号段模式是当下分布式ID生成器的主流实现方式之一,号段模式可以理解为从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,具体的业务服务将本号段,生成1~1000的自增ID并加载到内存。表结构如下:
CREATE TABLE id_generator (id int(10) NOT NULL,max_id bigint(20) NOT NULL COMMENT '当前最大id',step int(20) NOT NULL COMMENT '号段的布长',biz_type int(20) NOT NULL COMMENT '业务类型',version int(20) NOT NULL COMMENT '版本号',PRIMARY KEY (`id`))
biz_type :代表不同业务类型
max_id :当前最大的可用id
step :代表号段的长度
version :是一个乐观锁,每次都更新version,保证并发时数据的正确性(还能保证有序性)
等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,
update max_id= max_id + step
,update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]。
update id_generator set max_id = #{max_id+step}, version = version + 1where version = # {version} and biz_type = XXX
由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新,这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。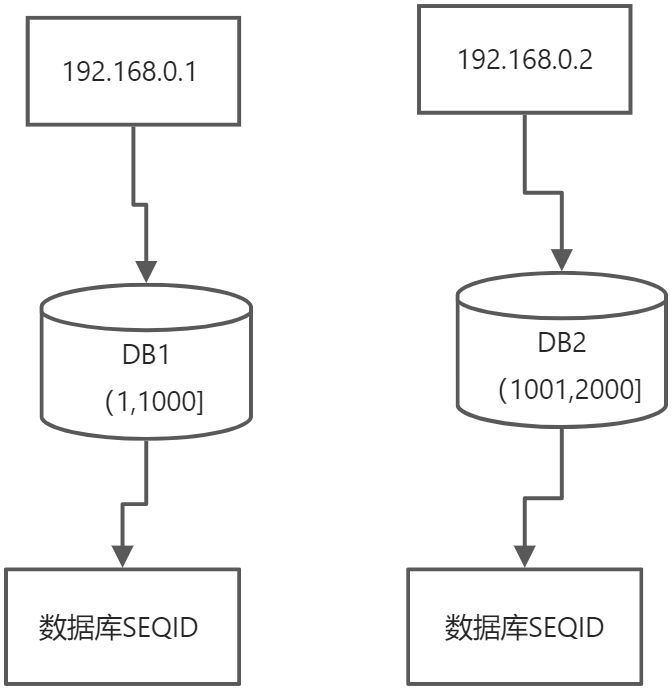
优点:
这种方案不再强依赖数据库,即便数据库挂掉,也依然可以继续用一段时间。
可以保证唯一性。
缺点:
当DB重启,这会失去一段ID,导致ID空洞。
它的作用是一个客户端一次性获取一个号段,但很明显是, 没法保证分布式ID 的全局递增, 也就是没法保证全局有序,而且, 如果客户端越多,那么就越是乱序。

若有收获,就点个赞吧
0 人点赞
