一,Object类简述
Object类是Java中所有类的基类,在编译时会自动导入,位于java.lang包中,而Object中具有的属性和行为,是Java语言设计背后的思维体现。这里写的代码是JDK11中的,其他版本的JDK可能略有不同。
包含的方法如下图: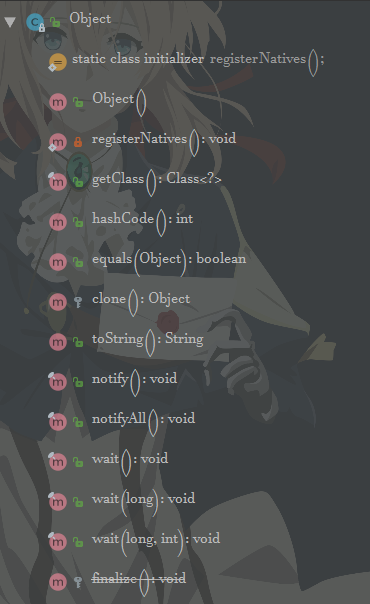
其中,两个protected方法没有实现,其他的都有;线程相关的方法以及getClass()不支持重写(自定义),其他的都支持
二、源码解析
1、registerNatives()方法
- 类首次加载时执行
初始化静态变量、调用静态方法
private static native void registerNatives();static {registerNatives();}
registerNatives如何找到调用C语言方法(OpenJDK)???
答:本地方法调用遵守JNI命名规范,即:要求本地方法名由 “Java”+“包名”+“方法名”构成
所以,该方法对应的关键字就是【 】
接下来我们全文检索一下: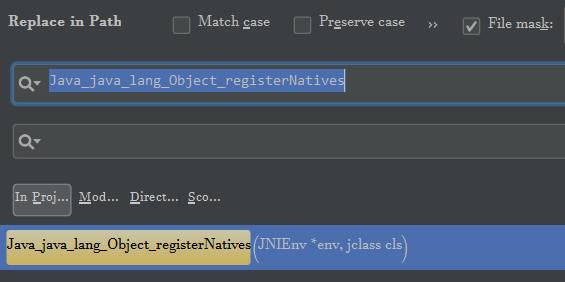
果然!找到该方法在Object.c里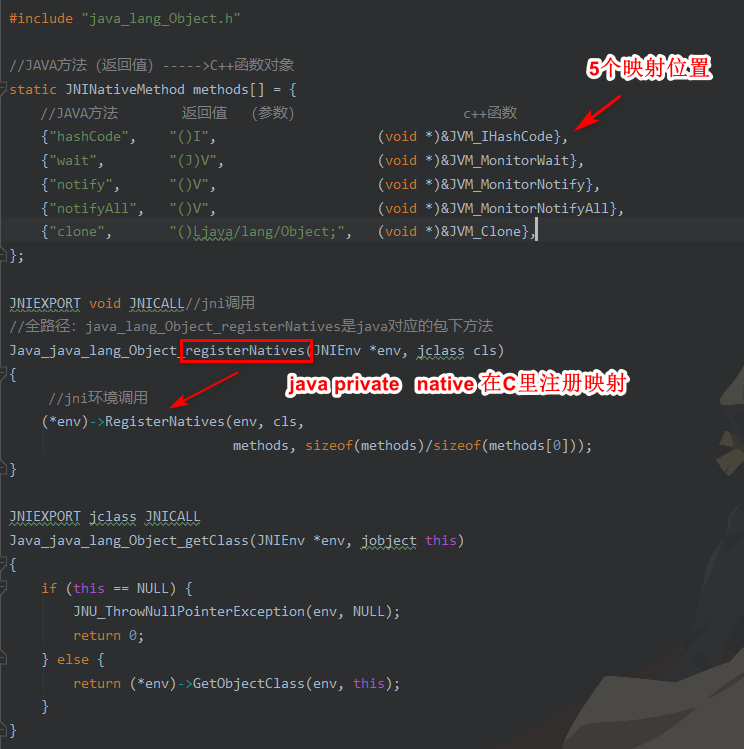
2、Object()构造方法
@HotSpotIntrinsicCandidate:在HotSpot中都有一套高效的实现,该高效实现基于CPU指令,运行时,HotSpot维护的高效实现会替代JDK的源码实现,从而获得更高的效率。
@HotSpotIntrinsicCandidatepublic Object() {}
3、getClass()方法
final,说明此方法不能被重写
- 返回Class对象,可用于反射进行处理
- Class对象表示运行时此对象的类
debug:经过一系列的String.class处理,启动一个线程类,最终跑到LauncherHelper.class,启动ClassLoader加载一个class,而后利用虚拟机的PostVMInitHook.class完成结果输出;
@HotSpotIntrinsicCandidatepublic final native Class<?> getClass();
4、hashCode()方法
返回对象的对象的哈希码,是一个整数。这个方法的好处是提供了对诸如HashMap等哈希表的支持。
- debug:hash code是经过String.class和BaseLocale.class重写的hashCode方法,不断计算得出。
hashCode到底是什么?是不是对象的内存地址?@HotSpotIntrinsicCandidatepublic native int hashCode();
1) 直接用内存地址?
目标:通过一个Demo验证这个hasCode到底是不是内存地址
```java import java.util.ArrayList; import java.util.List;public native int hashCode();
public class HashCodeTest {
//目标:只要发生重复,说明hashcode不是内存地址,但还需要证明(JVM代码证明)
public static void main(String[] args) {
List
}
}
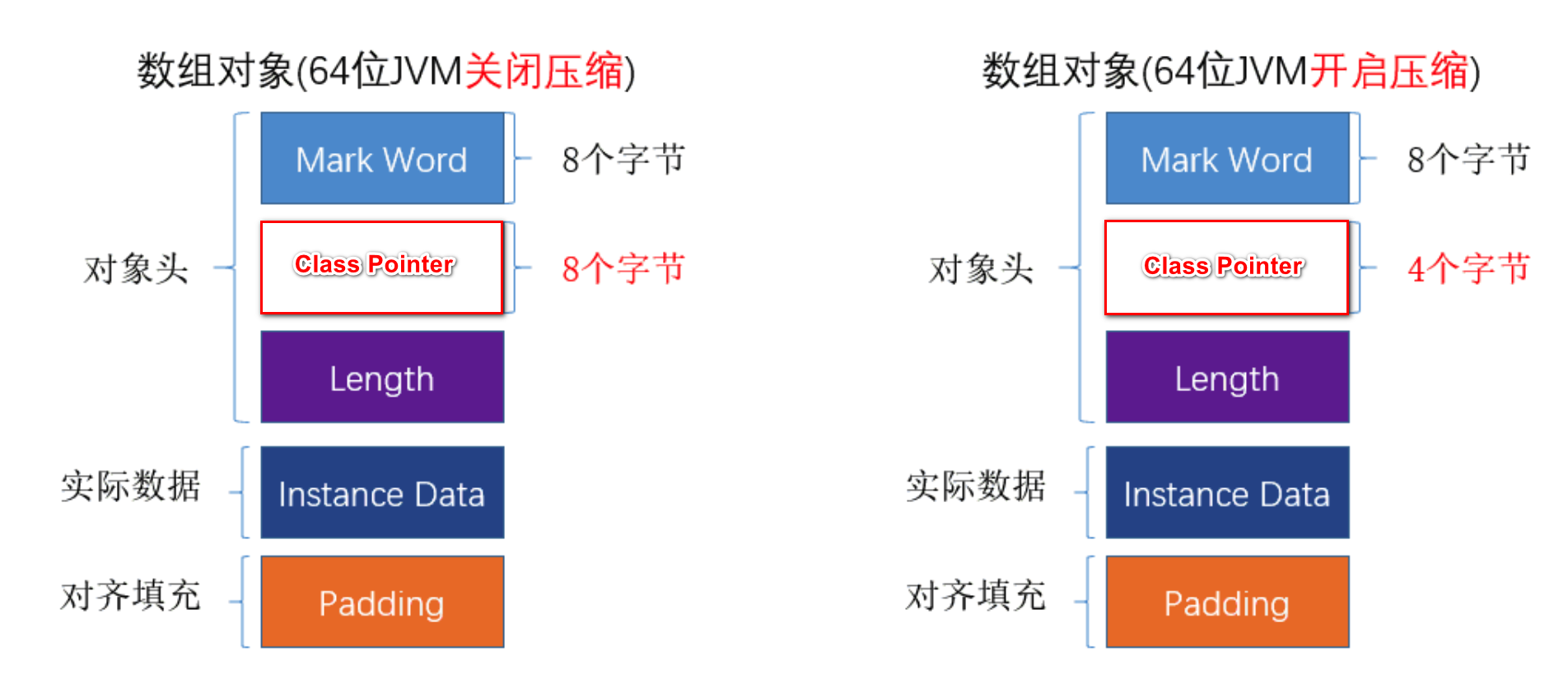
15万个循环,发生了重复,说明hashCode不是内存地址(严格的说,肯定不是直接取的内存地址)<br />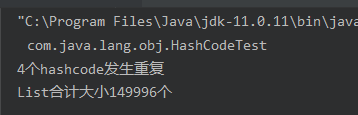<a name="e80b8a68"></a>#### 2) 不是地址那在哪里?既然不是内存地址,那一定在某个地方存着,那在哪里存着呢?答案:在对象头里!(画图。类在jvm内存中的布局)```java-XX:+UseCompressedOops // 开启指针压缩-XX:-UseCompressedOops // 关闭指针压缩
3) 什么时候生成的?
new的瞬间就有hashcode了吗??
show me the code!我们用代码验证
引入pom
<dependency><groupId>org.openjdk.jol</groupId><artifactId>jol-core</artifactId><version>0.9</version></dependency>
编写ShowHashCode
import org.openjdk.jol.info.ClassLayout;import org.openjdk.jol.vm.VM;public class ShowHashCode {public static void main(String[] args) {ShowHashCode a = new ShowHashCode();//jvm的信息System.out.println(VM.current().details());System.out.println("-------------------------");//调用之前打印a对象的头信息//以表格的形式打印对象布局System.out.println(ClassLayout.parseInstance(a).toPrintable());System.out.println("-------------------------");//调用后再打印a对象的hashcode值System.out.println(Integer.toHexString(a.hashCode()));System.out.println(ClassLayout.parseInstance(a).toPrintable());System.out.println("-------------------------");//有线程加重量级锁的时候,再来看对象头new Thread(()->{try {synchronized (a){Thread.sleep(5000);}} catch (InterruptedException e) {e.printStackTrace();}}).start();System.out.println(Integer.toHexString(a.hashCode()));System.out.println(ClassLayout.parseInstance(a).toPrintable());}}
结果分析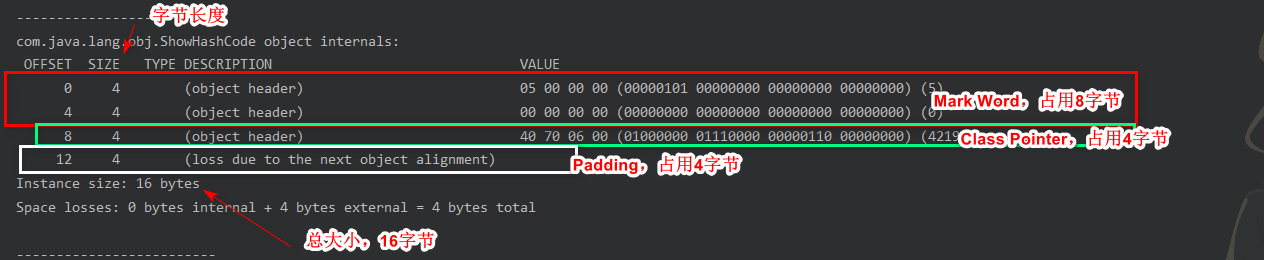
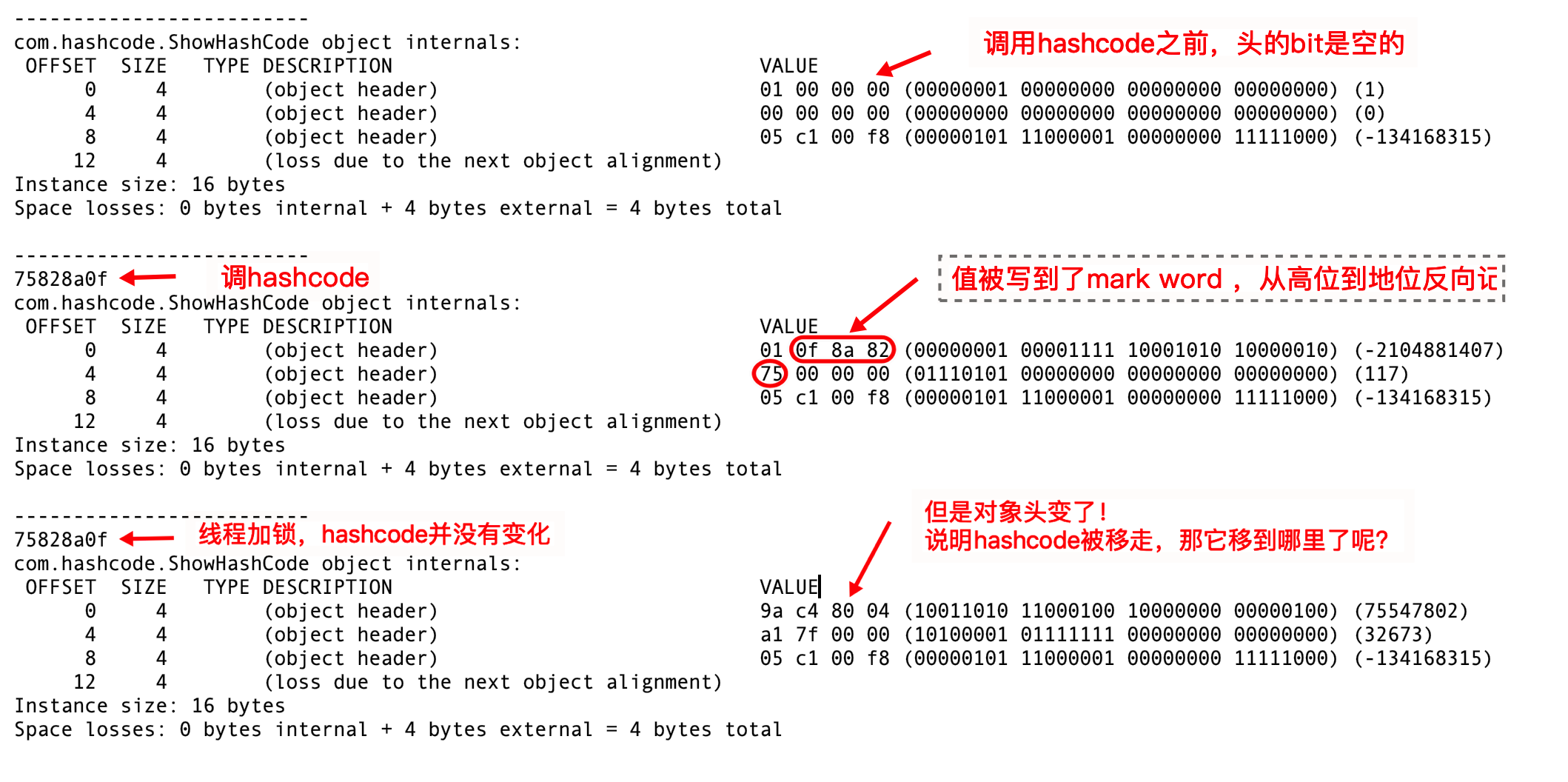
结论:在你没有调用的时候,这个值是空的,当第一次调用hashCode方法时,会生成,加锁以后,不知道去哪里了……
4) 怎么生成的?
接上文 , 我们追究一下,它详细的生成及移动过程。
我们都知道,这货是个本地方法
public native int hashCode();
那就需要借助上面提到的办法,通过JVM虚拟机源码,查看hashcode的生成
全局检索JVM_IHashCode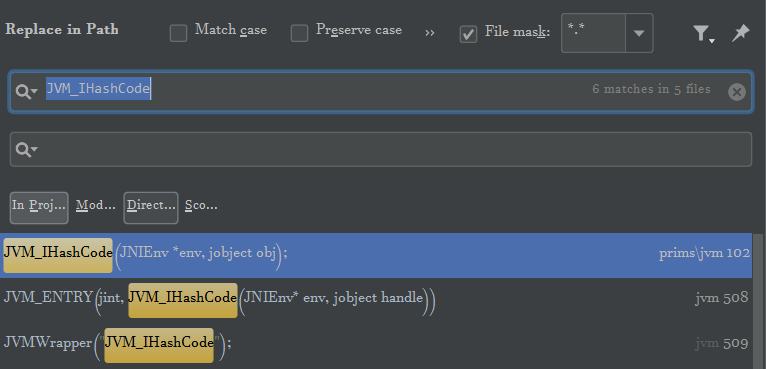
src\share\vm\prims\jvm.cpp
JVM_ENTRY是一个预加载宏,增加一些样板代码到jvm的所有function中
这个api是位于本地方法与jdk之间的一个连接层。
所以,此处才是生成hashCode的逻辑!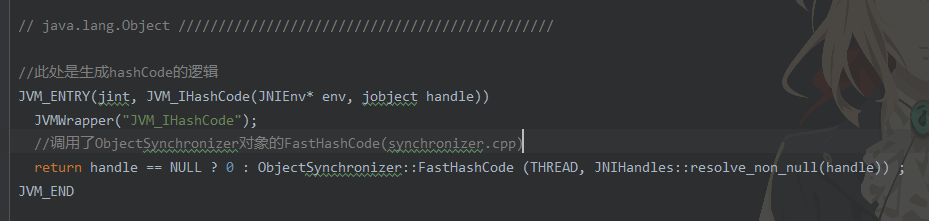
继续,ObjectSynchronizer::FastHashCode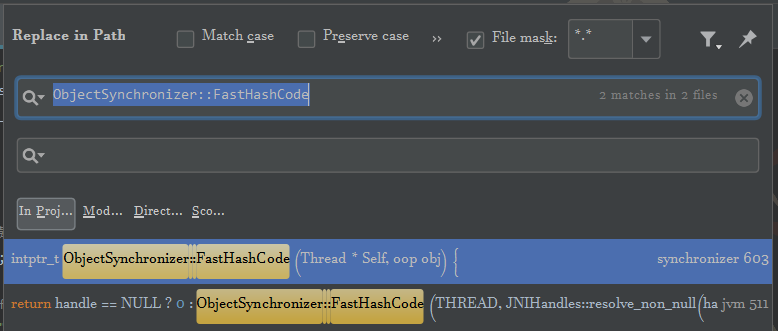

先说生成流程,留个印象: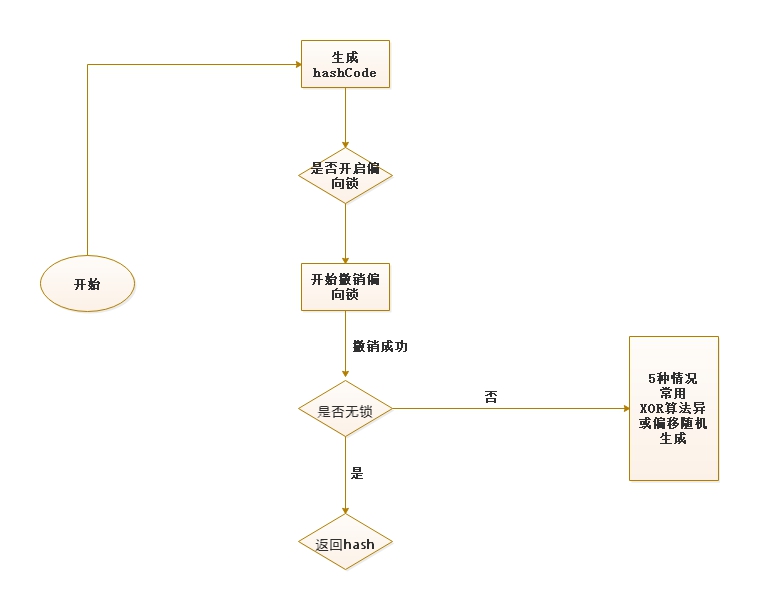
intptr_t ObjectSynchronizer::FastHashCode (Thread * Self, oop obj) {//是否开启了偏向锁(Biased:偏向,倾向)if (UseBiasedLocking) {//如果当前对象处于偏向锁状态if (obj->mark()->has_bias_pattern()) {Handle hobj (Self, obj) ;assert (Universe::verify_in_progress() ||!SafepointSynchronize::is_at_safepoint(),"biases should not be seen by VM thread here");//那么就撤销偏向锁(达到无锁状态,revoke:废除)BiasedLocking::revoke_and_rebias(hobj, false, JavaThread::current());obj = hobj() ;//断言下,看看是否撤销成功(撤销后为无锁状态)assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");}}// ……ObjectMonitor* monitor = NULL;markOop temp, test;intptr_t hash;//读出一个稳定的mark;防止对象obj处于膨胀状态;//如果正在膨胀,就等他膨胀完毕再读出来markOop mark = ReadStableMark (obj);//是否撤销了偏向锁(也就是无锁状态)(neutral:中立,不偏不斜的)if (mark->is_neutral()) {//从mark头上取hash值hash = mark->hash();//如果有,直接返回这个hashcode(xor)if (hash) { // if it has hash, just return itreturn hash;}//如果没有就新生成一个(get_next_hash)hash = get_next_hash(Self, obj); // allocate a new hash code//生成后,原子性设置,将hash放在对象头里去,这样下次就可以直接取了temp = mark->copy_set_hash(hash); // merge the hash code into header// use (machine word version) atomic operation to install the hashtest = (markOop) Atomic::cmpxchg_ptr(temp, obj->mark_addr(), mark);if (test == mark) {return hash;}// If atomic operation failed, we must inflate the header// into heavy weight monitor. We could add more code here// for fast path, but it does not worth the complexity.//如果已经升级成了重量级锁,那么找到它的monitor//也就是我们所说的内置锁(objectMonitor),这是c里的数据类型//因为锁升级后,mark里的bit位已经不再存储hashcode,而是指向monitor的地址//而升级的markword呢?被移到了c的monitor里} else if (mark->has_monitor()) {//沿着monitor找header,也就是对象头monitor = mark->monitor();temp = monitor->header();assert (temp->is_neutral(), "invariant") ;//找到header后取hash返回hash = temp->hash();if (hash) {return hash;}// Skip to the following code to reduce code size} else if (Self->is_lock_owned((address)mark->locker())) {//轻量级锁的话,也是从java对象头移到了c里,叫helpertemp = mark->displaced_mark_helper(); // this is a lightweight monitor ownedassert (temp->is_neutral(), "invariant") ;hash = temp->hash(); // by current thread, check if the displaced//找到,返回if (hash) { // header contains hash codereturn hash;}}......略
问:
为什么要先撤销偏向锁到无锁状态,再来生成hashcode呢?这跟锁有什么关系?
答:
mark word里,hashcode存储的字节位置被偏向锁给占了!偏向锁存储了锁持有者的线程id
扩展:关于hashCode的生成算法(了解)
// hashCode() generation :// 涉及到c++算法领域,感兴趣的同学自行研究// Possibilities:// * MD5Digest of {obj,stwRandom}// * CRC32 of {obj,stwRandom} or any linear-feedback shift register function.// * A DES- or AES-style SBox[] mechanism// * One of the Phi-based schemes, such as:// 2654435761 = 2^32 * Phi (golden ratio)// HashCodeValue = ((uintptr_t(obj) >> 3) * 2654435761) ^ GVars.stwRandom ;// * A variation of Marsaglia's shift-xor RNG scheme.// * (obj ^ stwRandom) is appealing, but can result// in undesirable regularity in the hashCode values of adjacent objects// (objects allocated back-to-back, in particular). This could potentially// result in hashtable collisions and reduced hashtable efficiency.// There are simple ways to "diffuse" the middle address bits over the// generated hashCode values://static inline intptr_t get_next_hash(Thread * Self, oop obj) {intptr_t value = 0 ;if (hashCode == 0) {// This form uses an unguarded global Park-Miller RNG,// so it's possible for two threads to race and generate the same RNG.// On MP system we'll have lots of RW access to a global, so the// mechanism induces lots of coherency traffic.value = os::random() ;//返回随机数} else if (hashCode == 1) {// This variation has the property of being stable (idempotent)// between STW operations. This can be useful in some of the 1-0// synchronization schemes.//和地址相关,但不是地址;右移+异或算法intptr_t addrBits = cast_from_oop<intptr_t>(obj) >> 3 ;value = addrBits ^ (addrBits >> 5) ^ GVars.stwRandom ;//随机数位移异或计算} else if (hashCode == 2) {value = 1 ; // 返回1} else if (hashCode == 3) {value = ++GVars.hcSequence ;//返回一个Sequence序列号} else if (hashCode == 4) {value = cast_from_oop<intptr_t>(obj) ;//也不是地址} else {//常用// Marsaglia's xor-shift scheme with thread-specific state// This is probably the best overall implementation -- we'll// likely make this the default in future releases.//马萨利亚教授写的xor-shift 随机数算法(异或随机算法)unsigned t = Self->_hashStateX ;t ^= (t << 11) ;Self->_hashStateX = Self->_hashStateY ;Self->_hashStateY = Self->_hashStateZ ;Self->_hashStateZ = Self->_hashStateW ;unsigned v = Self->_hashStateW ;v = (v ^ (v >> 19)) ^ (t ^ (t >> 8)) ;Self->_hashStateW = v ;value = v ;}
5)总结
通过分析虚拟机源码我们证明了hashCode不是直接用的内存地址,而是采取一定的算法来生成
hashcode值的存储在mark word里,与锁共用一段bit位,这就造成了跟锁状态相关性
- 如果是偏向锁:
一旦调用hashcode,偏向锁将被撤销,hashcode被保存占位mark word,对象被打回无锁状态
- 那偏偏这会就是有线程硬性使用对象的锁呢?
对象再也回不到偏向锁状态而是升级为重量级锁。hash code跟随mark word被移动到c的object monitor,从那里取
5、equals()方法
1) equals源码
- equals方法主要是比较两个对象是否相同,Object中的equals方法比较的是对象的地址是否相同。
猜想:如果我们不做任何操作,equals将继承object的方法,那么它和==也没啥区别!public boolean equals(Object obj) {// 比较的是两个对象的内存地址return (this == obj);}
下面一起做个面试题,验证一下这个猜想:
public class DefaultEq {String name;public DefaultEq(String name){this.name = name;}public static void main(String[] args) {DefaultEq eq1 = new DefaultEq("张三");DefaultEq eq2 = new DefaultEq("张三");DefaultEq eq3 = eq1;//虽然俩对象外面看起来一样,eq和==都不行//因为我们没有改写equals,它使用默认object的,也就是内存地址System.out.println(eq1.equals(eq2));System.out.println(eq1 == eq2);System.out.println("----");//1和3是同一个引用System.out.println(eq1.equals(eq3));System.out.println(eq1 == eq3);System.out.println("===");//以上是对象,再来看基本类型int i1 = 1;Integer i2 = 1;Integer i = new Integer(1);Integer j = new Integer(1);Integer k = new Integer(2);//只要是基本类型,不管值还是包装成对象,都是直接比较大小System.out.println(i.equals(i1)); //比较的是值System.out.println(i==i1); //拆箱 ,// 封装对象i被拆箱,变为值比较,1==1成立//相当于 System.out.println(1==1);System.out.println(i.equals(j)); //System.out.println(i==j); // 比较的是地址,这是俩对象System.out.println(i2 == i); // i2在常量池里,i在堆里,地址不一样System.out.println(i.equals(k)); //1和2,不解释}}
结果
falsefalse----truetrue===truetruetruefalsefalsefalse
结论:
- “==”比较的是什么?
用于基本数据(8种)类型(或包装类型)相互比较,比较二者的值是否相等。
用于引用数据(类、接口、数组)类型相互比较,比较二者地址是否相等。 - equals比较的什么?
默认情况下,所有对象继承Object,而Object的equals比较的就是内存地址
所以默认情况下,这俩没啥区别2) 内存地址生成与比较
tips:既然没区别,那我们看一下,内存地址到底是个啥玩意
目标:内存地址是如何来的?
Main.java
public static void main(String[] args) {User user1=new User("张三");User user2=new User("张三");}
1、加载过程(回顾)
从java文件到jvm: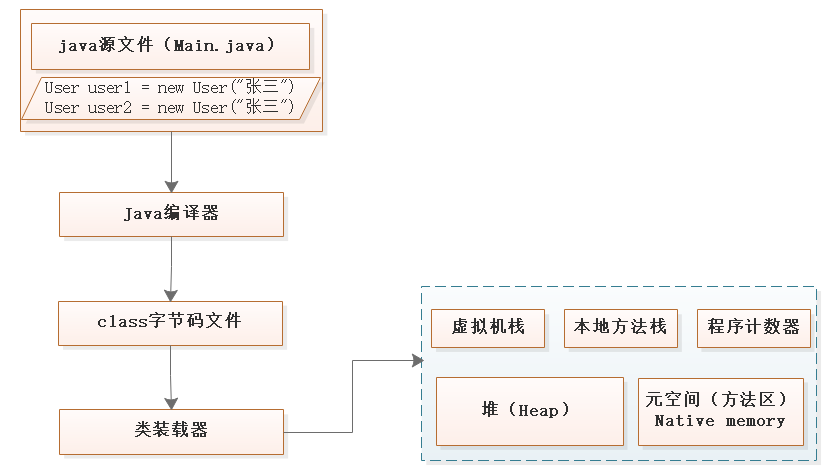
tips: 加载到方法区
这个阶段只是User类的信息进入方法区,还没有为两个user来分配内存
2、分配内存空间
在main线程执行阶段,指针碰撞(连续内存空间时),或者空闲列表(不连续空间)方式开辟一块堆内存
每次new一个,开辟一块,所以两个new之间肯定不是相同地址,哪怕你new的都是同一个类型的class。
那么它如何来保证内存地址不重复的呢?(cas画图)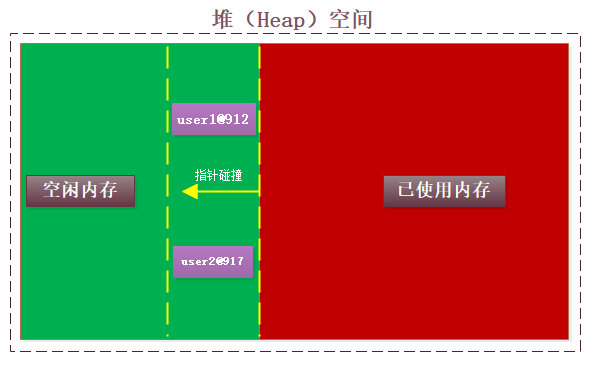
3、指向
在栈中创建两个局部变量 user1,user2,指向堆里的内存
归根到底,上面的==比较的是两个对象的堆内存地址,也就是栈中局部变量表里存储的值。
public boolean equals(Object obj) {return (this == obj);//本类比较的是内存地址(引用)}
6、Clone()方法
- clone方法是创建并且返回一个对象的复制之后的结果。复制的含义取决于对象的类定义。
// 一般在原型模式时使用// 使用时需要让被拷贝的对象所属的类实现Cloneable接口,才能调用该方法进行拷贝。@HotSpotIntrinsicCandidateprotected native Object clone() throws CloneNotSupportedException;
6.1 浅拷贝
准备一个房子对象
public class House {private String addr;public House(String addr) {this.setAddr(addr);}public String getAddr() {return addr;}public void setAddr(String addr) {this.addr = addr;}}
准备一个人对象,并重写clone()方法
public class Person implements Cloneable {private String name;private House house;@Overridepublic Object clone() {// 浅拷贝Object obj=null;//调用Object类的clone方法,返回一个Object实例try {obj= super.clone();} catch (CloneNotSupportedException e) {e.printStackTrace();}return obj;}public Person(String name, House house) {this.name = name;this.house = house;}public String getName() {return name;}public void setName(String name) {this.name = name;}public House getHouse() {return house;}public void setHouse(House house) {this.house = house;}}
测试
public class ShallowClone {public static void main(String[] args) {House house = new House("地址");Person person = new Person("名字", house);Person personClone = (Person) person.clone();// 未修改的场合System.out.println(person.getHouse().getAddr());System.out.println(personClone.getHouse().getAddr());// 修改原对象属性,发现属性值跟着变化person.getHouse().setAddr("新地址");System.out.println(person.getHouse().getAddr());System.out.println(personClone.getHouse().getAddr());// 修改复制对象的属性,发现属性值照样跟着变化personClone.getHouse().setAddr("旧地址");System.out.println(person.getHouse().getAddr());System.out.println(personClone.getHouse().getAddr());}}
结果
地址地址新地址新地址旧地址旧地址
结论
准备一个房子对象,并重写clone()方法
public class House implements Cloneable{private String addr;public House(String addr) {this.setAddr(addr);}public String getAddr() {return addr;}public void setAddr(String addr) {this.addr = addr;}@Overridepublic Object clone() {Object obj = null;try {obj = super.clone();} catch (CloneNotSupportedException e) {e.printStackTrace();}return obj;}}
创建一个人的对象,并引用房子对象的clone方法
public class Person implements Cloneable {private String name;private House house;@Overridepublic Object clone() {// 浅拷贝Object obj=null;//调用Object类的clone方法,返回一个Object实例try {obj= super.clone();} catch (CloneNotSupportedException e) {e.printStackTrace();}Person person = (Person) obj;person.house = (House) person.getHouse().clone();return obj;}public Person(String name, House house) {this.name = name;this.house = house;}public String getName() {return name;}public void setName(String name) {this.name = name;}public House getHouse() {return house;}public void setHouse(House house) {this.house = house;}}
测试
public class ShallowClone {public static void main(String[] args) {House house = new House("地址");Person person = new Person("名字", house);Person personClone = (Person) person.clone();// 未修改的场合System.out.println(person.getHouse().getAddr());System.out.println(personClone.getHouse().getAddr());// 修改原对象属性,只有原对象属性值更改person.getHouse().setAddr("新地址");System.out.println(person.getHouse().getAddr());System.out.println(personClone.getHouse().getAddr());// 修改复制对象的属性,只有复制对象属性值更改personClone.getHouse().setAddr("旧地址");System.out.println(person.getHouse().getAddr());System.out.println(personClone.getHouse().getAddr());}}
结果
地址地址新地址地址新地址旧地址
结论
进行了深拷贝之后,无论是什么类型的属性值的修改,都不会影响另一个对象的属性值。
6.3 浅拷贝和深拷贝区别
浅拷贝: 浅拷贝是按位拷贝对象,它会创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),拷贝的就是内存地址 ,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。
深拷贝: 深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。7、toString()方法
返回方法名和十六位进制的hashcode,格式:com.java.lang.obj.Person@1d251891
public String toString() {// 用于显示该对象的内容// 一般需要重写return getClass().getName() + "@" + Integer.toHexString(hashCode());}
8、notify()方法
final,说明此方法不能被重写
// 唤醒对象的等待队列上的 一个线程@HotSpotIntrinsicCandidatepublic final native void notify();
9、notifyAll()方法
final,说明此方法不能被重写
// 唤醒所有 等待在这个对象的监视器上的线程@HotSpotIntrinsicCandidatepublic final native void notifyAll();
10、wait()方法
final,说明此方法不能被重写
// 使线程进入等待状态,直到被notify or notifyAll调用public final void wait() throws InterruptedException {wait(0L);}// 使线程在几秒钟内进入等待状态public final native void wait(long timeoutMillis) throws InterruptedException;// 使线程进入等待状态,直到被notify or notifyAll调用 or 等待时间达到限定值public final void wait(long timeoutMillis, int nanos) throws InterruptedException {if (timeoutMillis < 0) {throw new IllegalArgumentException("timeoutMillis value is negative");}if (nanos < 0 || nanos > 999999) {throw new IllegalArgumentException("nanosecond timeout value out of range");}if (nanos > 0) {timeoutMillis++;}wait(timeoutMillis);}
11、finalize()方法
@Deprecated(since="9")protected void finalize() throws Throwable { }

若有收获,就点个赞吧
0 人点赞
