1.9 可避免偏差
人类水平和训练误差的差距称作可避免误差(avoidable bias)。相同的训练集误差和验证集误差条件下,优化策略取决于人类水平(可看作贝叶斯误差)的高低。比如,图片质量很低时,连人类都难以辨识,此时就不应期望机器能够识别的很好。
详细说明: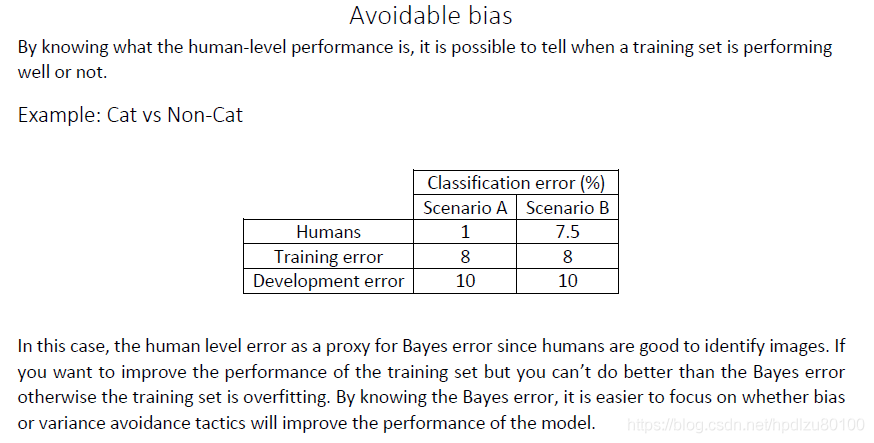

1.10 理解人的表现
问题引入:在以下图像识别示例中,应该如何定义“人类水平误差”?
因为要将人类水平近似看作“贝叶斯误差”,所以这里应该采用最高水平,即,一个经验丰富的医生团队所取得的0.5%的误差,作为“人类水平”
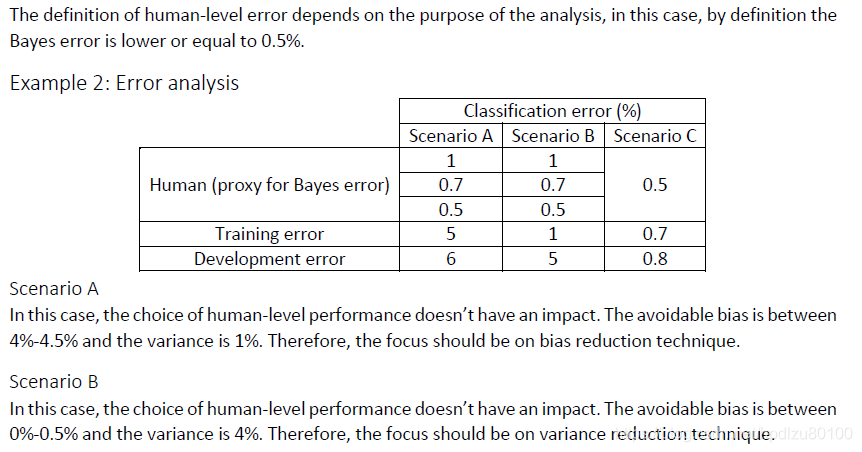
误差分析示例:
小结:
详细说明: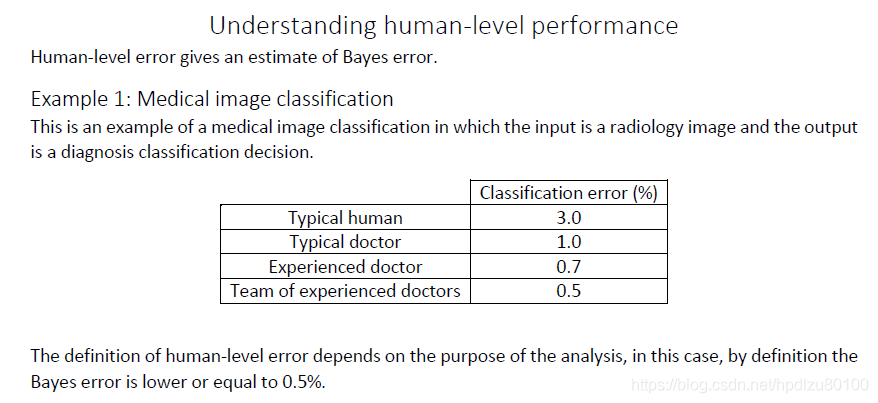

1.11 超过人的表现
当机器的表现已经超越人类水平后,是该降低偏差还是方差,没有足够信息可以回答。如何让机器做得更好?这是个值得探索的问题。
目前,机器已经超越人类的领域有哪些?在线广告、产品推荐、物流、贷款审批(语音识别、部分图像识别(如医学影像(心电图、皮肤癌等))。
这些领域的特点:结构化数据、非感官依赖、大数据。
详细说明: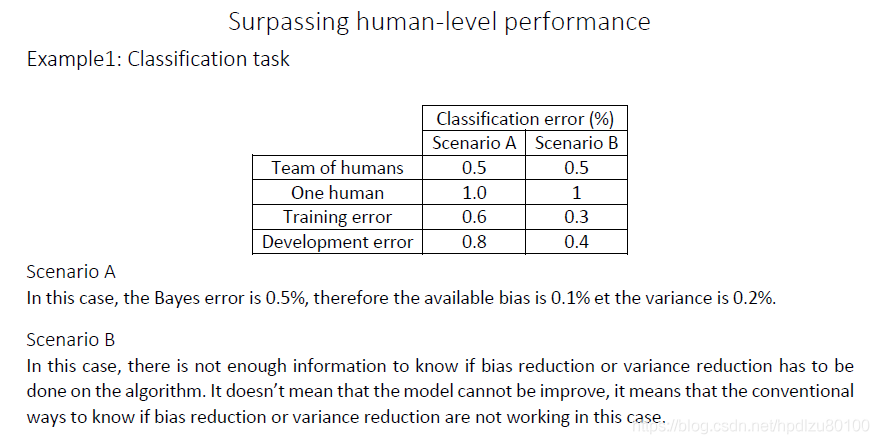

1.12 改善模型表现
监督学习的两个基本假设:
- 可以很好地拟合训练集
- 训练集性能可以很好地泛化到开发集和测试集(即,开发集和测试集上的性能接近训练集上的性能)

降低可避免偏差及方差的方法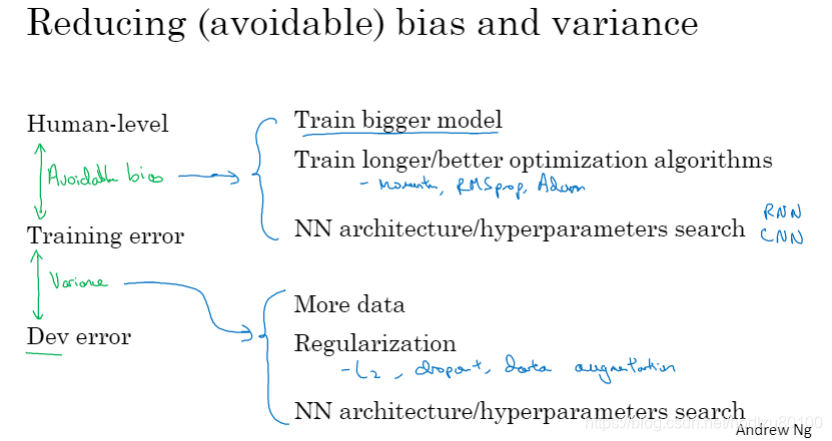
详细描述:

若有收获,就点个赞吧
0 人点赞
