集群规划
| 服务器IP | 192.168.227.133 | 192.168.227.135 | 192.168.227.136 |
|---|---|---|---|
| 主机名 | node1 | node2 | node3 |
| NameNode | 是 | 否 | 否 |
| SecondaryNameNode | 是 | 否 | 否 |
| dataNode | 是 | 是 | 是 |
| ResourceManager | 是 | 否 | 否 |
| NodeManager | 是 | 是 | 是 |
下载
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/
解压和上传
cd /usr/local/src/hadooptar -zxvf hadoop-3.2.2.tar.gz
修改hosts文件
vi /etc/sysconfig/network
然后重启 reboot
修改环境变量
vi /etc/profileexport HADOOP_HOME=/usr/local/src/hadoop/hadoop-3.3.2export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource /etc/profile
vi /etc/selinux/config
改为
SELINUX=disabled
创建hadoop生成的存放位置
cd /usr/local/src/hadoop/hadoop-3.3.2/mkdir -p data
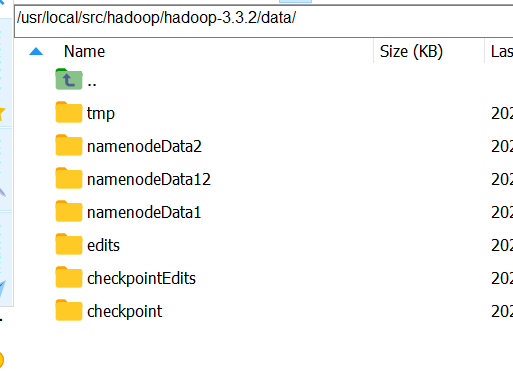
修改配置文件
找到/etc/hadoop/core-site.xml
<configuration><property><name>fs.default.name</name><value>hdfs://node1:8020</value></property><property><name>hadoop.tmp.dir</name><value>/usr/local/src/hadoop/hadoop-3.3.2/data/tmp</value></property><property><name>io.file.buffer.size</name><value>4096</value></property><property><name>fs.trash.interval</name><value>10080</value></property></configuration>
mapred-site.xml
<configuration><property><name>mapreduce.job.ubertask.enable</name><value>true</value></property><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value></property></configuration>
hdfs-site.xml
<configuration><property><name>dfs.namenode.secondary.http-address</name><value>node1:50090</value></property><property><name>dfs.namenode.http-address</name><value>node1:50070</value></property><property><name>dfs.namenode.name.dir</name><value>file:///usr/local/src/hadoop/hadoop-3.3.2/data/namenodeData1,file:///usr/local/src/hadoop/hadoop-3.3.2/data/namenodeData2</value></property><property><name>dfs.datanode.data.dir</name><value>file:///usr/local/src/hadoop/hadoop-3.3.2/data/datanodeData1,file:///usr/local/src/hadoop/hadoop-3.3.2/data/datanodeData2</value></property><property><name>dfs.namenode.edits.dir</name><value>file:///usr/local/src/hadoop/hadoop-3.3.2/data/edits</value></property><property><name>dfs.namenode.checkpoint.dir</name><value>file:///usr/local/src/hadoop/hadoop-3.3.2/data/checkpoint</value></property><property><name>dfs.namenode.checkpoint.edits.dir</name><value>file:///usr/local/src/hadoop/hadoop-3.3.2/data/checkpointEdits</value></property><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.permissions</name><value>false</value></property><property><name>dfs.blocksize</name><value>134217728</value></property></configuration>
yarn-site.xml
<configuration><property><name>yarn.resourcemanager.hostname</name><value>node1</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>20480</value></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>2048</value></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value></property></configuration>
hadoop-env.sh
JAVA_HOME=/usr/local/src/jdk/jdk1.8.0_331
mapred-env.sh
export JAVA_HOME=/usr/local/src/jdk/jdk1.8.0_331
修改root权限
stop-yarn.sh 和start-yarn.sh
#!/usr/bin/env bashYARN_RESOURCEMANAGER_USER=rootHADOOP_SECURE_DN_USER=yarnYARN_NODEMANAGER_USER=root
stop-dfs.sh和start-dfs.sh
#!/usr/bin/env bashHDFS_DATANODE_USER=rootHADOOP_SECURE_DN_USER=hdfsHDFS_NAMENODE_USER=rootHDFS_SECONDARYNAMENODE_USER=root
克隆
克隆完就是一些设置
将每个克隆出来的hosts修改,为对应的node名
然后再Windows修改hosts
C:\Windows\System32\drivers\etc
修改slaves
注意:hadoop版本是2x,需要修改这个文件,而3x版本需要修改workers,把localhost修改为下面的文本
第一台机器执行以下命令
cd /export/servers/hadoop-2.7.5/etc/hadoopvim slaves
node1node2node3
安装包的分发
第一台机器执行以下命令
cd /export/servers/scp -r hadoop-2.7.5 node2:$PWDscp -r hadoop-2.7.5 node3:$PWD
启动集群
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个模块。
注意: 首次启动 HDFS 时,必须对其进行格式化操作。 本质上是一些清理和
准备工作,因为此时的 HDFS 在物理上还是不存在的。
hdfs namenode -format 或者
hadoop namenode –format
启动
sbin/start-all.shsbin/mr-jobhistory-daemon.sh start historyserver
三个端口查看界面
http://node01:50070/explorer.html#/](http://node01:50070/explorer.html#/) 查看hdfs
http://node01:8088/cluster 查看yarn集群
http://node01:19888/jobhistory 查看历史完成的任务
正常启动图
只需要启动node1就可以了,其余虚拟机会自动启动,如果没有启动成功就要去检查那里没写对
node1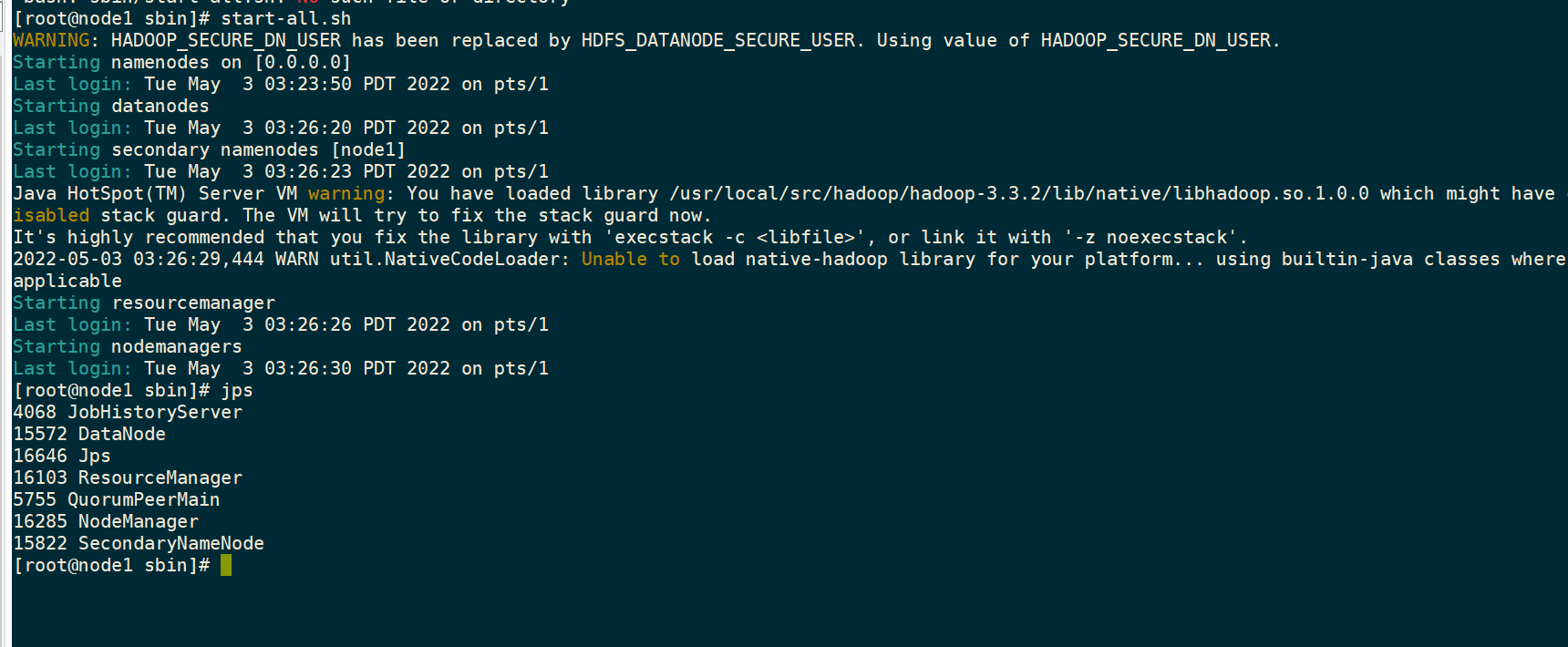
node2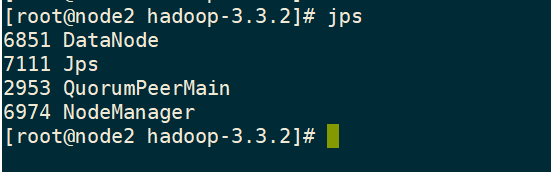
node3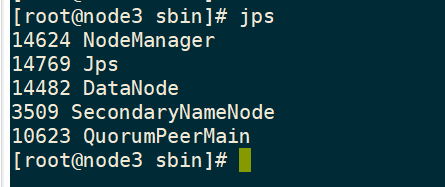

若有收获,就点个赞吧
0 人点赞
