有时候,一些 Fatsa 序列 ID 较为复杂,如“>Unigene1 MYB Protein”,或从 NCBI,Uniprot,Swissprot 等公共数据库下载序列,往往会有复杂 ID。这一功能主要用于简化 Fasta 序列 ID。举个例子:“>Unigene1 MYB Protein”简化为“>Unigene1”。当然这应该能也专门针对一些数据库下载的特殊的 ID 格式。
整体界面如下,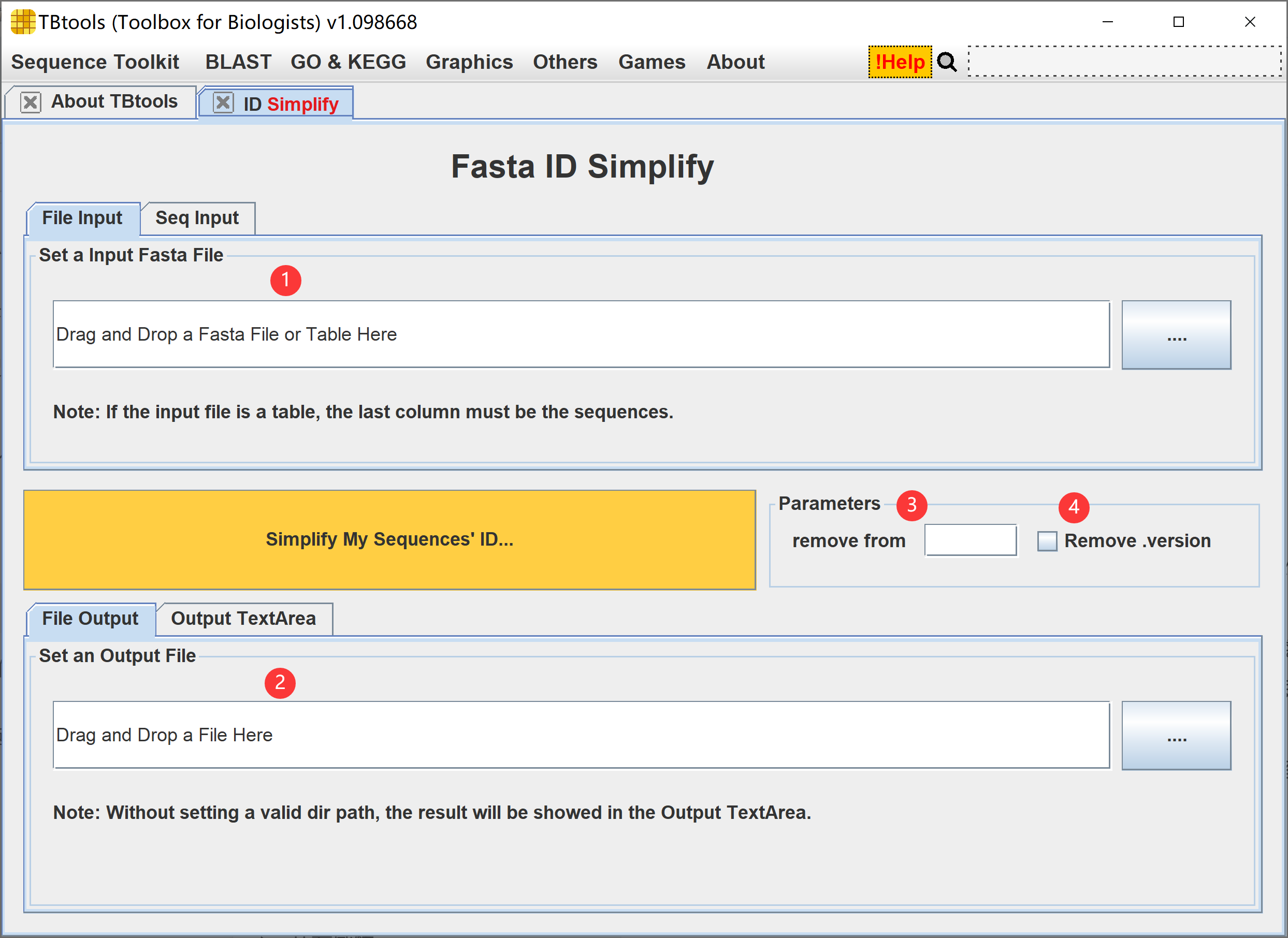
使用详细解释(注意,该功能是批量的):
- 设置输入序列文件或直接黏贴少量序列文本
- 设置输出序列文件或直接输出到文本区域框
- Remove from:从给定匹配模式处开始清理 ID,如“>Unigene_1.version3.3 confident”,使用模式“.version”即可将清理为“>Unigene_1”
- Remove .version:用于简单快速去除版本号等信息,如“>ABC183710.1”和“>CABT19912.3”,会直接去除“.1”和“.3”
点击“Simplify My Sequence’s ID…”

若有收获,就点个赞吧
0 人点赞
