程序设计步骤

建立工程和Spider模板
\> scrapy startproject stock_spider\> cd BaiduStocks\> scrapy genspider stocks baidu.com
编写Spider

class StocksSpider(scrapy.Spider): name = ‘stocks’ allowed_domains = [‘baidu.com’] start_urls = [‘http://baidu.com/‘]
def parse(self, response):pass
- 修改后```python# -*- coding: utf-8 -*-import scrapydef parse(self, response):for href in response.css('a::attr(href)).extract():try:stock = re.findall(r"[s][hz]\d{6}", href)[0]url = 'https://gupiao/baidu.com/stock/' + stock + '.html'yield scrapy.Request(url, callback=parse_stock)except:continuedef parse_stock(self, response):info_dict = {}stock_info = response.css('.stock-bets')name = stock_info.css('.bets-name').extract()[0]key_list = stock_info.css('dd').extract()value_list = stock_info.css('dd').extract()for i in range(len(key_list):key = re.findall(r'>.*</dt>', key_list[i])[0][1:-5]try:value = re.findall(r'\d+\.?.*</dd>', value_list[i])[0][0:-5]except:value = '--'info_dict[key] = valueinfo_dict.update({'股票名称': re.findall('\s.*\(', name)[0].split()[0] +re.findall('\>.*\<', name)[0][1:-1]})yield info_dict
编写Pipelines

文件在stock_spider目录下
Define your item pipelines here
#
Don’t forget to add your pipeline to the ITEM_PIPELINES setting
See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class StockSpiderPipeline: def process_item(self, item, spider): return item
- 修改后- 这里我们新建一个类,并在配置文件中添加配置,使它识别我们新编写的类```python# -*- coding: utf-8 -*-# Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlclass StockSpiderPipeline:def process_item(self, item, spider):return itemclass StockInfoPipeline():def open_spider(self, spider):self.f = open('StockInfo.txt', 'w')def close_spider(self, spider):self.f.close()def process_item(self, item, spider):try:line = str(dict(item)) + '\n'self.f.write(line)except:passreturn item
- 修改配置文件
配置settings.py文件
# Configure item pipelines# See https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES = {'stock_spider.pipelines.StockInfoPipeline': 300,}
执行
/> python -m scrapy crawl stocks
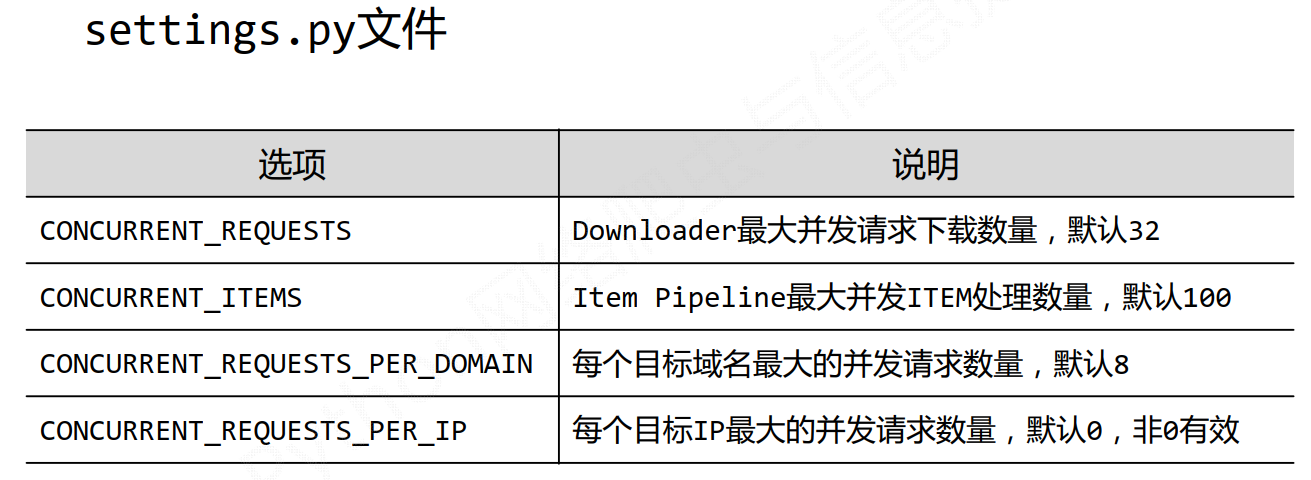
优化——改善性能

若有收获,就点个赞吧
0 人点赞
