机器学习流程复习: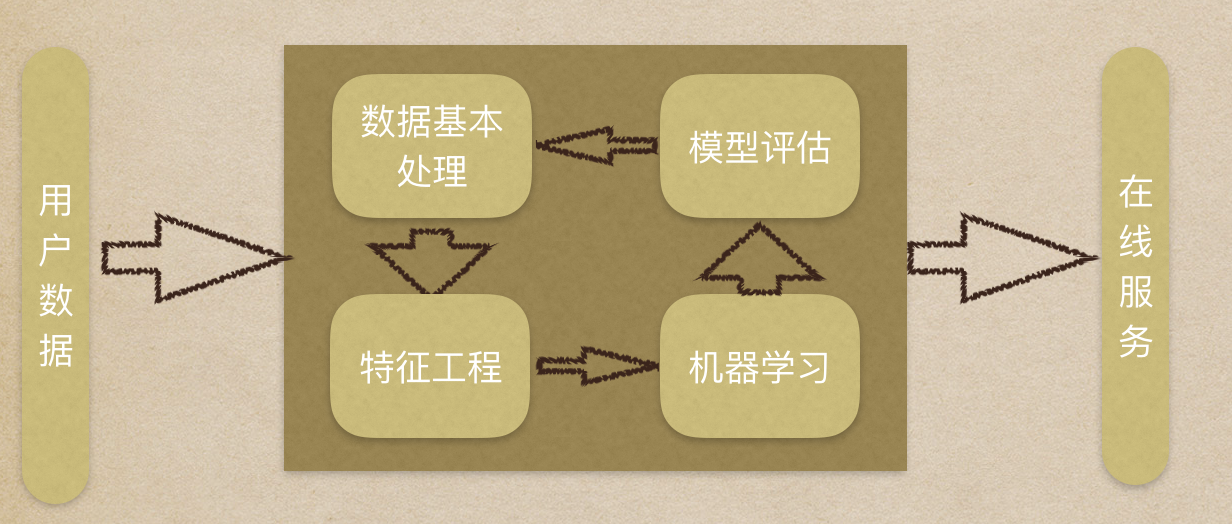
- 1.获取数据集
- 2.数据基本处理
- 3.特征工程
- 4.机器学习
-
1 Scikit-learn工具介绍

Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API
-
1.1 安装
pip3 install scikit-learn==0.19.1
安装好之后可以通过以下命令查看是否安装成功
import sklearn
注:安装scikit-learn需要Numpy, Scipy等库
1.2 Scikit-learn包含的内容

分类、聚类、回归
- 特征工程
-
2 K-近邻算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
1.获取数据集
- 2.数据基本处理(该案例中省略)
- 3.特征工程(该案例中省略)
- 4.机器学习
-
3.2 代码过程
导入模块
from sklearn.neighbors import KNeighborsClassifier
构造数据集
x = [[0], [1], [2], [3]]y = [0, 0, 1, 1]
机器学习 — 模型训练 ```python
实例化API
estimator = KNeighborsClassifier(n_neighbors=2)
使用fit方法进行训练
estimator.fit(x, y)
4 小结
- 最近邻 (k-Nearest Neighbors,KNN) 算法是一种分类算法,
- 1968年由 Cover 和 Hart 提出,应用场景有字符识别、文本分类、图像识别等领域。
- 该算法的思想是:一个样本与数据集中的k个样本最相似,如果这k个样本中的大多数属于某一个类别.
- 实现流程
1)计算已知类别数据集中的点与当前点之间的距离
2)按距离递增次序排序
3)选取与当前点距离最小的k个点
4)统计前k个点所在的类别出现的频率
5)返回前k个点出现频率最高的类别作为当前点的预测分类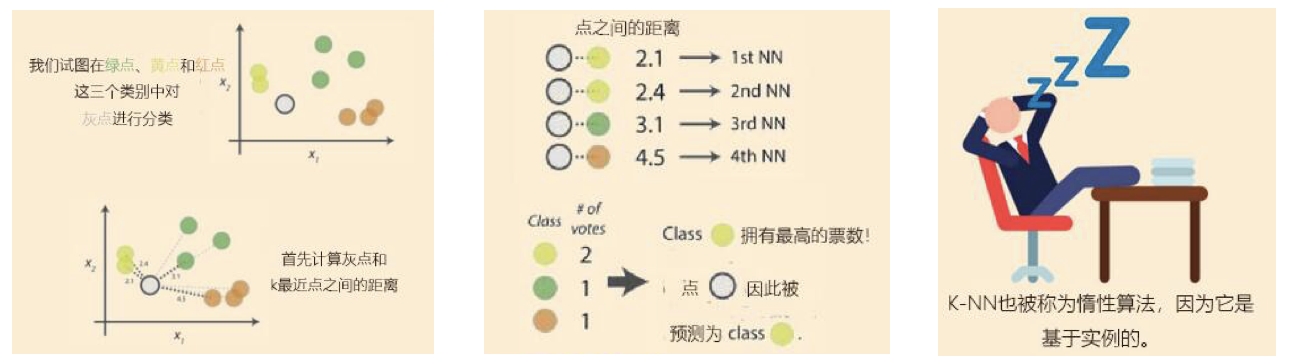
问题
1.距离公式,除了欧式距离,还有哪些距离公式可以使用?
2.选取K值的大小?
3.api中其他参数的具体含义?

若有收获,就点个赞吧
0 人点赞
