第一个实例——产生Scrapy爬虫
- 应用Scrapy爬虫框架主要是编写配置型代码
HTML页面地址:http://python123.io/ws/demo.html
创建工程目录
- 在命令行中进行操作
```powershell
python -m scrapy startproject python123demo
New Scrapy project ‘python123demo’, using template directory ‘E:\Environment\anaconda\lib\site-packages\scrapy\templates\project’, created in: D:\Learning\CS\Py Learning\爬虫\week4-scrapy\python123demo
You can start your first spider with: cd python123demo scrapy genspider example example.com
cd python123demo ls
Mode LastWriteTime Length Name
d——- 2020/5/14 9:06 python123demo -a—— 2020/5/14 9:06 269 scrapy.cfg
<a name="thAMS"></a>### 工程目录内容<br /><a name="vbYge"></a>## 在工程中产生一个爬虫```powershell>>> python -m scrapy genspider demo python123.io
该命令的作用:
- 生成一个名称为demo的spider
- 在spiders目录下增加代码文件demo.py
该命令仅用于生成demo.py,该文件也可以手工生成
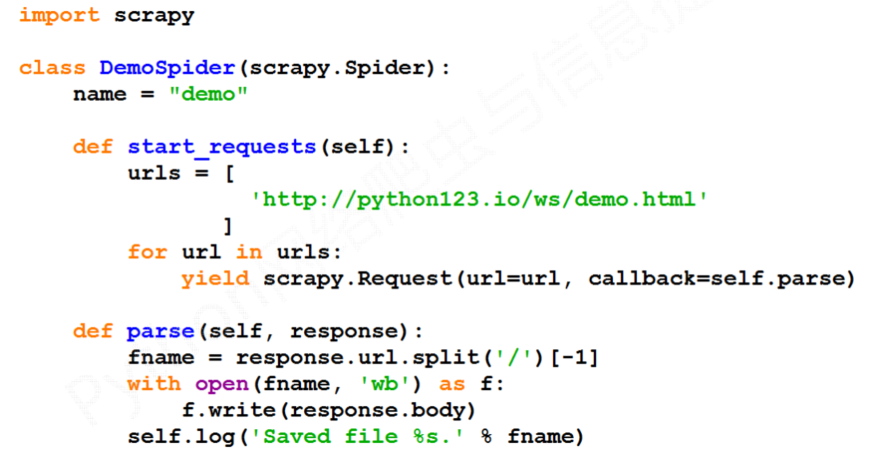
【demo.py文件内容】
# -*- coding: utf-8 -*-import scrapyclass DemoSpider(scrapy.Spider):name = 'demo'allowed_domains = ['python123.io']start_urls = ['http://python123.io/']def parse(self, response):pass
class DemoSpider(scrapy.Spider): name = ‘demo’
# allowed_domains = ['python123.io']start_urls = ['http://python123.io/ws/demo.html']def parse(self, response):file_path = response.url.split('/')[-1]with open(file_path, 'wb') as f:f.write(response.body)self.log('Saved file &s.' % name)pass
- 执行```powershell>>> python -m scrapy crawl demo
在spider目录下产生了爬取到的HTML页面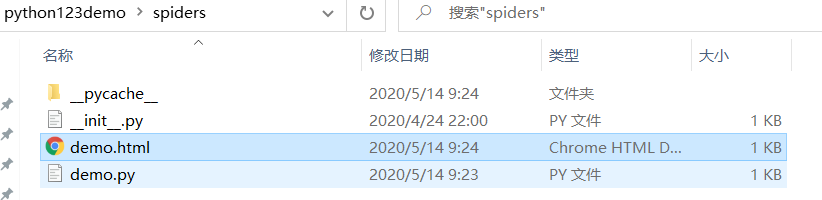
- demo.py代码的完整版本
- 两个等价版本的区别
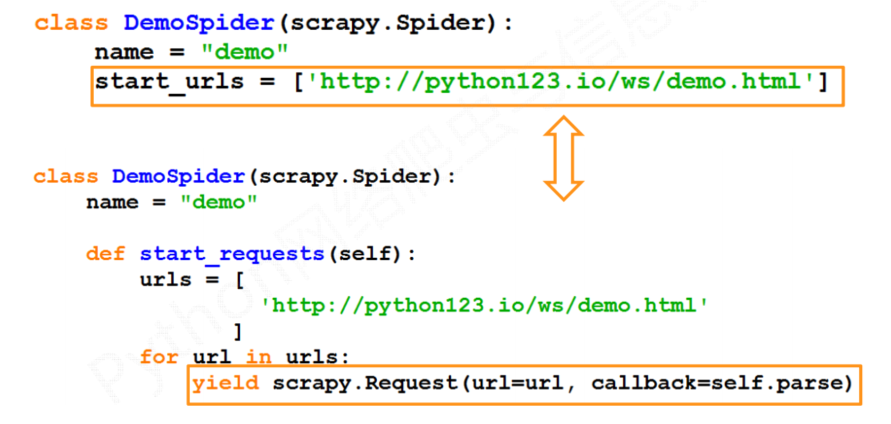
yield关键字

yield关键字经常与for循环搭配使用
实现上面代码的功能也可以用下面形式>>> def gen(n):for i in range(n):yield i ** 2>>> for i in gen(5):print(i, " " , end='')0 1 4 9 16
>>> def gen(n):lst = [i**2 for i in range(n)]return lst>>> for i in gen(n):print(i, ' ', end='')0 1 4 9 16

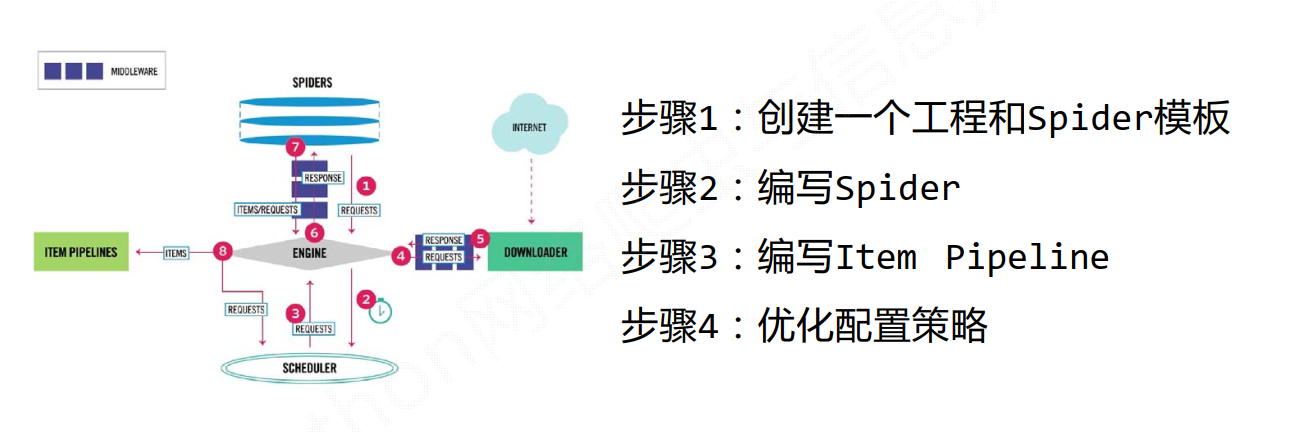
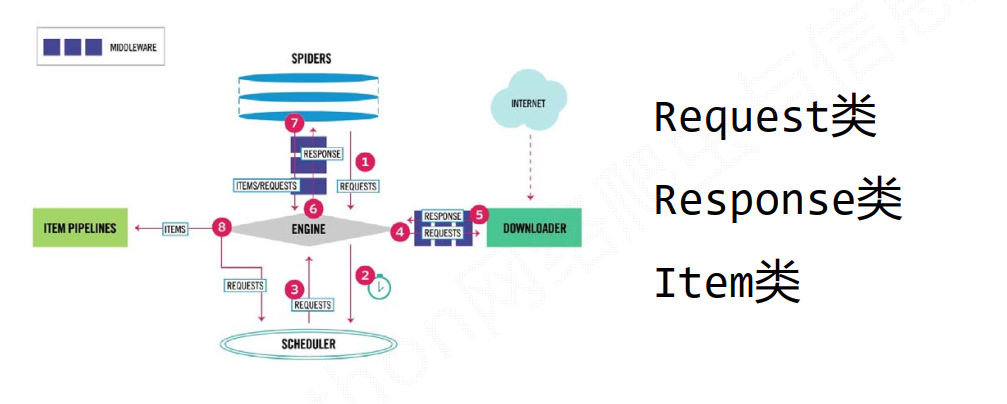
Scrapy爬虫的基本使用
使用步骤
数据类型
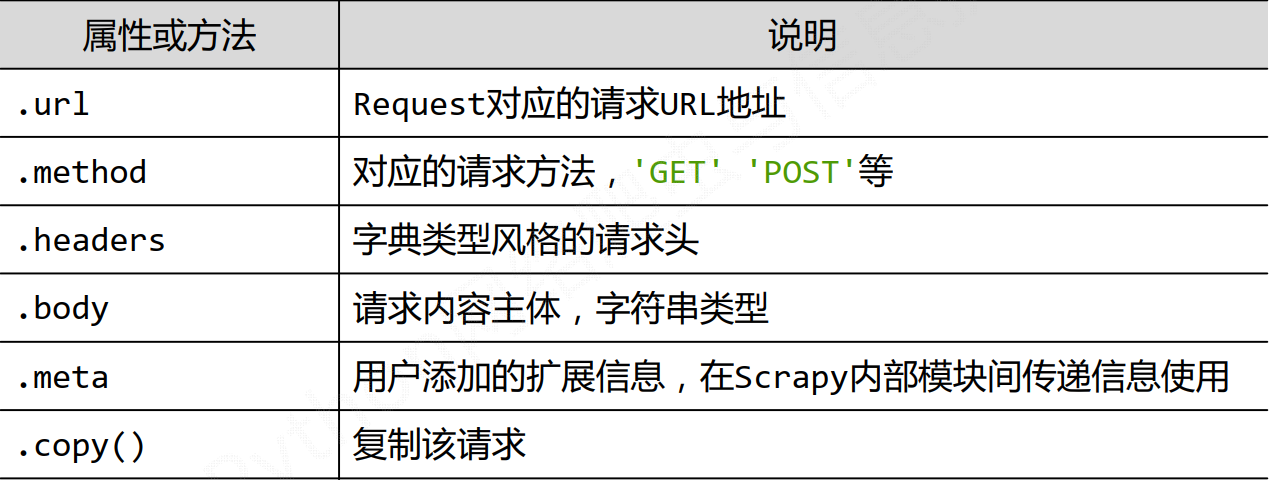
Request类

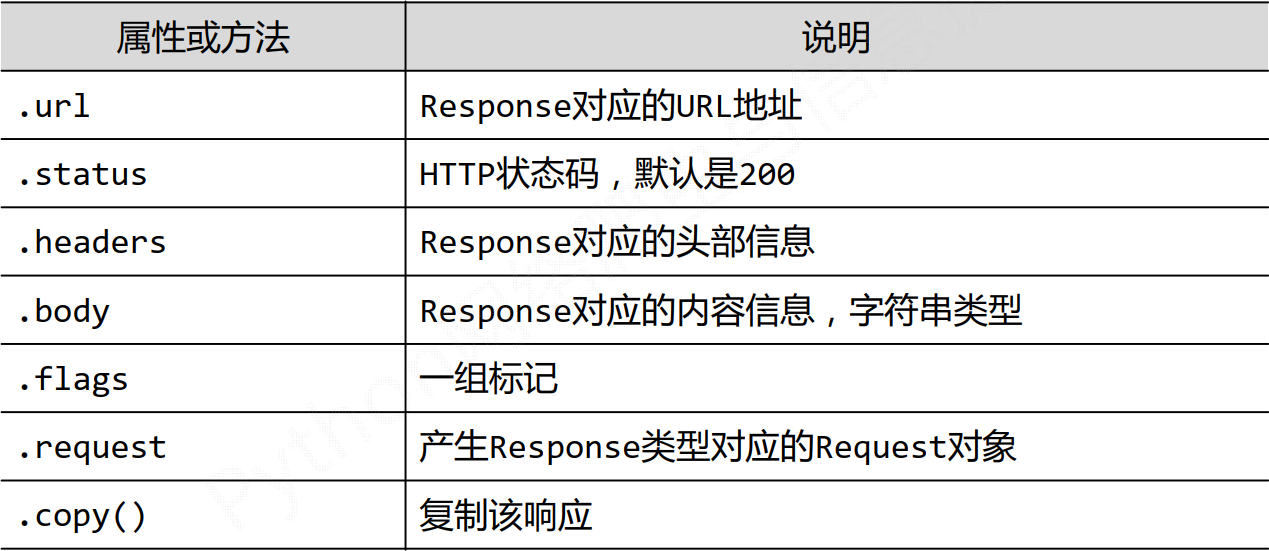
Resonpse

Item类

Scrapy提取信息的方法

CSS Selector


若有收获,就点个赞吧
0 人点赞
