本地事务和分布式事务区别
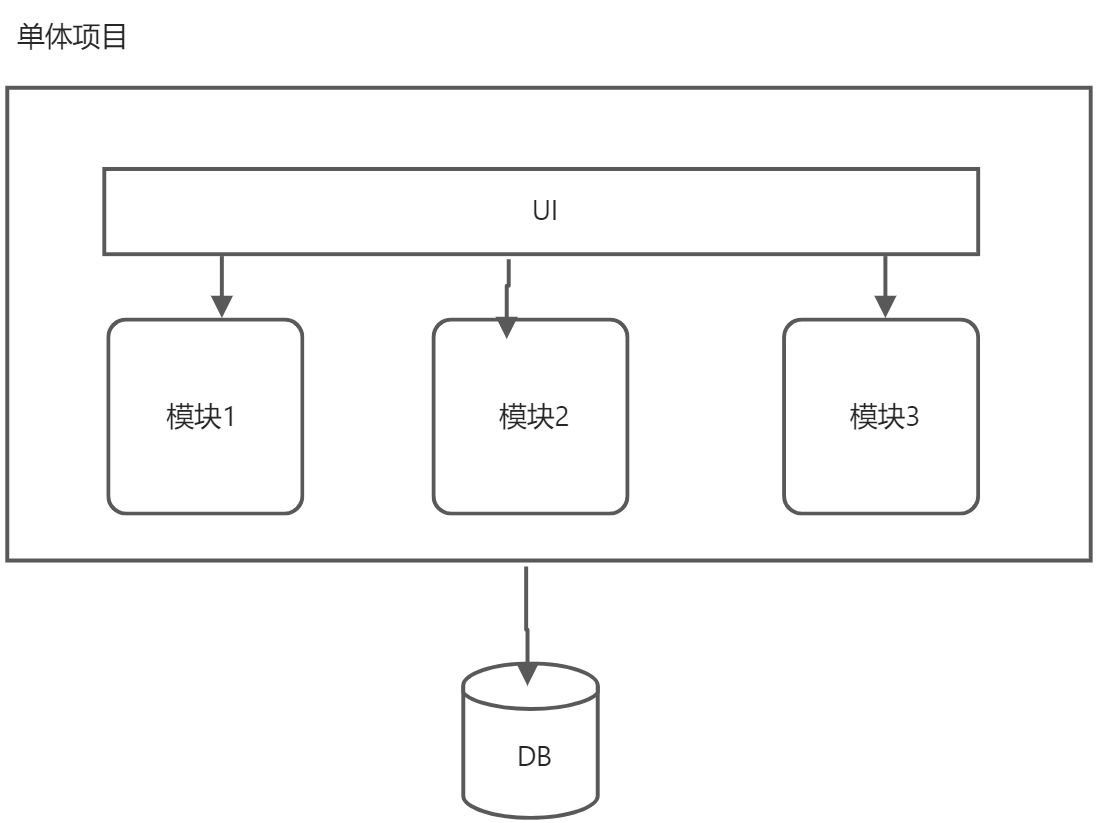
分布式系统会把一个应用系统拆分为可独立部署的多个服务,因此需要服务与服务之间远程协作才能完成事务操作,这种分布式系统环境下由不同的服务之间通过网络远程协作完成事务称之为分布式事务,例如用户注册送积分事务、创建订单减库存事务,银行转账事务等都是分布式事务。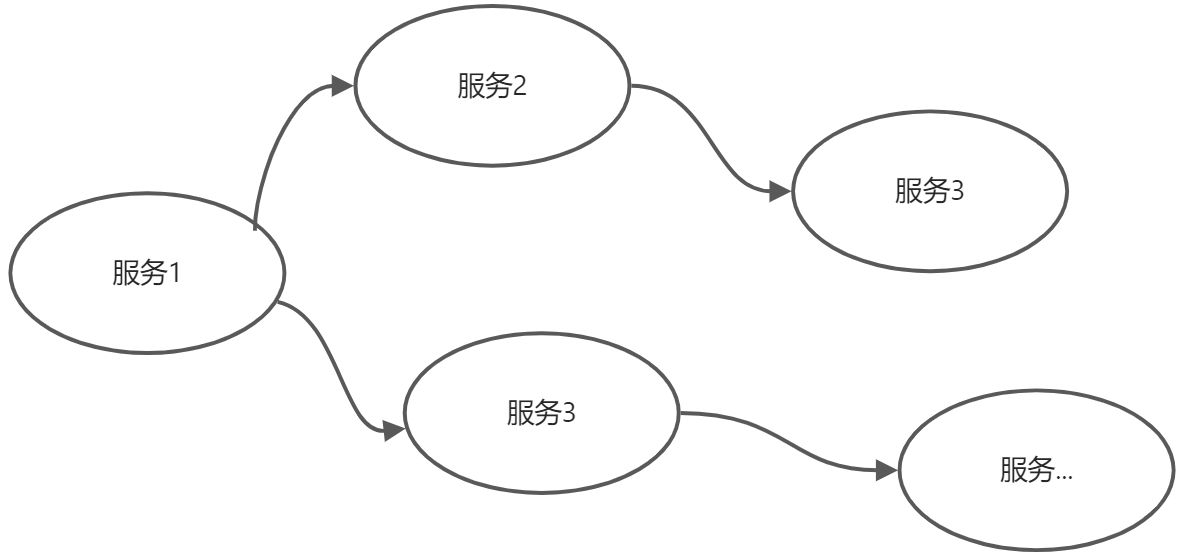
数据库事务命令:
begin transation;// 1.本地数据库操作:张三减少金额// 2.本地数据库操作:李四增加金额commit transation;
但是在分布式环境下,会变成下边这样:
begin transation;// 1.本地数据库操作:张三减少金额// 2.远程调用:李四增加金额commit transation;
问题:
当远程调用让李四增加金额成功了,由于网络问题远程调用并没有返回,此时本地事务提交失败就回滚了张三减少金额的操作,此时张三和李四的数据就不一致了。
因此在分布式架构的基础上,传统数据库事务就无法使用了,张三和李四的账户不在一个数据库中甚至不在一个应用系统里,实现转账事务需要通过远程调用,由于网络问题就会导致分布式事务问题。
分布式事务产生的场景
- 典型的场景就是微服务架构 微服务之间通过远程调用完成事务操作。
- 比如:订单微服务和库存微服务,下单的同时订单微服务请求库存微服务减库存。 简言之:跨JVM进程产生分布式事务。
- 单体系统访问多个数据库实例 当单体系统需要访问多个数据库(实例)时就会产生分布式事务。
- 比如:用户信息和订单信息分别在两个MySQL实例存储,用户管理系统删除用户信息,需要分别删除用户信息及用户的订单信息,由于数据分布在不同的数据实例,需要通过不同的数据库链接去操作数据,此时产生分布式事务。 简言之:跨数据库实例产生分布式事务。
- 多服务访问同一个数据库实例
- 比如:订单微服务和库存微服务即使访问同一个数据库也会产生分布式事务,原因就是跨JVM进程,两个微服务持有了不同的数据库链接进行数据库操作,此时产生分布式事务。
分布式事务基础理论
通过前面的学习,我们了解到了分布式事务的基础概念。与本地事务不同的是,分布式系统之所以叫分布式,是因为提供服务的各个节点分布在不同机器上,相互之间通过网络交互。不能因为有一点网络问题就导致整个系统无法提供服务,网络因素成为了分布式事务的考量标准之一。因此,分布式事务需要更进一步的理论支持,接下来,我们先来学习一下分布式事务的CAP理论。
在讲解分布式事务控制解决方案之前需要先学习一些基础理论,通过理论知识指导我们确定分布式事务控制的目标,从而帮助我们理解每个解决方案。
- 比如:订单微服务和库存微服务即使访问同一个数据库也会产生分布式事务,原因就是跨JVM进程,两个微服务持有了不同的数据库链接进行数据库操作,此时产生分布式事务。

若有收获,就点个赞吧
0 人点赞
