前言
我们经常会发现有时有大量的虚假信息或者刷量用户,造成了信息的干扰以及趋势的不正确分析,因此根据数据来分析出哪些用户是真实用户,哪些不真实是产品的基本功。
刷量工作室的方式
他们可能是采用分布式人肉刷量的方式来刷量(形式可以参考基于任务的积分墙);也有可能是采用更为智能的方式,通过编写程序脚本,修改真机参数,驱动真机运行(有兴趣的同学可以了解一下 igrimace 这个 iOS 的刷量工具)。这些行为已经跟真实的用户行为几乎没有差别了,统计平台也很难从技术上分辨这些数据。
如何鉴别
渠道的留存率
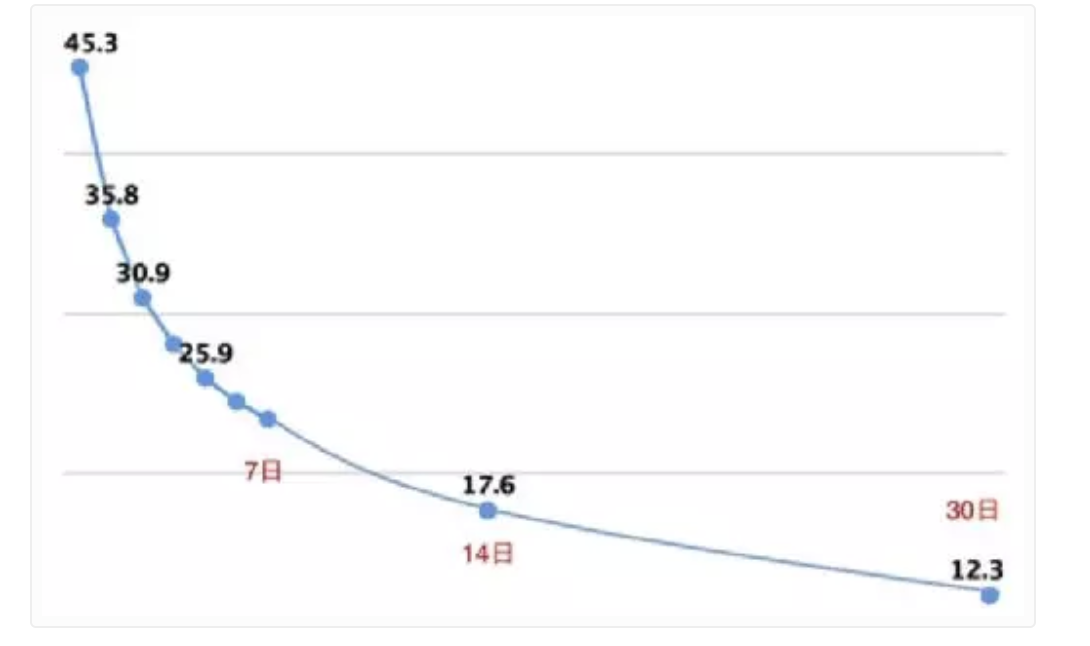
真实的用户的留存曲线是一条平滑的指数衰减曲线,如果你发现你的留存曲线存在陡升陡降的异常波动,基本上就是渠道干预了数据。可想而知,这样的用户的质量是非常差的,也不具备商业价值。(留存是指首次访问后再次访问的统计记录)。
而刷量的留存率一般是只在关键的规律节点进行访问,在这些节点上的数据明显高于其他。比如(次日,7日,30日)。
用户终端
每种渠道都有自己的用户群,一般情况下使用群体的分布是和互联网的设备分布类似的,如果不是,那可能就是有问题的。或者也有种可能是用户群体比较典型。
我们需要关注的终端特征有:终端型号、操作系统、联网方式、运营商、地理位置这些手机设备的属性。
我们需要重点关注的以下几个方向:
分析用户行为
关注用户行为数据
如果一个app运营时间比较久,访问页面、使用时长、访问间隔、使用频率等这些行为数据会趋向稳定的。刷量的工作室可以刷出真实用户的行为,但不能保证其符合app趋于稳定的规律。
所以一个渠道用户的使用时长、使用频率过高过低都值得怀疑。我们在平时做渠道数据分析时,可以将这些数据跟整个 App 作比较,或者将安卓市场、应用宝这些大型应用商店的数据作为基准数据,进行比较。
了解新增用户、活跃用户小时时间点数据曲线
**很多刷量工作室通过批量导入设备数据或者定时启动的方式来伪造数据。这种情况下,新增和启动的曲线会出现陡增和陡降。真实用户的新增和启动是一条平滑的曲线。一般来说,用户的新增和启动会在下午 6 点之后达到高峰。而且新增相比启动的趋势会更加明显。
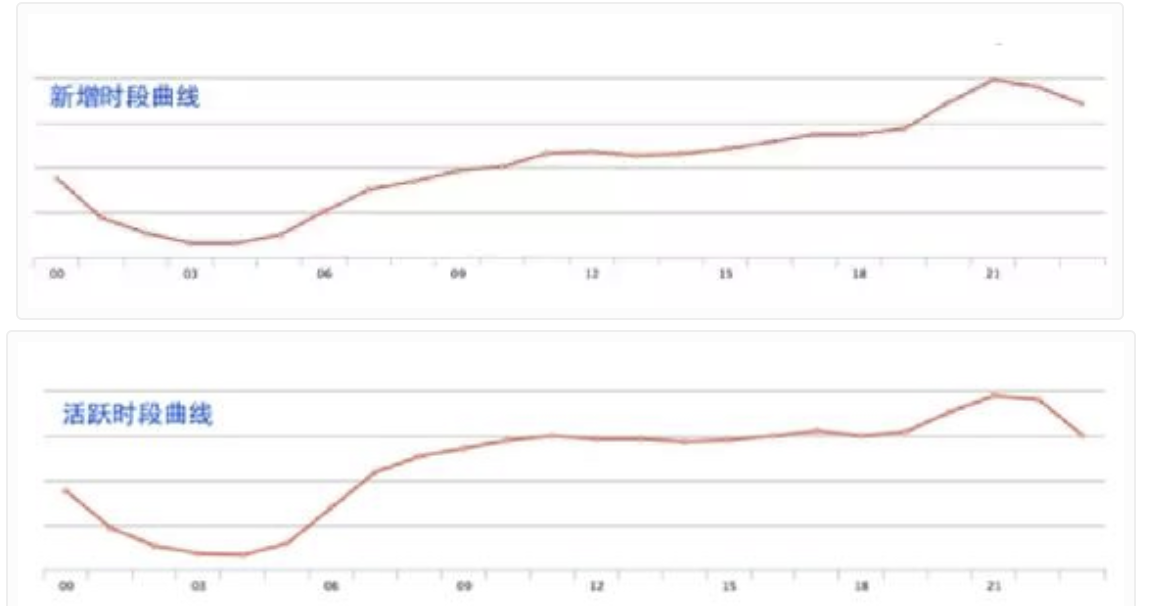
我们可以将不同渠道的分时数据进行对比,找到异常。需要注意的是,这种行为数据的对比需要遵循单一变量原则。也就是说,除了是不同的渠道,实验中的其他因素必须完全相同。如果我们选取渠道 A 在周三的活跃数和渠道 B 在周六的活跃数做对比,这两个数据肯定是有差异的,不具备可比性。
查看用户访问的页面名称明细
通过对具体页面的uv,pv,分析我们得出更加具体的数据来说明某些用户的真实性。
转化率
对于所有的app,都有其标准的业务流程,流程越长,越难模拟;达到某种标准越复杂,其越难造假。我们可以定义一些标准状态的数据,或者完善用户的等级,来区分出真正对我们有意义、有转化存在的用户。
如果一个用户是真实的流量,他会经历点击、下载、激活、注册、直到触发目标行为的过程。我们可以将这些步骤做成漏斗模型,观察每一步的转化率。漏斗的步骤越靠后,作弊的难度越大,所获取用户对系统的价值越高,同时我们付出的用户成本也越高。运营人员需要对目标行为进行监控,在渠道推广时,考察目标行为的转化率,提高渠道作弊的边际成本。
比较常见的行为是,在有些文章发布、关键操作、支付操作的节点上增加了智能识别、验证码确认等环节,提高程序可替代难度。
定义非标准用户模型
研发人员开发自己的反作弊模块。我们可以定义一些行为模式,加到反作弊模块的黑名单库中。如果一个新增设备满足定义的行为模式,就会被判定为一个作弊设备。
- 设备号异常:频繁重置 idfa
- ip 异常:频繁更换地理位置
- 行为异常:大量购买特价商品等
- 数据包不完整:只有启动信息,不具备页面、事件等其他用户行为信息
参考文章

若有收获,就点个赞吧
0 人点赞
