目前,不少人物种的基因组已经被测定,常常我们可以直接获得物种的基因组序列以及基因结构注释信息。基于这两个文件,我们完全可以提取:
- 转录本序列
- CDS序列
- 启动子序列
- …
功能界面如下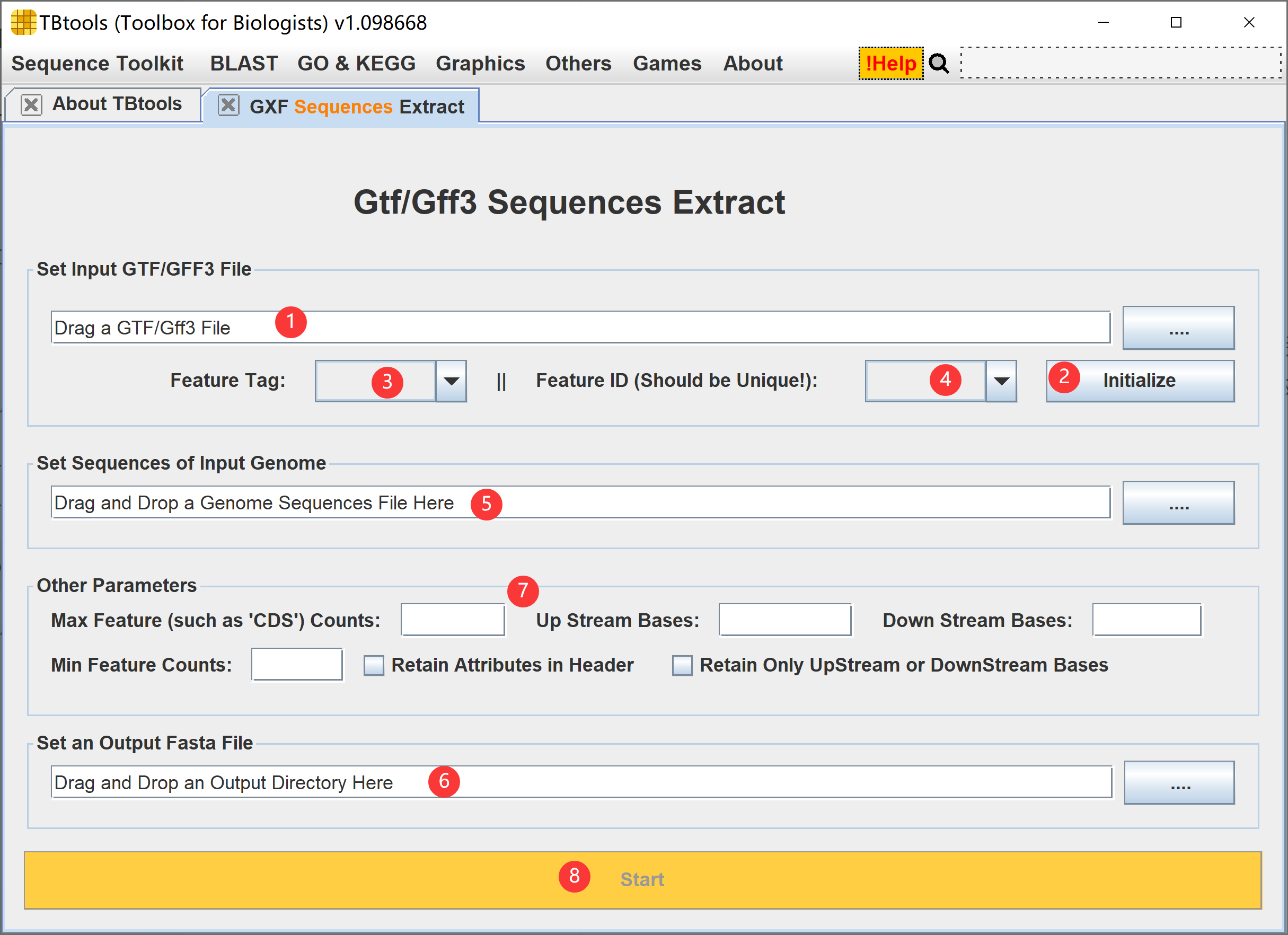
- 设置物种的基因结构注释信息,GFF3或GTF格式
- 点击“Initialize”摁钮,即可看到 3. 和 4. 出现可选项
- 选择目标注释特征,如 CDS/Exon/UTR 等
- 选择注释特征分组标签,如 Parent/transcript/protein 等;注意到,在GFF3或GTF文件中,注释特征是按照不间断跨度,单行记录,即一个转录本有多个Exon,每个Exon各在一行,类似的 CDS 或其他也是,所以需要使用分组标签,串联一个转录本的所有Exon,从而得到完整序列
- 设置物种的基因组序列信息
- 设置输出文件路径
- 可选参数,用于定制提取的具体内容或过滤参数:
- Max Feature Counts:即分组中最多包含区间数目,如提取的是 exon,选择分组标签为 Parent,设置这一参数为 1 ,则仅提取单外显子的转录本
- Min Feature Counts:即分组中最少包含区间数目,取的是 exon,选择分组标签为 Parent,设置这一参数为 2 ,则仅提取的转录本至少包含一个内含子
- Upstream Bases:提取目标注释特征上游给定碱基数目,如提取的目标注释特征是 CDS,设置值为 2000,则提取翻译起始密码子上游2000bp(即常见分析中的启动子序列)
- Donwstrean Bases:提取目标注释特征下游给定碱基数目
- Retain Attributes in Header:将提取的序列相关信息附加在输出的 Fasta ID 信息中
- Retain Only Upstream or Downstream Bases:只保留目标注释特征的上游或下游部分(而不保留目标序列特征);如启动子区域序列提取时,并不需要保留 CDS 区域的序列,而只需要其翻译起始密码子上游的序列部分
- 点击开始即可(如果这个摁钮为灰色,那么说明用户还没有点击 Initialize)
早前,相关功能亦有实例教程,可见
TBtools | 地球最友好的 GFF3/GTF 序列提取工具

若有收获,就点个赞吧
0 人点赞
