import re
正则表达式在Python中表示
raw string(原生字符串)
- 原生字符串是不包含转义字符的字符串,
re库采用的是这种字符串。表示方式是r``'text'
例如 r``'[1-9]\d{5}'
re库也可以采用string类型的字符串,但是数学麻烦
上面的就需要写成这个样r``'[1-9]``\``\d{5}'
- 所以,当正则表达式中包含转义字符时,使用原生字符串比较稳妥
Re库主要功能函数

re.rearch()


>>> import re>>> match = re.search(r"[1-9]\d{5}", "Bit 100081")>>> if match:print(match.group(0))100081
re.match()
 ```python
```pythonimport re match = re.match(r”[1-9]\d{5}”, “BIT 100081”) match.group(0)
AttributeError Traceback (most recent call last)
AttributeError: ‘NoneType’ object has no attribute ‘group’
- 报错是以为 `match()` 是从字符串起始位置开始匹配,所以匹配失败。- 所以在程序中要判断变量**match**是否不为空```python>>> match = re.match(r'[1-9]\d{5}', 100081 BIT')>>> if match:match.group(0)'100081'
re.findall()

>>> import re>>> ls = re.findall(r"[1-9]\d{5}", "BIT100081 TSU100084")>>> ls['100081', '100084']
re.split()

>>> import re>>> re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084')['BIT', ' TUS', '']>>> re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084', maxsplit=1)['BIT', ' TUS100084']
re.finditer()

>>> import re>>> for m in re.finditer(r'[1-9]\d{5}', 'BIT100081 TSU100084'):if m:print(m.group(0))100081100084
re.sub()

>>> import re>>> re.sub(r'[1-9]\d{5}', ':zipcode', 'BIT100081 TSU100084')'BIT:zipcode TSU:zipcode'
Re库的面向对象形式


再在使用这个对象的6个成员函数的时候,就不需要填写
pattern参数了Re库的Match对象
>>> match = re.search(r'[1-9]\d{5}', 'BIT 100081')>>> if match:print(match.group(0))100081>>> type(match)<class '_sre.SRE_Match'>
Match对象的属性
Match对象的方法
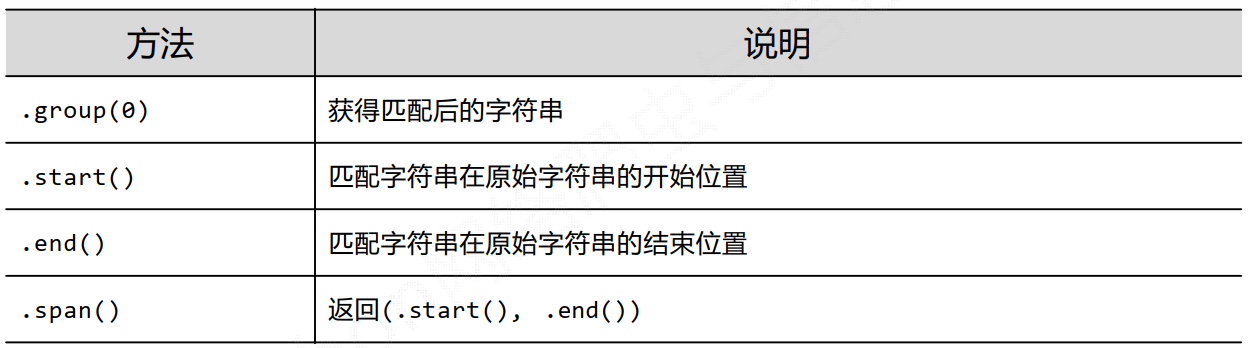
>>> import re>>> m = re.search(r'[1-9]\d{5}', ':zipcode', 'BIT100081 TSU100084')>>> m.string'BIT100081 TSU100084'>>> m.rere.compile('[1-9]\\d{5}')>>> m.pos0>>> m.endpos19>>> m.group(0)'100081'>>> m.start()3>>> m.end()9>>> m.span()(3, 9)
Re库的贪婪匹配和最小匹配


如何输出最短的子串呢?




若有收获,就点个赞吧
0 人点赞
