功能描述

分析URL
在淘宝页面的搜索栏中,键入关键字,获取相关的URL并进行分析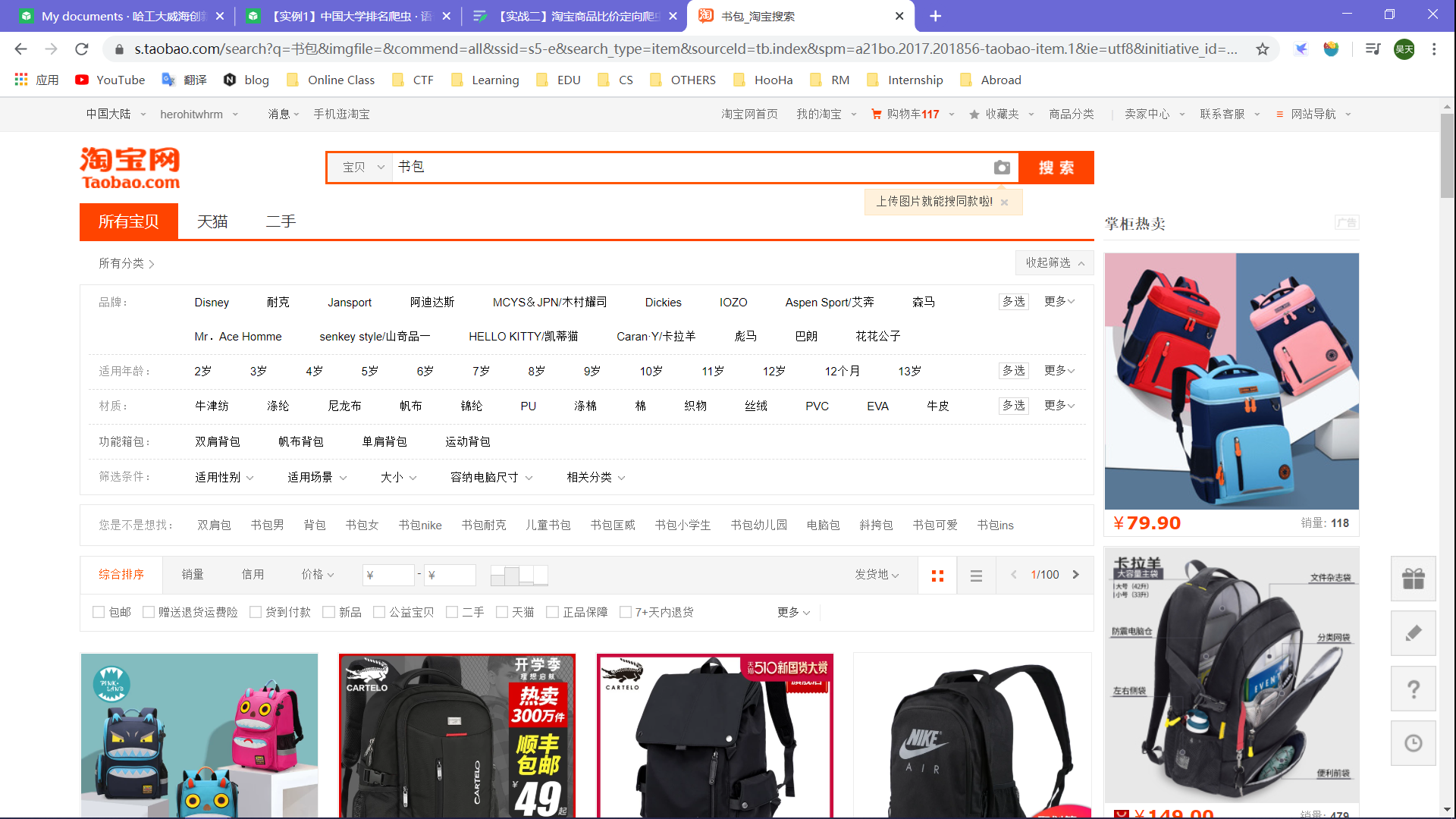
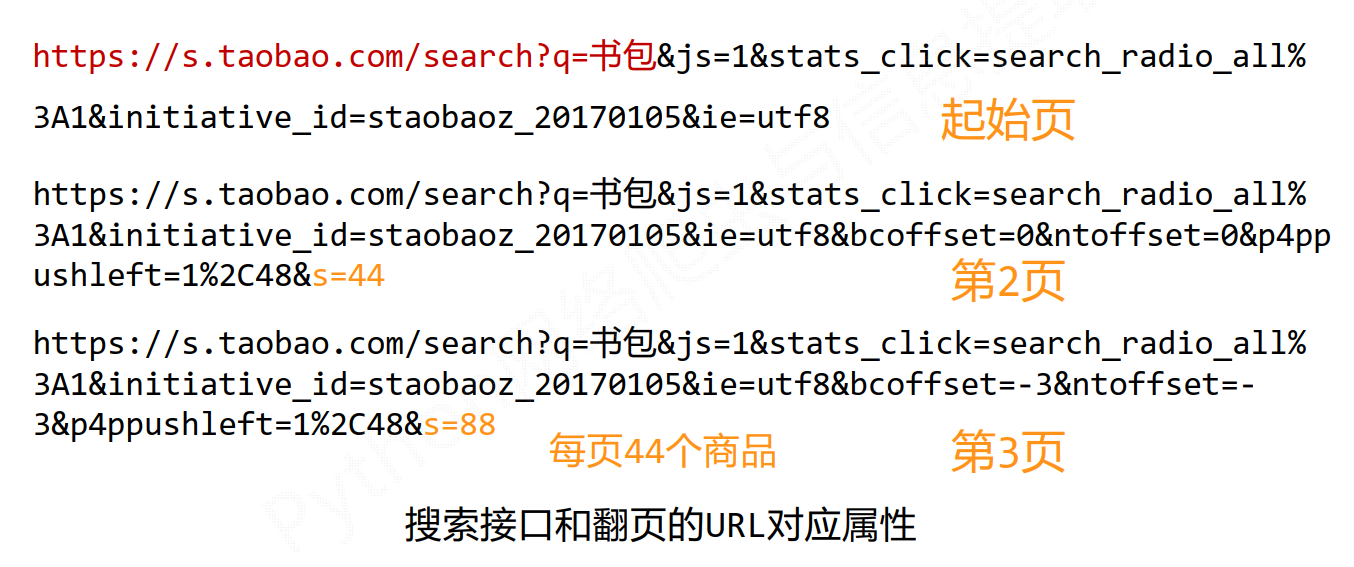
查看robots.txt

虽然对所有的user-agent限制根目录下的信息,即网站的所有信息都不能爬取,但我们模仿的是人类的访问,不是多次骚扰性质的访问,所以还是可以继续的
程序设计
import requestsimport redef getHTMLText(url):try:r = requests.get(url, timeout=30)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:return ""def parsePage(ilt, html):try:plt = re.findall(r'\"view_price\"\:\"[\d\.] *\"', html)tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)for i in range(len(plt)):price = eval(plt[i].split(':')[1])title = eval(tlt[i].split(':')[1])ilt.append([price, title])except:print("")def printGoodsList(ilt):tplt = "{:4}\t{:8}\t{:16}"print(tplt.format("序号", "价格", "商品名称"))count = 0for g in ilt:count += 1print(tplt.format(count, g[0], g[1]))print("")def main():goods = '书包'depth = 2 # 爬取的深度,即页数start_url = 'https://s.taobao.com//search?q=' + goodsinfo_list = []for i in range(depth):try:url = start_url + '&s=' + str(44*i)html = getHTMLText(url)parsePage(info_list, html)except:continueprintGoodsList(info_list)if __name__ == '_main__':main()
parsePage()函数的一般设计方法
在页面中查看源代码,对于商品所要的特征值进行提取,在源代码中的页面进行搜索,在这个例子中我们选择的是价格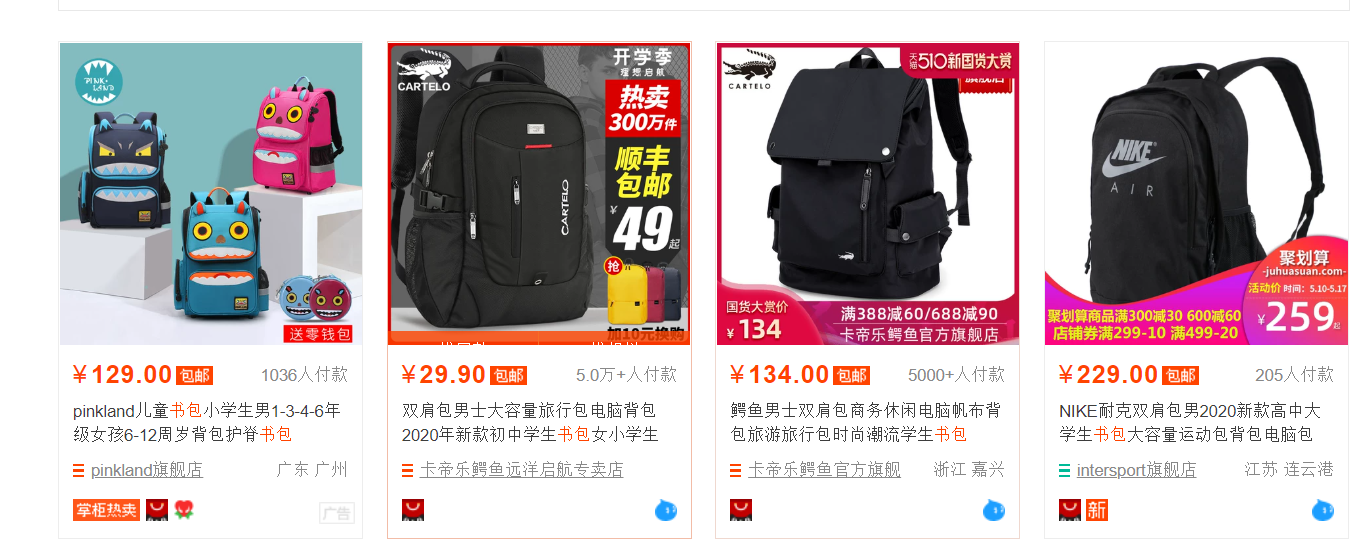
所以我们可以在网页源码中搜索‘129.00’,得到如下结果
我们发现,价格对应的标签名字叫做“view_price”
用同样的方法对商品名进行搜索,得到商品名对应的标签名叫“raw_title”
为什么不使用bs4库
我们看到我们需要的信息是以json格式进行组织的,而不是像前面是在HTML标签中进行结构化组织的。而对于这种字符串的匹配,我们使用正则表达式进行匹配,也是很合适的
BUT
现在淘宝需要登陆才能查看页面信息,所以,程序还是有待提升

若有收获,就点个赞吧
0 人点赞
