我们可以换个角度来对分布式ID进行思考,只要能让负责生成分布式ID的每台机器在每毫秒内生成不一样的ID就行了。
snowflake是twitter开源的分布式ID生成算法,是一种算法,所以它和上面的三种生成分布式ID机制不太一样,它不依赖数据库。
核心思想是:分布式ID固定是一个long型的数字,一个long型占8个字节,也就是64个bit,原始snowflake算法中对于bit的分配如下图:
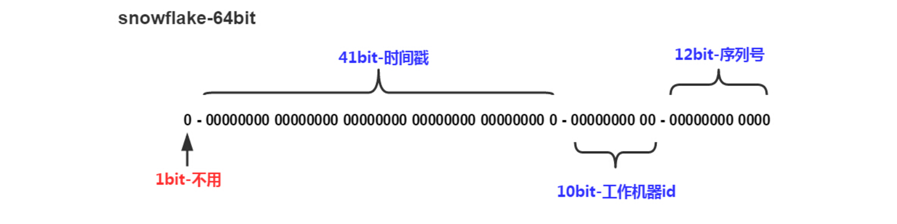
- 符号位为0,0表示正数,ID为正数,所以固定为0。
- 时间戳位不用多说,用来存放时间戳,单位是ms,时间戳部分占41bit,这个是毫秒级的时间,一般实现上不会存储当前的时间戳,而是时间戳的差值(当前时间-固定的开始时间),这样可以使产生的ID从更小值开始。
- 工作机器id位用来存放机器的id,通常分为5个区域位+5个服务器标识位。这里比较灵活,比如,可以使用前5位作为数据中心机房标识,后5位作为单机房机器标识,可以部署1024个节点。
- 序号位是自增。
雪花算法能存放多少数据?
- 时间范围:2^41 / (1000L 60 60 24 365) = 69年
- 工作进程范围:2^10 = 1024
- 序列号范围:2^12 = 4096,表示1ms可以生成4096个ID。
根据这个算法的逻辑,只需要将这个算法用Java语言实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用。下面是推特版的Snowflake算法:
public class SnowFlake {/*** 起始的时间戳*/private final static long START_STMP = 1480166465631L;/*** 每一部分占用的位数*/private final static long SEQUENCE_BIT = 12; //序列号占用的位数private final static long MACHINE_BIT = 5; //机器标识占用的位数private final static long DATACENTER_BIT = 5;//数据中心占用的位数/*** 每一部分的最大值*/private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);/*** 每一部分向左的位移*/private final static long MACHINE_LEFT = SEQUENCE_BIT;private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;private long datacenterId; //数据中心private long machineId; //机器标识private long sequence = 0L; //序列号private long lastStmp = -1L;//上一次时间戳public SnowFlake(long datacenterId, long machineId) {if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");}if (machineId > MAX_MACHINE_NUM || machineId < 0) {throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");}this.datacenterId = datacenterId;this.machineId = machineId;}/*** 产生下一个ID** @return*/public synchronized long nextId() {long currStmp = getNewstmp();if (currStmp < lastStmp) {throw new RuntimeException("Clock moved backwards. Refusing to generate id");}if (currStmp == lastStmp) {//相同毫秒内,序列号自增sequence = (sequence + 1) & MAX_SEQUENCE;//同一毫秒的序列数已经达到最大if (sequence == 0L) {currStmp = getNextMill();}} else {//不同毫秒内,序列号置为0sequence = 0L;}lastStmp = currStmp;return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分| datacenterId << DATACENTER_LEFT //数据中心部分| machineId << MACHINE_LEFT //机器标识部分| sequence; //序列号部分}private long getNextMill() {long mill = getNewstmp();while (mill <= lastStmp) {mill = getNewstmp();}return mill;}private long getNewstmp() {return System.currentTimeMillis();}public static void main(String[] args) {SnowFlake snowFlake = new SnowFlake(2, 3);for (int i = 0; i < (1 << 12); i++) {System.out.println(snowFlake.nextId());}}}
在实际的线上使用场景里,其实很少有直接使用snowflake,而是进行了改造,因为snowflake算法中最难实践的就是工作机器id,原始的snowflake算法需要人工去为每台机器去指定一个机器id,并配置在某个地方从而让snowflake从此处获取机器id。
尤其是机器是很多的时候,人力成本太大且容易出错,所以目前很多大厂对snowflake进行了改造。
优点

若有收获,就点个赞吧
0 人点赞
