数据库递增
可以通过关系型数据库的自增主键产生唯一的ID,现在流行的商业数据库都支持自增主键的特性,比如mysql等。
一些nosql数据库也提供类似特性,比如Redis。
优点
- 容易产生
- 可读性好,容易记住
-
缺点
需要中心化的服务器,并且需要处理单节点的问题,而且有性能瓶颈的问题。
- 如果ID暴露给公共访问,会泄露商业机密,通过减法获取每日单量
- 需要访问一次数据库获取ID
实现
我们需要专门创建一个表来存放id,
表可以设计成以下样子:
在每次新增的时候,先向该表新增一条数据,然后获取返回新增的主键作为要插入的主键Id,我们可以使用下面的语句生成并获取到一个自增IDCREATE TABLE SEQID.SEQUENCE_ID (id bigint(20) unsigned NOT NULL auto_increment,stub char(10) NOT NULL default '',PRIMARY KEY (id),UNIQUE KEY stub (stub));
可能很多人读到这儿有些疑惑,stub是干嘛的?begin;replace into SEQUENCE_ID (stub) VALUES ('anyword'); -- SELECT DELETE INSERTselect last_insert_id();commit;
stub字段在这里并没有什么特殊的意义,只是为了方便的去插入数据,只有能插入数据才能产生自增id。
而对于插入我们用的是replace,replace会先看是否存在stub指定值一样的数据,如果存在则先delete再insert,如果不存在则直接insert。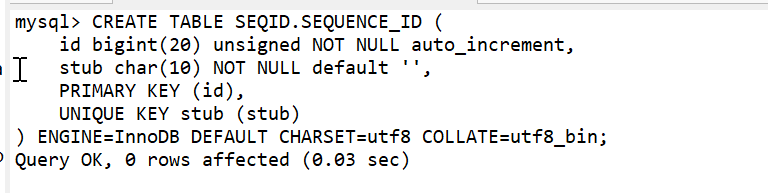

无论执行几次,该数据就只有一条,并且自增id。

这种生成分布式ID的机制,需要一个单独的Mysql实例,虽然可行,但是基于性能与可靠性来考虑的话都不够,业务系统每次需要一个ID时,都需要请求数据库获取,性能低,并且如果此数据库实例下线了,那么将影响所有的业务系统。

若有收获,就点个赞吧
0 人点赞
