学习目标
- 目标
- 应用isnull判断是否有缺失数据NaN
- 应用fillna实现缺失值的填充
- 应用dropna实现缺失值的删除
- 应用replace实现数据的替换
1 如何处理nan
- 获取缺失值的标记方式(NaN或者其他标记方式)
- 如果缺失值的标记方式是NaN
- 判断数据中是否包含NaN:
- pd.isnull(df),
- pd.notnull(df)
- 存在缺失值nan:
- 1、删除存在缺失值的:dropna(axis=’rows’)
- 注:不会修改原数据,需要接受返回值
- 2、替换缺失值:fillna(value, inplace=True)
- value:替换成的值
- inplace:True:会修改原数据,False:不替换修改原数据,生成新的对象
- 1、删除存在缺失值的:dropna(axis=’rows’)
- 判断数据中是否包含NaN:
如果缺失值没有使用NaN标记,比如使用”?”
电影数据文件获取
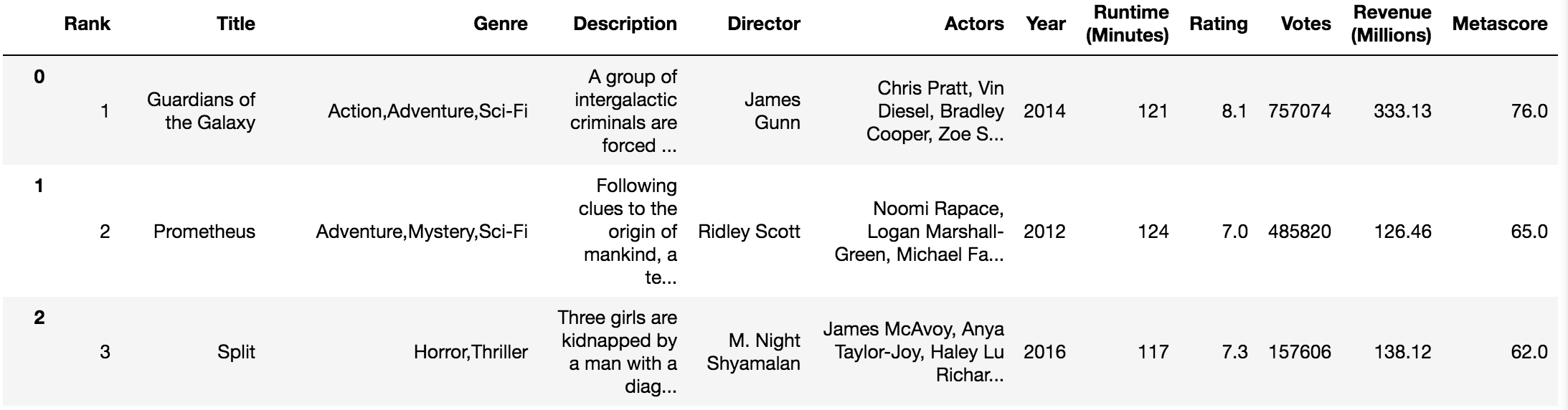
# 读取电影数据movie = pd.read_csv("./data/IMDB-Movie-Data.csv")
2.1 判断缺失值是否存在
pd.notnull()
pd.notnull(movie)
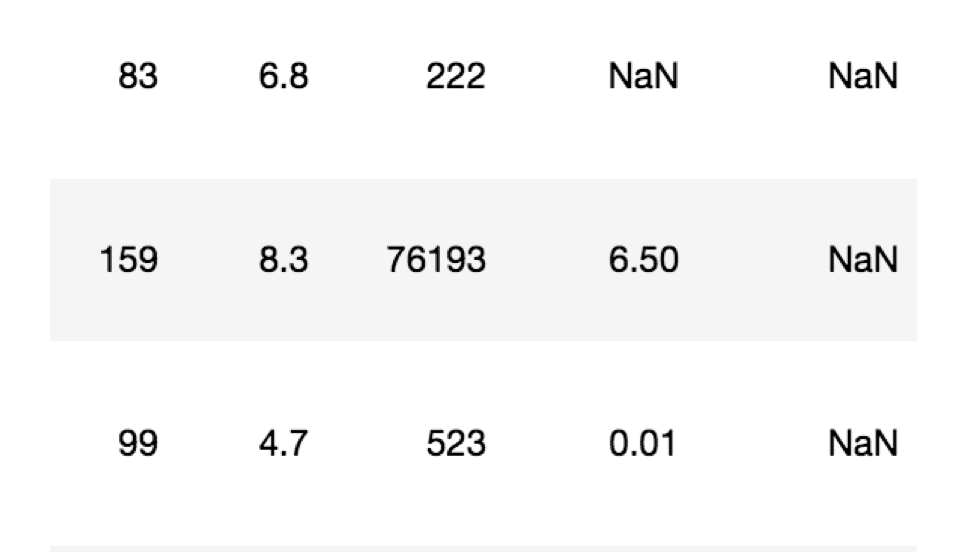
Rank Title Genre Description Director Actors Year Runtime (Minutes) Rating Votes Revenue (Millions) Metascore0 True True True True True True True True True True True True1 True True True True True True True True True True True True2 True True True True True True True True True True True True3 True True True True True True True True True True True True4 True True True True True True True True True True True True5 True True True True True True True True True True True True6 True True True True True True True True True True True True7 True True True True True True True True True True False True
np.all(pd.notnull(movie))
-
2.2 存在缺失值nan,并且是np.nan
1、删除
pandas删除缺失值,使用dropna的前提是,缺失值的类型必须是np.nan
# 不修改原数据movie.dropna()# 可以定义新的变量接受或者用原来的变量名data = movie.dropna()
2、替换缺失值
# 替换存在缺失值的样本的两列# 替换填充平均值,中位数# movie['Revenue (Millions)'].fillna(movie['Revenue (Millions)'].mean(), inplace=True)
替换所有缺失值:
for i in movie.columns:if np.all(pd.notnull(movie[i])) == False:print(i)movie[i].fillna(movie[i].mean(), inplace=True)
2.3 不是缺失值nan,有默认标记的
数据是这样的:
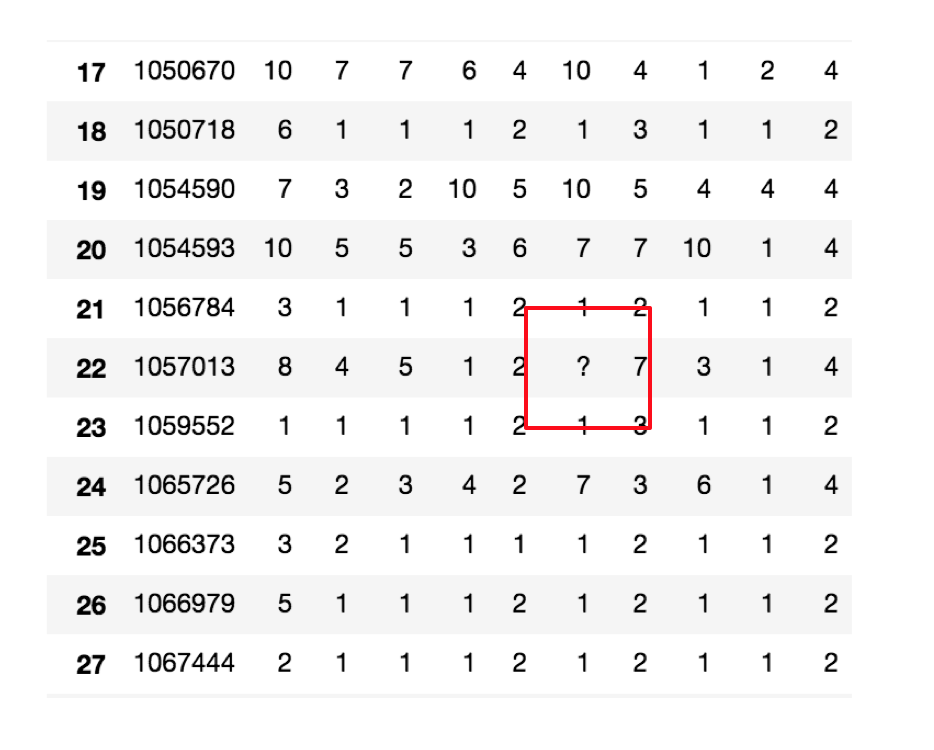
wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data")
以上数据在读取时,可能会报如下错误:
URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:833)>
解决办法:
# 全局取消证书验证import sslssl._create_default_https_context = ssl._create_unverified_context
处理思路分析:
1、先替换‘?’为np.nan
- df.replace(to_replace=, value=)
- to_replace:替换前的值
- value:替换后的值
# 把一些其它值标记的缺失值,替换成np.nanwis = wis.replace(to_replace='?', value=np.nan)
- df.replace(to_replace=, value=)
2、在进行缺失值的处理
# 删除wis = wis.dropna()
3 小结
isnull、notnull判断是否存在缺失值【知道】
- np.any(pd.isnull(movie)) # 里面如果有一个缺失值,就返回True
- np.all(pd.notnull(movie)) # 里面如果有一个缺失值,就返回False
- dropna删除np.nan标记的缺失值【知道】
- movie.dropna()
- fillna填充缺失值【知道】
- movie[i].fillna(value=movie[i].mean(), inplace=True)
- replace替换具体某些值【知道】
- wis.replace(to_replace=”?”, value=np.NaN)

若有收获,就点个赞吧
0 人点赞
