C5W1 Quiz - Recurrent Neural Networks

Ans: A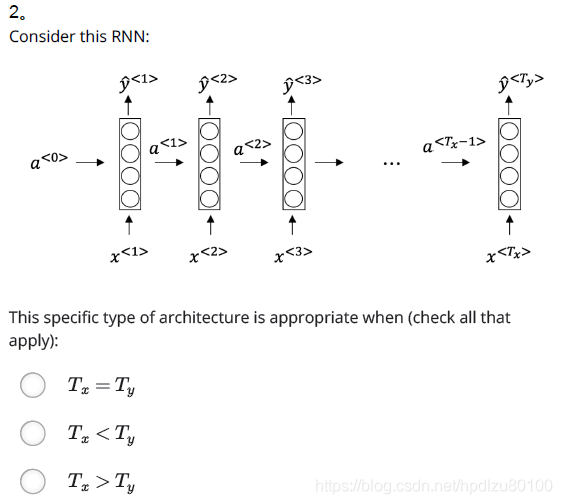
Ans: A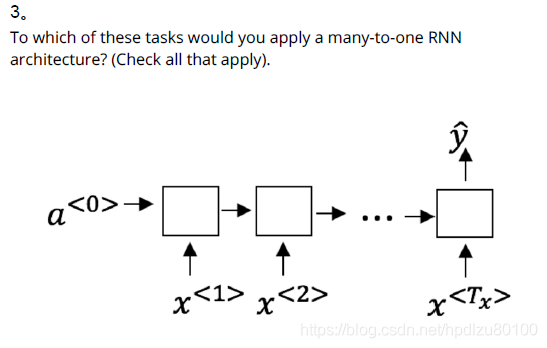

Ans: B、D
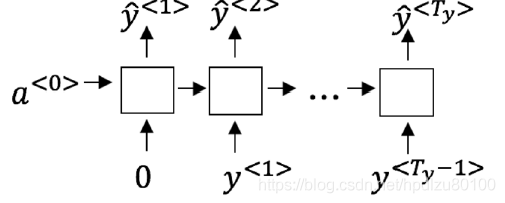
4.

Ans: C

Ans: B
Ans: D

Ans: C
Ans: C
Suppose your training examples are sentences (sequences of words). Which of the following refers to the j^{th}jth word in the i^{th}ith training example?
Ans: x(i)Consider this RNN: This specific type of architecture is appropriate when:
Ans: T_x = T_yTo which of these tasks would you apply a many-to-one RNN architecture? (Check all that apply).
Ans: Sentiment classification (input a piece of text and output a 0/1 to denote positive or negative sentiment)
Gender recognition from speech (input an audio clip and output a label indicating the speaker’s gender)You are training this RNN language model. At the t^{th} time step, what is the RNN doing? Choose the best answer.
Ans: Estimating P(y^{} | y^{<1>}, y^{<2>}, …, y^{ }) You have finished training a language model RNN and are using it to sample random sentences, as follows:
What are you doing at each time step t?
Ans: (i) Use the probabilities output by the RNN to randomly sample a chosen word for that time-step as {y}^{}. (ii) Then pass this selected word to the next time-step. You are training an RNN, and find that your weights and activations are all taking on the value of NaN (“Not a Number”). Which of these is the most likely cause of this problem?
Ans: Exploding gradient problem.Suppose you are training a LSTM. You have a 10000 word vocabulary, and are using an LSTM with 100-dimensional activations a^{
}. What is the dimension of Γu at each time step?
Ans: 10000Here’re the update equations for the GRU.
Ans: Betty’s model (removing Γr), because if Γu ≈ 0 for a timestep, the gradient can propagate back through that timestep without much decay.Here are the equations for the GRU and the LSTM: From these, we can see that the Update Gate and Forget Gate in the LSTM play a role similar to _ and __ in the GRU. What should go in the the blanks?
Ans: Γu and 1-Γu
- You have a pet dog whose mood is heavily dependent on the current and past few days’ weather. You’ve collected data for the past 365 days on the weather, which you represent as a sequence as x^{<1>}, …, x^{<365>}. You’ve also collected data on your dog’s mood, which you represent as y^{<1>}, …, y^{<365>}. You’d like to build a model to map from x→y. Should you use a Unidirectional RNN or Bidirectional RNN for this problem?
Ans: Unidirectional RNN, because the value of y^{

若有收获,就点个赞吧
0 人点赞
