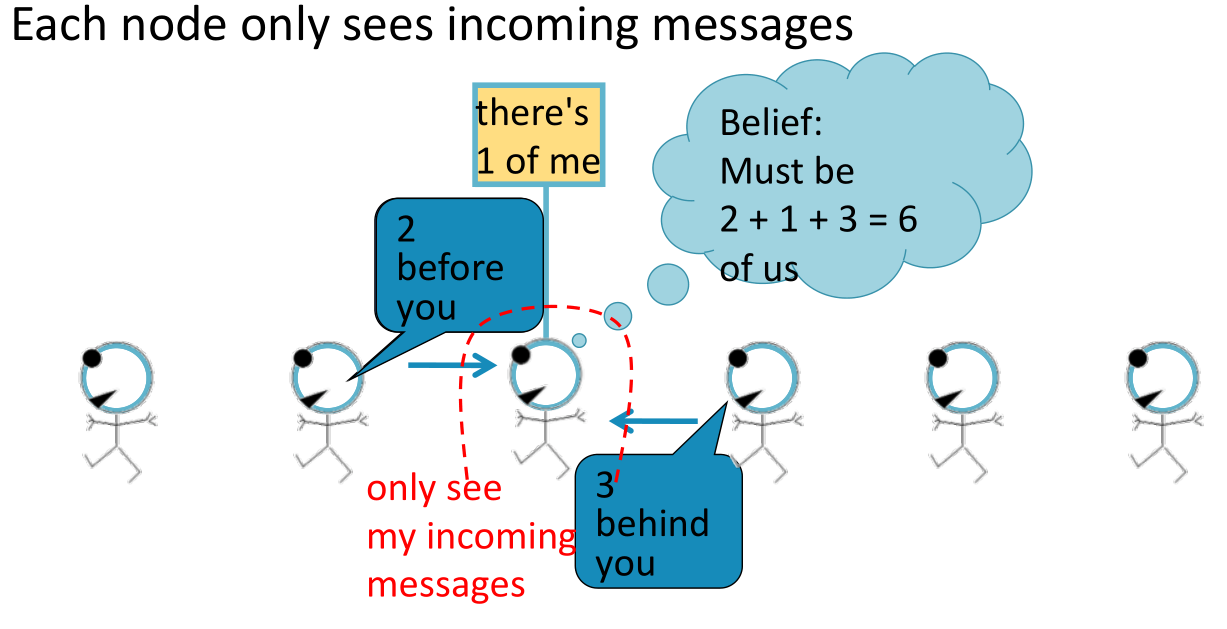
- 每个结点监听来自邻居的信息,做一次更新,并继续向前传播
- 每个结点只能与它的邻居互动
- 单向传播到底后,只有最终结点知晓了结果,因此我们需要做一次反向传播。这样,每个结点根据前向传播与反向传播获取到的信息就可以计算出图中的结点个数
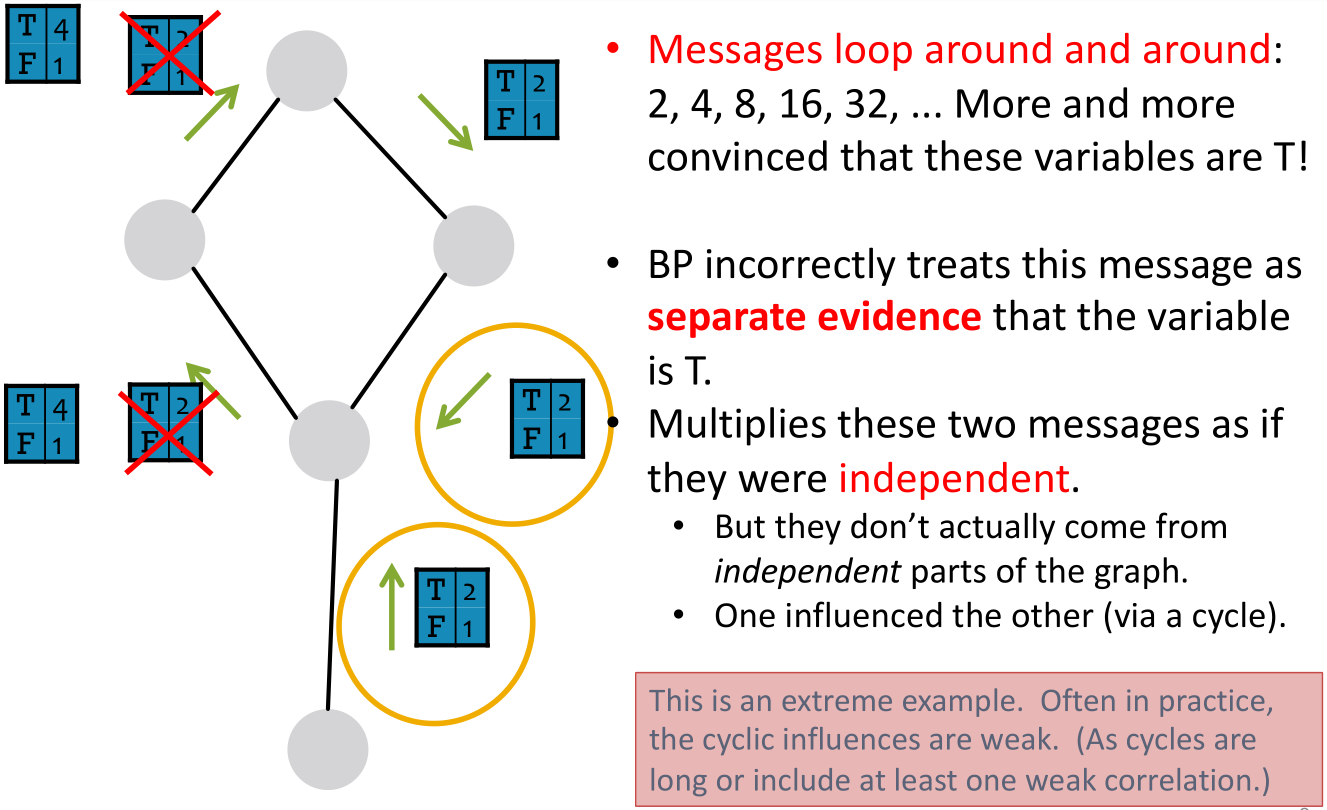
- 若在有回路的图中应用此算法,由于没有终止标准该过程会一直持续下去

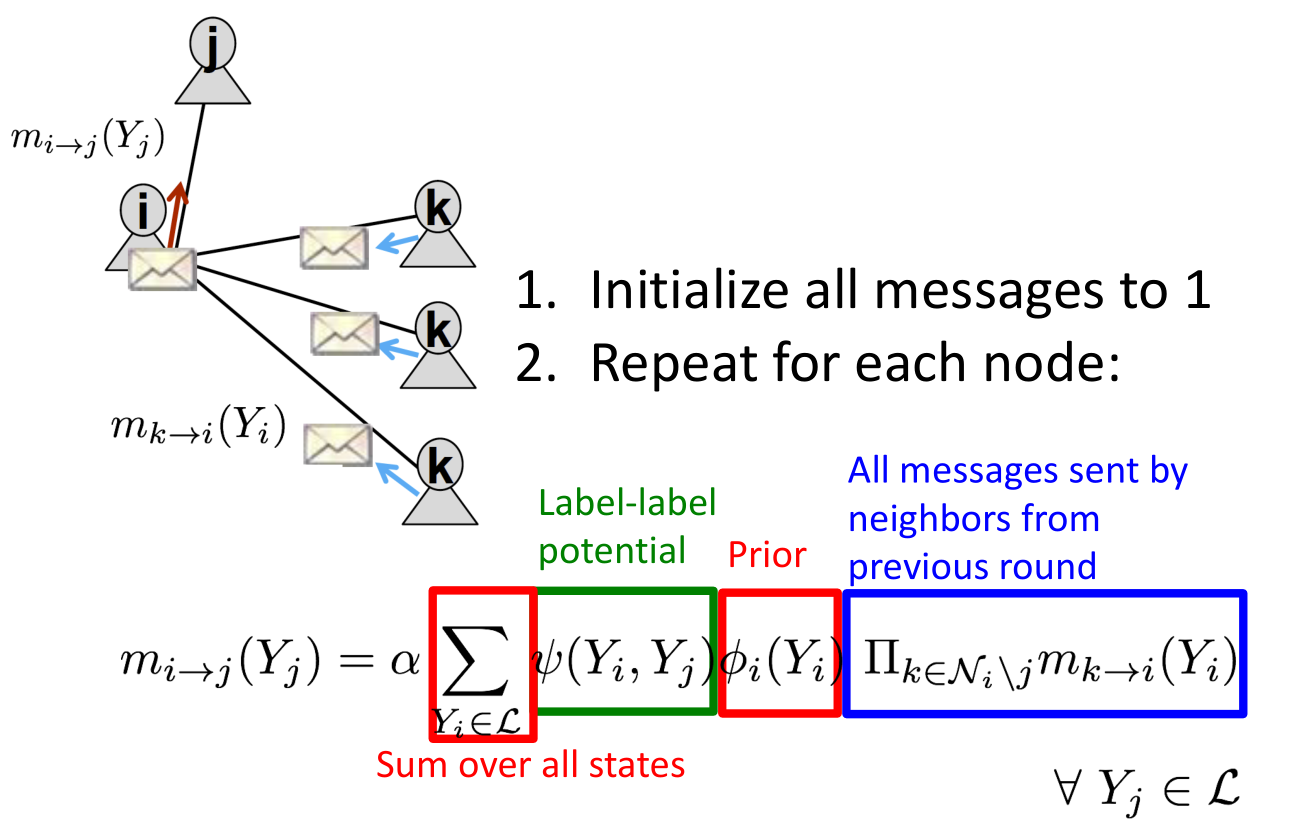
- 概念:
- 标签-标签预测矩阵
 :展现结点与它的邻居的依赖关系。
:展现结点与它的邻居的依赖关系。  等于结点j拥有一个状态为
等于结点j拥有一个状态为 的结点i时状态取
的结点i时状态取 的概率
的概率 - 主置信度
 :
: 代表结点i状态取的概率
代表结点i状态取的概率  为i对结点j的状态的预测
为i对结点j的状态的预测 为所有状态的集合
为所有状态的集合
- 标签-标签预测矩阵
- 循环BP算法:
- 首先将所有信息初始化为1,随后对每个结点重复以下步骤:
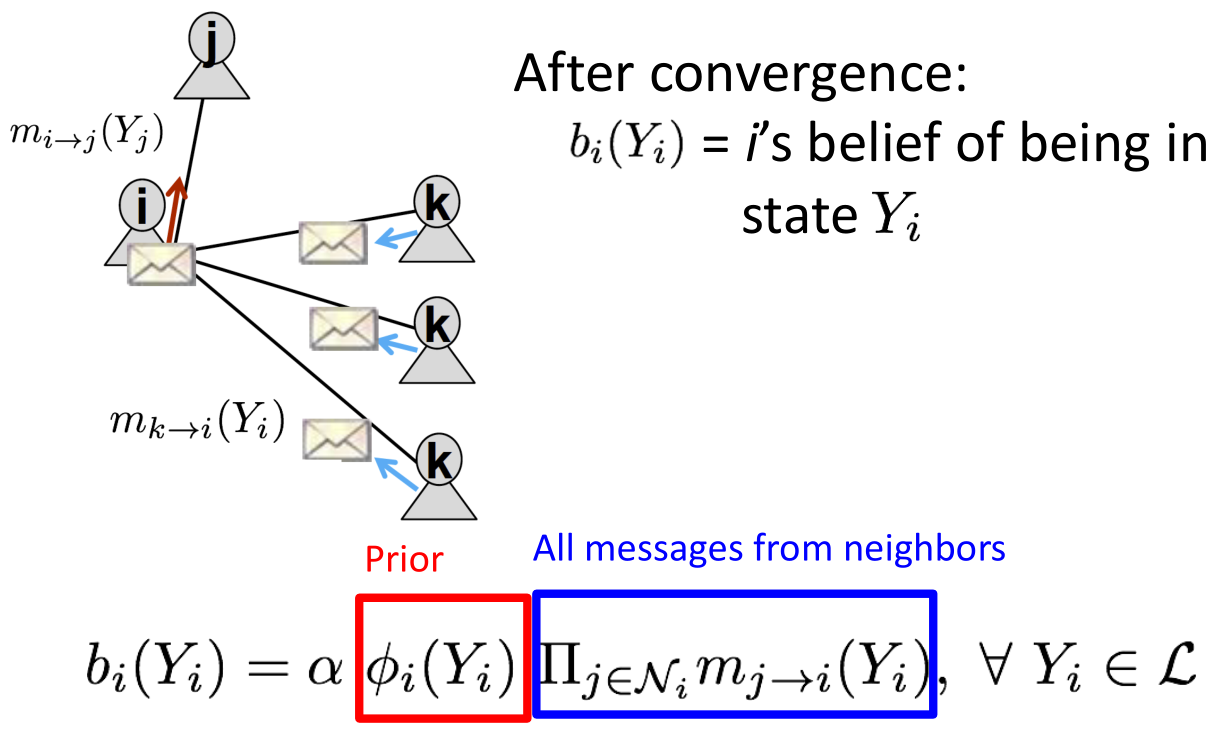
- 达到收敛后,计算
 ,即结点i的状态取的置信度
,即结点i的状态取的置信度
- 可能出现的问题:
- 总结:
- 优点是编程友好,泛化性好
- 但不能保证一定会达到收敛
- 参数需要训练

若有收获,就点个赞吧
0 人点赞
