1.6 Dropout 正则化
Dropout(丢弃,失活)正则化:随机选择一些神经元(计算节点),让其值清零(zero out),相当于从网络中随机删除一些神经元,从而降低网络复杂度,降低过拟合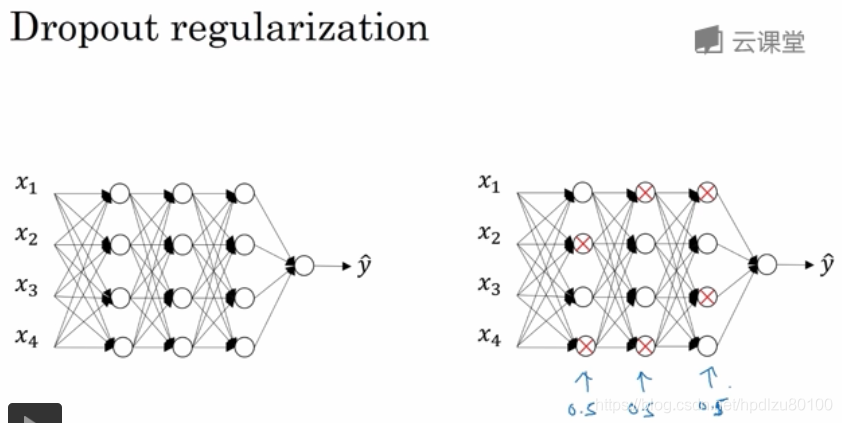
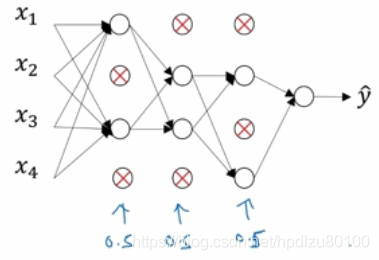
Inverted dropout(反向失活)的实现
仅需在训练时进行dropout,测试时不需要
1.7 理解 Dropout
为什么dropout有用?直观理解:任何一个特征都有可能被随机地“消除”,必须将权重分散到各个神经元,从而起到压缩权重(shrink weights)的作用。(注:这段描述不是很理解)
1.8 其他正则化方法
数据增广(利用现有数据,创建新数据,扩增训练集,防止过拟合)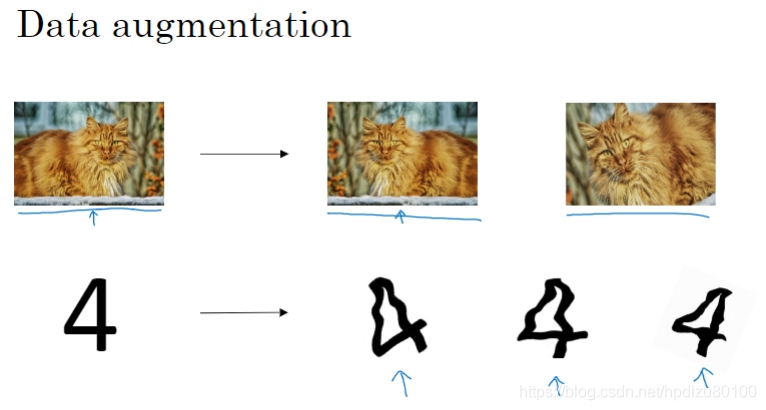
早停(提前停止迭代,训练准确度会下降,但验证集准确度反而会提高,即,防止了过拟合)
早停的不好之处:将成本函数的优化和防止过拟合这两个任务耦合在了一起,并不符合通用的“正交化”方法,即将成本函数优化和过拟合看作两个互不相干的任务,分开执行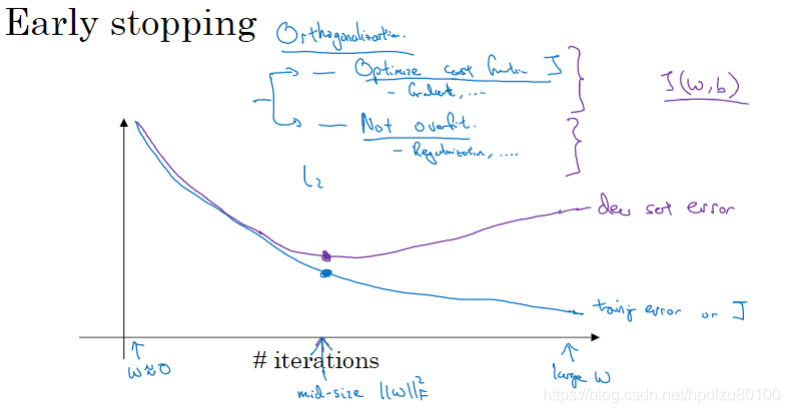
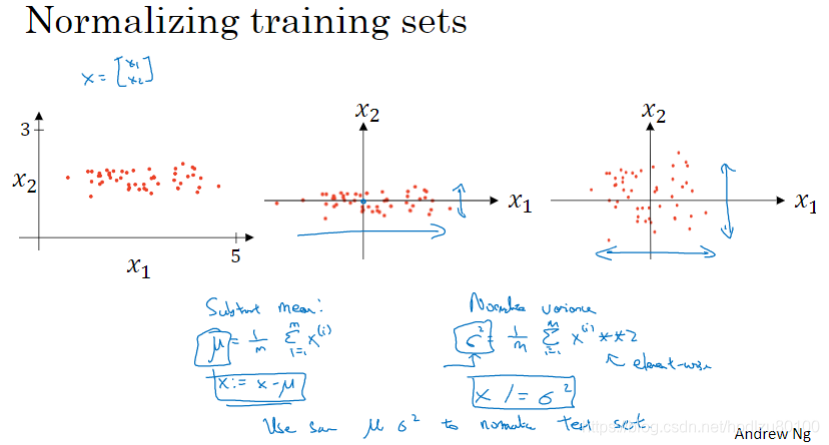
1.9 数据归一化(规范化)
训练集的归一化示例
- 零均值化——训练集特征值减去其平均值
- 求特征值平方均值
- 零均值化后的特征值除以特征值平方均值
为什么需要归一化输入值(特征值)?
可以提高训练速度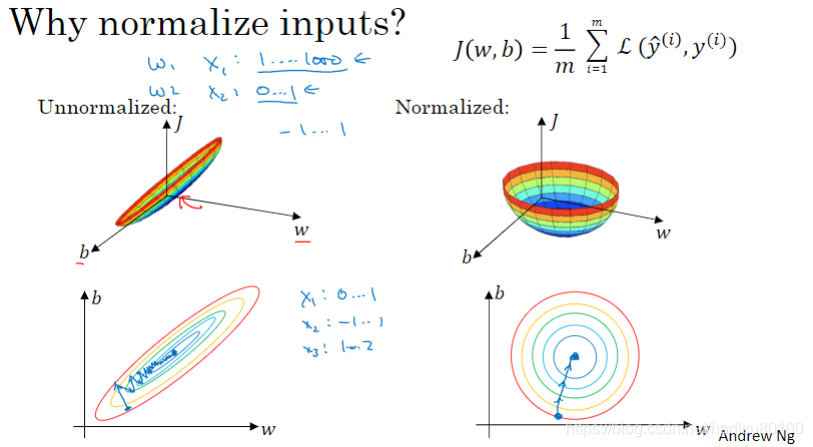

若有收获,就点个赞吧
0 人点赞
