NumPy之于数值计算特别重要的原因之一, 是因为它可以高效处理大数组的数据。 这是因为:
- NumPy是在一个连续的内存块中存储数据, 独立于其他Python内置对象。 NumPy的C语言编写的算法库可以操作内存, 而不必进行类型检查或其它前期工作。 比起Python的内置序列,NumPy数组使用的内存少。
- NumPy可以在整个数组上执行复杂的计算, 而不需要Python的for循环。
可见,基于NumPy的算法要比纯Python块10到100倍(甚至更快),并且使用内存更少>>> import numpy as np>>> %time for _ in range(10): my_arr2 = my_arr * 2Wall time: 36.9 ms>>> %time for _ in range(10): my_list2 = [x * 2 for x in my_list]Wall time: 794 ms
NumPy的ndarray:一种多维数组对象
```python In [1]: import numpy as np
In [2]: data = np.random.randn(2, 3)
In [3]: data Out[3]: array([[-0.45730858, 0.53635669, -0.78764046], [-0.27321996, 1.40008167, 0.54588833]])
然后进行数学运算:```pythonIn [4]: data * 10Out[4]:array([[-4.57308583, 5.36356689, -7.87640465],[-2.73219957, 14.00081674, 5.45888334]])In [5]: data + dataOut[5]:array([[-0.91461717, 1.07271338, -1.57528093],[-0.54643991, 2.80016335, 1.09177667]])
ndarray是一个通用的同构数据多维容器, 也就是说, 其中的所有元素必须是相同类型的。 每个数组都有一个shape(一个表示各维度大小的元组) 和一个dtype(一个用于说明数组数据类型的对象)
In [6]: data.shapeOut[6]: (2, 3)In [7]: data.dtypeOut[7]: dtype('float64')
创建ndarray
创建数组最简单的办法就是使用array函数。 它接受一切序列型的对象(包括其他数组) , 然后产生一个新的含有传入数据的NumPy数组。
In [8]: data1 = [6, 7.5, 8, 0, 1]In [9]: arr1 = np.array(data1)In [10]: arr1Out[10]: array([6. , 7.5, 8. , 0. , 1. ])
嵌套序列(比如由一组等长列表组成的列表) 将会被转换为一个多维数组,可以用ndim和shape验证
In [11]: data2 = [[1,2,3,4], [5,6,7,8]]In [12]: arr2 = np.array(data2)In [13]: arr2Out[13]:array([[1, 2, 3, 4],[5, 6, 7, 8]])In [14]: arr2.ndimOut[14]: 2In [14]: arr2.shapeOut[14]: (2, 4)In [15]: arr2.dtypeOut[15]: dtype('int64')
除np.array之外,还有一些函数也可以新建数组。比如,zeros和ones分别可以创建指定长度或形状的全0或全1数组。empty可以创建一个没有任何具体值的数组。 要用这些方法创建多维数组, 只需传入一个表示形状的元组即可
In [1]: import numpy as npIn [2]: np.zeros(10)Out[2]: array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])In [3]: np.zeros((3,6))Out[3]:array([[0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0.]])In [4]: np.empty((2,3,2))Out[4]:array([[[0., 0.],[0., 0.],[0., 0.]],[[0., 0.],[0., 0.],[0., 0.]]])
注意: 认为np.empty会返回全0数组的想法是不安全的。 很多情况下(如前所示) , 它返回的都是一些未初始化的垃圾值
arange是Python内置函数range的数组版
In [3]: np.arange(15)Out[3]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
- 一些数组创建函数。由于NumPy关注的是数值计算, 因此, 如果没有特别指定, 数据类型基本都是float64(浮点数)
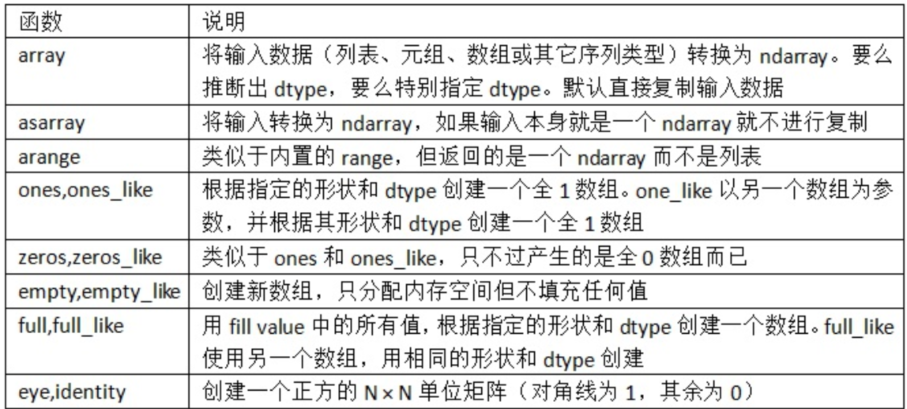
ndarray数据类型
dtype(数据类型)是一个特殊的对象, 它含有ndarray将一块内存解释为特定数据类型所需的信息
In [5]: arr1 = np.array([1,2,3], dtype=np.float64)In [6]: arr2 = np.array([1,2,3], dtype=np.int32)In [7]: arr1.dtypeOut[7]: dtype('float64')In [8]: arr2.dtypeOut[8]: dtype('int32')
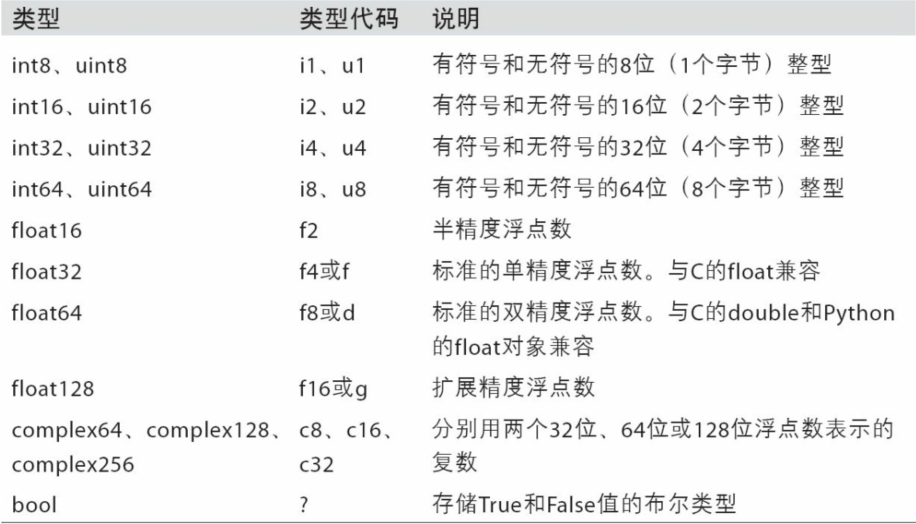

可以通过ndarray的astype方法明确地将一个数组从一个dtype转换成另一个dtype
In [9]: arr = np.array([1,2,3,4,5])In [10]: arr.dtypeOut[10]: dtype('int32')In [11]: float_arr = arr.astype(np.float64)
如果某字符串数组表示的全是数字, 也可以用astype将其转换为数值形式
In [12]: numeric_strings = np.array(['1.25', '-9.6', '42'], dtype=np.string_)In [13]: numeric_strings.astype(float)Out[13]: array([ 1.25, -9.6 , 42. ])
注意: 使用numpy.string_类型时, 一定要小心, 因为NumPy的字符串数据是大小固定的, 发生截取时, 不会发出警告。 pandas提供了更多非数值数据的便利的处理方法。
如果转换过程因为某种原因而失败了(比如某个不能被转换为float64的字符串) , 就会引发一个ValueError
在上面的代码中,即使将float作为目标转换类型,NumPy也能将其映射到对应的dtype上
还可以用简洁的类型代码来表示dtype
In [11]: empty_uint32 = np.empty(8, dtype='u4')In [12]: empty_uint32Out[12]:array([ 0, 1072693248, 0, 1073741824, 0,1074266112, 0, 1074790400], dtype=uint32)
astype总会创建一个新的数组(一个数据的备份),即使新的dtype与旧的dtype相同
NumPy数组的运算
In [14]: arr = np.array([[1,2,3], [4,5,6]])In [15]: arr * arrOut[15]:array([[ 1, 4, 9],[16, 25, 36]])In [16]: arr - arrOut[16]:array([[0, 0, 0],[0, 0, 0]])
数组与标量的算术运算会将标量值传播到各个元素
In [17]: 1 / arrOut[17]:array([[1. , 0.5 , 0.33333333],[0.25 , 0.2 , 0.16666667]])In [18]: arr ** 0.5Out[18]:array([[1. , 1.41421356, 1.73205081],[2. , 2.23606798, 2.44948974]])
大小相同的数组之间的比较会生成布尔值数组
In [19]: arr2 = np.array([[0., 4., 1.], [7., 2., 12.]])In [20]: arr2Out[20]:array([[ 0., 4., 1.],[ 7., 2., 12.]])In [21]: arr2 > arrOut[21]:array([[False, True, False],[ True, False, True]])
基本的索引和切片
In [1]: import numpy as npIn [2]: arr = np.arange(10)In [3]: arrOut[3]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])In [4]: arr[5:8] = 12In [5]: arrOut[5]: array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
如上所示, 当你将一个标量值赋值给一个切片时(如arr[5:8]=12) , 该值会自动传播(也就说后面将会讲到的“广播”) 到整个选区。 跟列表最重要的区别在于, 数组切片是原始数组的视图。 这意味着数据不会被复制, 视图上的任何修改都会直接反映到源数组上
In [6]: arr_slice = arr[5:8]In [7]: arr_slice[:] = 64In [8]: arrOut[8]: array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
之所以这么做,是因为NumPy的设计目的是处理大数据,所以就放弃了很多语言的复制来复制过去的做法
注意: 如果你想要得到的是ndarray切片的一份副本而非视图, 就需要明确地进行复制操作,
例如 arr[5:8].copy()
对于高维度数组, 能做的事情更多。 在一个二维数组中, 各索引位置上的元素不再是标量而是一维数组
In [9]: arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]])In [10]: arr2d[2]Out[10]: array([7, 8, 9])
下面两种访问单个元素的方式是等价的
In [11]: arr2d[0][2]Out[11]: 3In [12]: arr2d[0, 2]Out[12]: 3
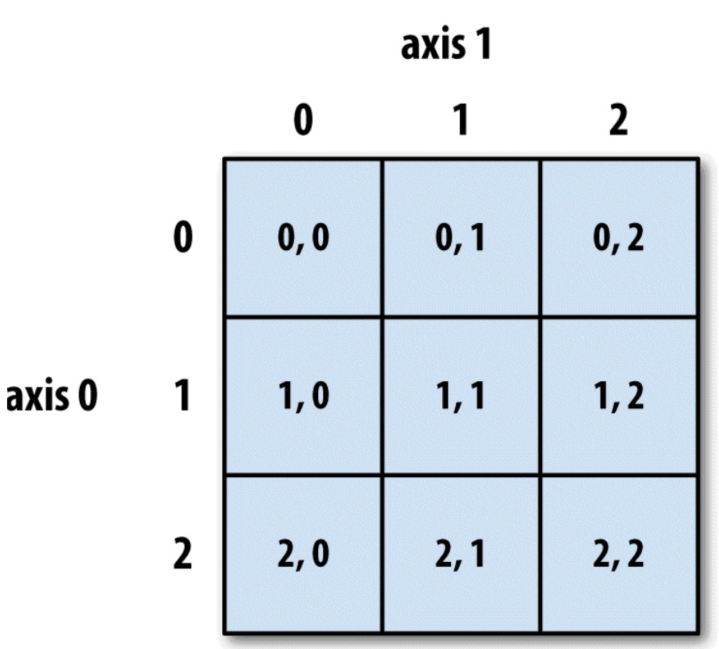
下图说明了二维数组的索引方式。 轴0作为行, 轴1作为列
在多维数组中, 如果省略了后面的索引, 则返回对象会是一个维度低一点的ndarray
In [13]: arr3d = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])In [14]: arr3dOut[14]:array([[[ 1, 2, 3],[ 4, 5, 6]],[[ 7, 8, 9],[10, 11, 12]]])
arr3d[0] 是一个 数组
数组
In [15]: arr3d[0]Out[15]:array([[1, 2, 3],[4, 5, 6]])
标量值和数组都可以被赋值给 arr3d[0]
In [16]: old_values = arr3d[0].copy()In [17]: arr3d[0] = 42In [18]: arr3dOut[18]:array([[[42, 42, 42],[42, 42, 42]],[[ 7, 8, 9],[10, 11, 12]]])In [19]: arr3d[0] = old_valuesIn [20]: arr3dOut[20]:array([[[ 1, 2, 3],[ 4, 5, 6]],[[ 7, 8, 9],[10, 11, 12]]])
相似的, arr3d[1,0] 可以访问索引以(1,0)开头的那些值(以一维数组的形式返回)
In [21]: arr3d[1,0]Out[21]: array([7, 8, 9])
切片索引
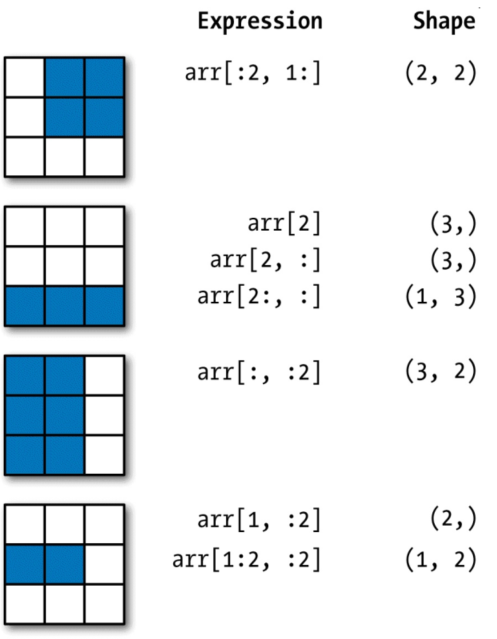
对于以为数组,跟Python的列表切片基本一样。对于之前的二维数组arr2d, 其切片方式稍显不同
In [22]: arr2dOut[22]:array([[1, 2, 3],[4, 5, 6],[7, 8, 9]])In [23]: arr2d[:2]Out[23]:array([[1, 2, 3],[4, 5, 6]])
可以看出, 它是沿着第0轴(即第一个轴) 切片的。 也就是说, 切片是沿着一个轴向选取元素的。
表达式 arr2d[:2] 可以被认为是“选取arr2d的前两行”。
可以一次传入多个切片, 就像传入多个索引那样
In [24]: arr2d[:2, 1:]Out[24]:array([[2, 3],[5, 6]])
像这样进行切片时, 只能得到相同维数的数组视图。 通过将整数索引和切片混合, 可以得到低维度
In [25]: arr2d[1, :2]Out[25]: array([4, 5])
布尔类型索引
In [26]: names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])In [27]: data = np.random.randn(7, 4)In [29]: namesOut[29]: array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'], dtype='<U4')In [30]: dataOut[30]:array([[ 0.70507199, -0.63721573, -1.86149772, -1.80573623],[ 0.09655486, 0.24640234, -0.70079906, -0.12647153],[-0.11690175, -1.19385087, 3.31880226, 0.55853635],[-0.63570942, 0.32473218, -0.2127324 , 1.01473567],[-0.92873195, 0.00682564, -0.08354234, 0.50574418],[-0.76971669, -0.5399367 , -1.05318819, -1.25870414],[ 0.3762395 , -0.55172785, -0.47706216, -1.22961565]])
假设每个名字都对应data数组中的一行, 而我们想要选出对应于名字”Bob”的所有行。 跟算术运算一样, 数组的比较运算(如==) 也是矢量化的。 因此, 对 names 和字符串”Bob”的比较运算将会产生一个布尔型数组
In [31]: names == 'Bob'Out[31]: array([ True, False, False, True, False, False, False])
这个布尔型数组可用于数组索引
In [33]: data[names == 'Bob']Out[33]:array([[ 0.70507199, -0.63721573, -1.86149772, -1.80573623],[-0.63570942, 0.32473218, -0.2127324 , 1.01473567]])
布尔型数组的长度必须跟被索引的轴长度一致。此外,还可以将布尔型数组跟切片、整数(或整数序列, 稍后将对此进行详细讲解)混合使用
In [34]: data[names=='Bob', 2:]Out[34]:array([[-1.86149772, -1.80573623],[-0.2127324 , 1.01473567]])
要选择除”Bob”以外的其他值,既可以使用不等于符号(!=),也可以通过~对条件进行否定
In [35]: names != 'Bob'Out[35]: array([False, True, True, False, True, True, True])In [36]: data[~(names == 'Bob')]Out[36]:array([[ 0.09655486, 0.24640234, -0.70079906, -0.12647153],[-0.11690175, -1.19385087, 3.31880226, 0.55853635],[-0.92873195, 0.00682564, -0.08354234, 0.50574418],[-0.76971669, -0.5399367 , -1.05318819, -1.25870414],[ 0.3762395 , -0.55172785, -0.47706216, -1.22961565]])
还可以这么用
In [37]: cond = names == 'Bob'In [38]: data[~cond]Out[38]:array([[ 0.09655486, 0.24640234, -0.70079906, -0.12647153],[-0.11690175, -1.19385087, 3.31880226, 0.55853635],[-0.92873195, 0.00682564, -0.08354234, 0.50574418],[-0.76971669, -0.5399367 , -1.05318819, -1.25870414],[ 0.3762395 , -0.55172785, -0.47706216, -1.22961565]])
选取这三个名字中的两个需要组合应用多个布尔条件,使用&(和)、|(或)之类的布尔算术运算符即可通过布尔型索引选取数组中的数据, 将总是创建数据的副本, 即使返回一模一样的数组也是如此
In [39]: mask = (names == 'Bob') | (names == 'Will')In [42]: maskOut[42]: array([ True, False, True, True, True, False, False])In [43]: data[mask]Out[43]:array([[ 0.70507199, -0.63721573, -1.86149772, -1.80573623],[-0.11690175, -1.19385087, 3.31880226, 0.55853635],[-0.63570942, 0.32473218, -0.2127324 , 1.01473567],[-0.92873195, 0.00682564, -0.08354234, 0.50574418]])
通过布尔型索引选取数组中的数据, 将总是创建数据的副本, 即使返回一模一样的数组也是如此
注意: Python关键字and和or在布尔型数组中无效。 要使用&与|
通过布尔型数组设置值是一种经常用到的手段。 为了将data中的所有负值都设置为0, 我们只需
In [44]: data[data < 0] = 0In [45]: dataOut[45]:array([[0.70507199, 0. , 0. , 0. ],[0.09655486, 0.24640234, 0. , 0. ],[0. , 0. , 3.31880226, 0.55853635],[0. , 0.32473218, 0. , 1.01473567],[0. , 0.00682564, 0. , 0.50574418],[0. , 0. , 0. , 0. ],[0.3762395 , 0. , 0. , 0. ]])
通过一维布尔数组设置整行或列的值也很简单
In [46]: data[names != 'Joe'] = 7In [47]: dataOut[47]:array([[7. , 7. , 7. , 7. ],[0.09655486, 0.24640234, 0. , 0. ],[7. , 7. , 7. , 7. ],[7. , 7. , 7. , 7. ],[7. , 7. , 7. , 7. ],[0. , 0. , 0. , 0. ],[0.3762395 , 0. , 0. , 0. ]])
花式索引
花式索引(Fancy indexing) 是一个NumPy术语,它指的是利用整数数组进行索引
In [48]: arr = np.empty((8,4))In [49]: for i in range(8):...: arr[i] = i...:In [50]: arrOut[50]:array([[0., 0., 0., 0.],[1., 1., 1., 1.],[2., 2., 2., 2.],[3., 3., 3., 3.],[4., 4., 4., 4.],[5., 5., 5., 5.],[6., 6., 6., 6.],[7., 7., 7., 7.]])
为了以特定顺序选取行子集, 只需传入一个用于指定顺序的整数列表或ndarray即可
array([[4., 4., 4., 4.],[3., 3., 3., 3.],[0., 0., 0., 0.],[6., 6., 6., 6.]])
使用负数索引将会从末尾开始选取行
In [52]: arr[[-3, -5, -7]]Out[52]:array([[5., 5., 5., 5.],[3., 3., 3., 3.],[1., 1., 1., 1.]])
一次传入多个索引数组会有一点特别。 它返回的是一个一维数组, 其中的元素对应各个索引元组
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11],[12, 13, 14, 15],[16, 17, 18, 19],[20, 21, 22, 23],[24, 25, 26, 27],[28, 29, 30, 31]])In [55]: arr[[1,5,7,2], [0,3,1,2]]Out[55]: array([ 4, 23, 29, 10])
最终选出的是元素(1,0)、(5,3)、(7,1)和(2,2)。无论数组是多少维的,花式索引总是一维的

若有收获,就点个赞吧
0 人点赞
