C1W4 Quiz - Key concepts on Deep Neural Networks

Ans: D
Note: the “cache” records values from the forward propagation units and sends it to the backward propagation units because it is needed to compute the chain rule derivatives.

Ans: A、B、E、F
Note: You can check this Quora post or this blog post

Ans: A
Ans: False
Note: We cannot avoid the for-loop iteration over the computations among layers.
Ans: D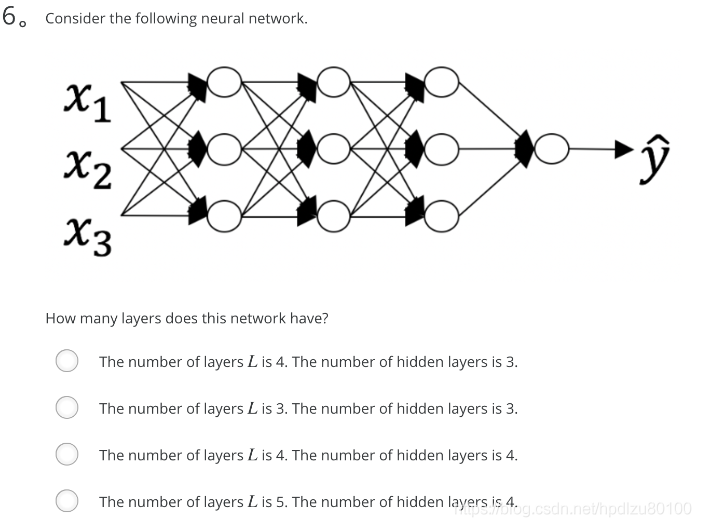
Ans: A
Ans: True
Note: During backpropagation you need to know which activation was used in the forward propagation to be able to compute the correct derivative.
Ans: True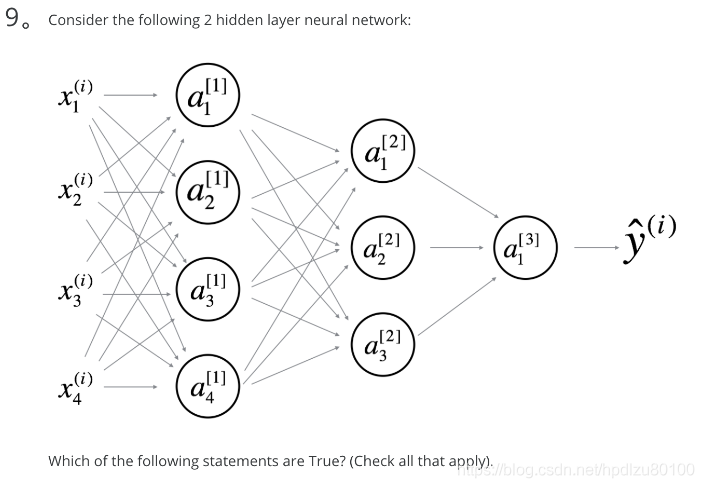

Ans: A、B、E、H、J、K
Note: See this image (https://user-images.githubusercontent.com/14886380/29200515-7fdd1548-7e88-11e7-9d05-0878fe96bcfa.png) for general formulas.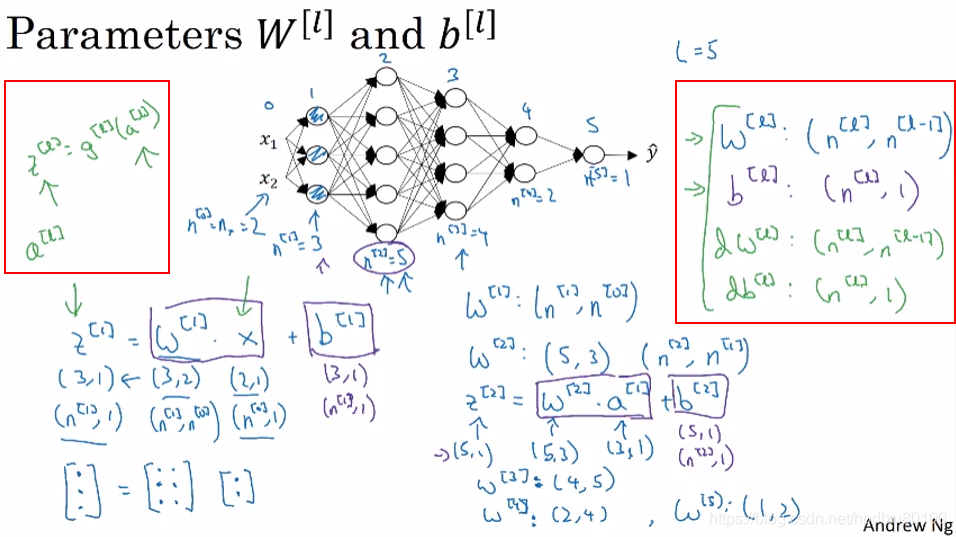

Ans: A
- What is the “cache” used for in our implementation of forward propagation and backward propagation?
- It is used to cache the intermediate values of the cost function during training.
- We use it to pass variables computed during forward propagation to the corresponding backward propagation step. It contains useful values for backward propagation to compute derivatives.
- It is used to keep track of the hyperparameters that we are searching over, to speed up computation.
- We use it to pass variables computed during backward propagation to the corresponding forward propagation step. It contains useful values for forward propagation to compute activations.
Note: the “cache” records values from the forward propagation units and sends it to the backward propagation units because it is needed to compute the chain rule derivatives.
- Among the following, which ones are “hyperparameters”? (Check all that apply.) I only list correct options.
- size of the hidden layers n[l]
- learning rate α
- number of iterations
- number of layers L in the neural network
- Which of the following statements is true?
- The deeper layers of a neural network are typically computing more complex features of the input than the earlier layers.
- The earlier layers of a neural network are typically computing more complex features of the input than the deeper layers.
Note: You can check the lecture videos. I think Andrew used a CNN example to explain this.
- Vectorization allows you to compute forward propagation in an L-layer neural network without an explicit for-loop (or any other explicit iterative loop) over the layers l=1, 2, …,L. True/False?
- True
- False
Note: We cannot avoid the for-loop iteration over the computations among layers.
Assume we store the values for n^[l] in an array called layers, as follows: layer_dims = [n_x, 4,3,2,1]. So layer 1 has four hidden units, layer 2 has 3 hidden units and so on. Which of the following for-loops will allow you to initialize the parameters for the model?
for(i in range(1, len(layer_dims))):parameter[‘W’ + str(i)] = np.random.randn(layers[i], layers[i - 1])) * 0.01parameter[‘b’ + str(i)] = np.random.randn(layers[i], 1) * 0.01Consider the following neural network.
- The number of layers L is 4. The number of hidden layers is 3.
Note: The input layer (L^[0]) does not count.
As seen in lecture, the number of layers is counted as the number of hidden layers + 1. The input and output layers are not counted as hidden layers.
- During forward propagation, in the forward function for a layer l you need to know what is the activation function in a layer (Sigmoid, tanh, ReLU, etc.). During backpropagation, the corresponding backward function also needs to know what is the activation function for layer l, since the gradient depends on it. True/False?
- True
- False
Note: During backpropagation you need to know which activation was used in the forward propagation to be able to compute the correct derivative.
- There are certain functions with the following properties:
(i) To compute the function using a shallow network circuit, you will need a large network (where we measure size by the number of logic gates in the network), but (ii) To compute it using a deep network circuit, you need only an exponentially smaller network. True/False?
- True
- False
Note: See lectures, exactly same idea was explained.
- Consider the following 2 hidden layer neural network:
Which of the following statements are True? (Check all that apply).
- W^[1] will have shape (4, 4)
- b^[1] will have shape (4, 1)
- W^[2] will have shape (3, 4)
- b^[2] will have shape (3, 1)
- b^[3] will have shape (1, 1)
- W^[3] will have shape (1, 3)
- Whereas the previous question used a specific network, in the general case what is the dimension of W^[l], the weight matrix associated with layer l?
- W^[l] has shape (n^[l],n^[l−1])

若有收获,就点个赞吧
0 人点赞

{kind=link}