http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
功能描述

定向爬虫的可行性
- 在页面查看源代码,发现使用HTML标签,故可以使用爬虫

- 查看根目录下robots.txt,发现是一个空目录,说明没有对爬虫进行限制
http://www.zuihaodaxue.cn/robots.txt
程序结构


程序编写
import requestsfrom bs4 import BeautifulSoupimport bs4def getHTMLText(url):try:r = requests.get(url, timeout=30)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:return ""def fillUnivList(ulist, html):soup = BeautifulSoup(html, "html.parser")for tr in soup.find('tbody').children: # 每一个大学数据都封装在一个<tr>标签中if isinstance(tr, bs4.element.Tag): # children中有可能出现string类型对象tds = tr('td')ulist.append([tds[0].string, tds[1].string, tds[3].string])def printUnivList(ulist, num):print("{:^10}\t{:^6}\t{:^10}".format("排名", "学校名称", "总分"))for i in range(num):u = ulist[i]print("{:^10}\t{:^6}\t{:^10}".format(u[0], u[1], u[2]))def main():uinfo = []url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html"html = getHTMLText(url)fillUnivList(uinfo, html)printUnivList(uinfo, 20) # 20 univsif __name__ == "__main__":main()
程序优化
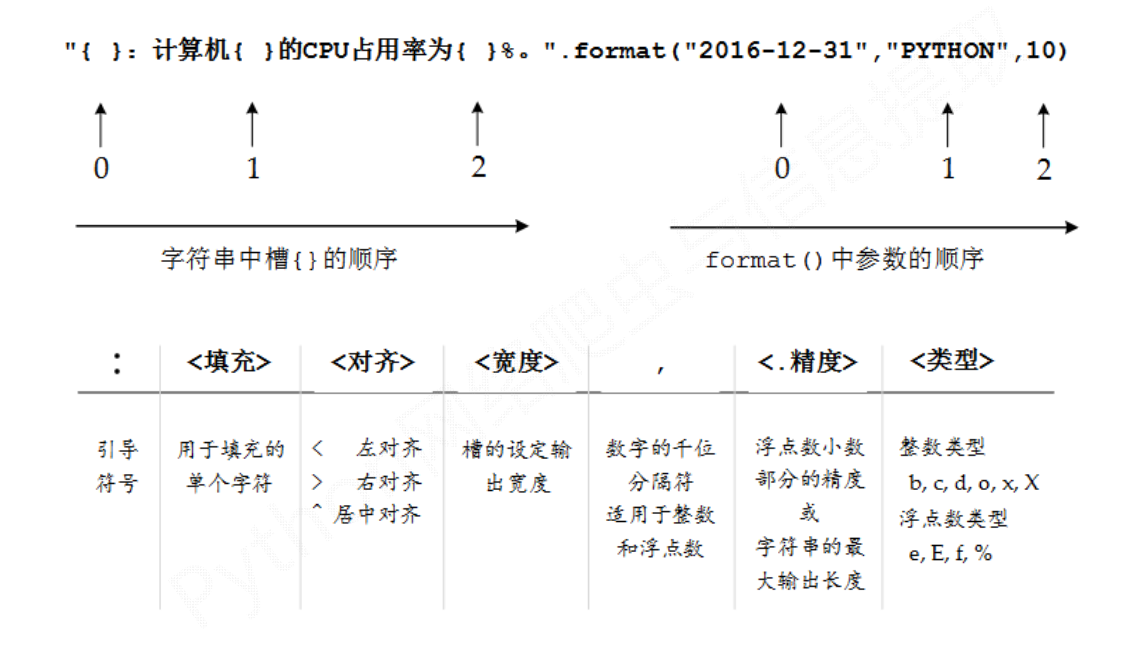
- 中文对齐问题


若有收获,就点个赞吧
0 人点赞
