可以通过数组上的一组数学函数对整个数组或某个轴向的数据进行统计计算。sum、mean以及标准差std等聚合计算(aggregation,通常叫做约简(reduction))既可以当做数组的实例方法调用,也可以当做顶级NumPy函数使用
In [14]: arr = np.random.randn(5, 4)In [15]: arrOut[15]:array([[-0.18450665, 1.09160022, -0.45164509, -1.29567266],[-0.36163517, 0.37244986, 0.98034514, 0.82316027],[ 1.13255244, -0.75213107, 0.85103452, -0.15437491],[ 0.18715067, 1.75264532, 0.38247457, 1.18892021],[-0.34493636, 1.16156775, 1.92229378, -0.15901044]])In [16]: arr.mean()Out[16]: 0.40711411999618424In [17]: np.mean(arr)Out[17]: 0.40711411999618424In [18]: arr.sum()Out[18]: 8.142282399923685
mean和sum这类的函数可以接受一个axis选项参数,用于沿着该轴计算的统计值,最终结果是一个少一维的数组
In [19]: arr.mean(axis=0)Out[19]: array([0.08572498, 0.72522642, 0.73690058, 0.08060449])In [20]: arr.mean(axis=1)Out[20]: array([-0.21005604, 0.45358002, 0.26927025, 0.87779769, 0.64497868])
这里, arr.mean(1) 是“计算行的平均值”,arr.mean(0) 是“计算每列的和”
其他如cumsum和cumprod之类的方法则不聚合, 而是产生一个由中间结果组成的数组
In [21]: arr = np.array([0,1,2,3,4,5,6,7])In [22]: arr.cumsum()Out[22]: array([ 0, 1, 3, 6, 10, 15, 21, 28], dtype=int32)
在多维数组中,累加函数(如cumsum)返回的是同样大小的数组,但是会根据每个低维的切片沿着标记轴计算部分聚类
In [23]: arr = np.array([[0,1,2],[3,4,5], [6,7,8]])In [24]: arrOut[24]:array([[0, 1, 2],[3, 4, 5],[6, 7, 8]])In [25]: arr.cumsum(axis=0)Out[25]:array([[ 0, 1, 2],[ 3, 5, 7],[ 9, 12, 15]], dtype=int32)In [26]: arr.cumsum(axis=1)Out[26]:array([[ 0, 1, 3],[ 3, 7, 12],[ 6, 13, 21]], dtype=int32)In [27]: arr.cumprod(axis=1)Out[27]:array([[ 0, 0, 0],[ 3, 12, 60],[ 6, 42, 336]], dtype=int32)
下表列出了全部的基本数组统计方法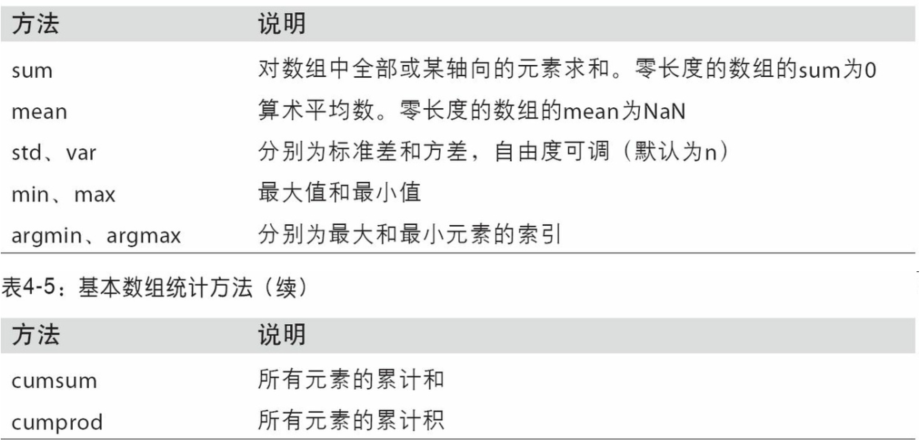

若有收获,就点个赞吧
0 人点赞
