写在前面
早前已经推过《新手eggNOG-Mapper详细教程》,但仍然有很多人遇到使用问题。换句话,可能那个教程不能彻底解决大伙遇到的问题。于是我决定写一个完美的教程,彻底解决大伙的基因功能注释问题。
eggNOG-mapper 大名鼎鼎,是一款非常全面,高效,准确,且一直在更新的软件,对应的,该团队提供了网页接口,任何人可以提交蛋白序列文件,在极短的时间内(一般几分钟)完成基因功能注释,包括:
1.具体功能描述信息
2.Gene Onotoloy注释信息
3.KEGG 注释信息
4.PFAM 注释信息
5.以及其他…
今天的这份教程,会让任何人看过之后,就完全可以掌握注释方法,而且可以得到用于基因功能富集分析的输入文件,如GO富集分析、KEGG富集分析等。这或许是不少 TBtools 用户的烦恼。
回到主题,教程分为两个部分:
- 如何使用 eggNOG-mapper 进行基因功能注释
- 如果使用 TBtools 软件一键整理基因功能注释结果
eggNOG-mapper 注释
首先,基因功能注释质量好坏取决于数据库质量高低,是否全面。于是,本地化进行基因功能注释,需要收集尽可能多的数据库(这个其实很不实际),也需要有较好的计算资源。通过使用网页服务工具,可以克服这个问题。我们可以一直使用最新最全的数据库,同时不需要消耗本地计算资源。
在 eggNOG-mapper 上进行基因功能注释,非常简单。
第一步,打开 eggNOG-mapper 主页
http://eggnog-mapper.embl.de/
看到下图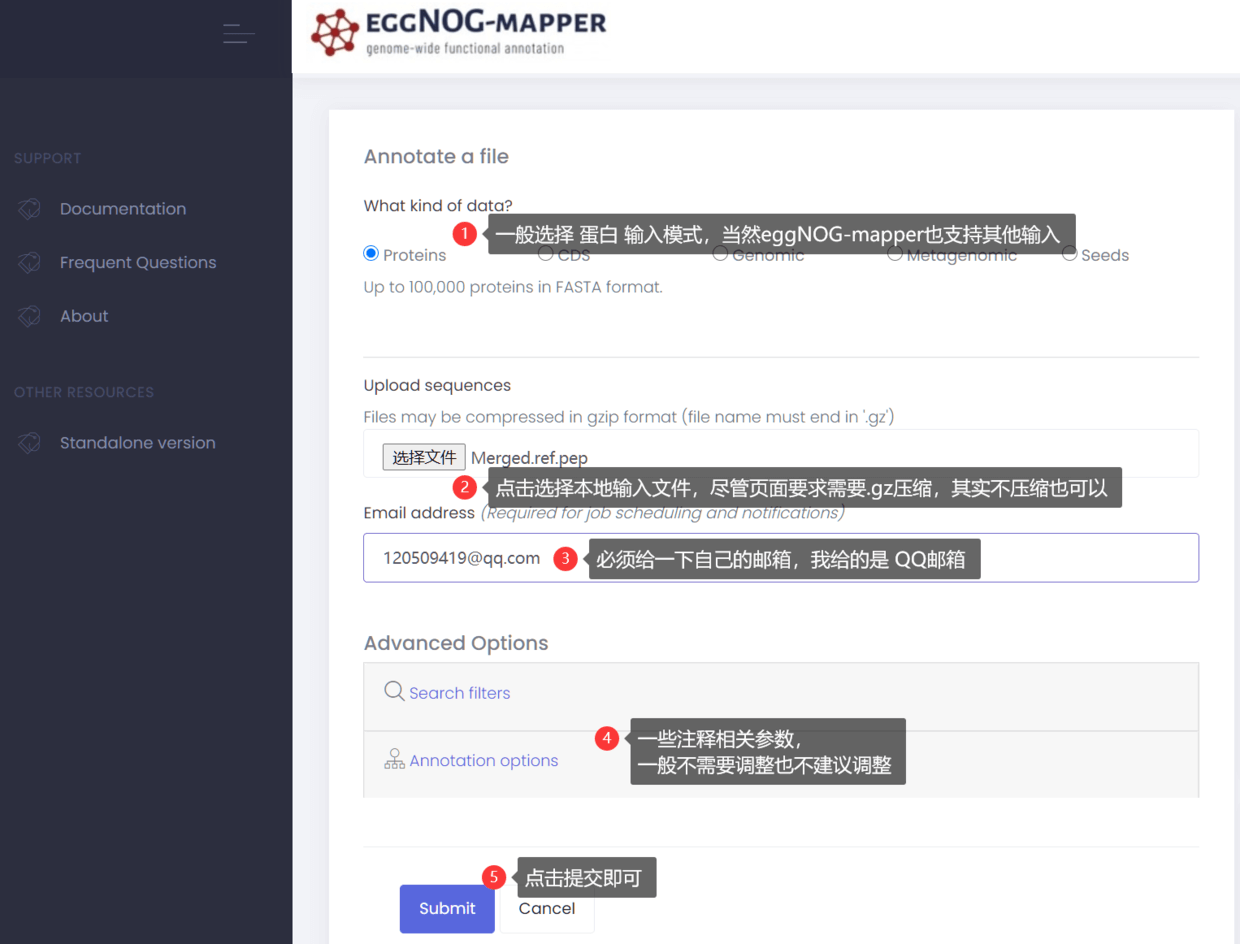
参考上图,其实需要做的事情非常简单:
- 选择输入模式,一般是输入蛋白序列
2.选择本地输入文件,即蛋白序列集合(这个完全可以基于基因组序列.fa和基因结构注释文件.gff3/.gtf用TBtools提取)
3.给定一个邮箱地址(注意,这个非常重要,需要进入邮箱才能启动任务)
4.点击 Start
等待文件上传,一般大概不到一分钟,弹出页面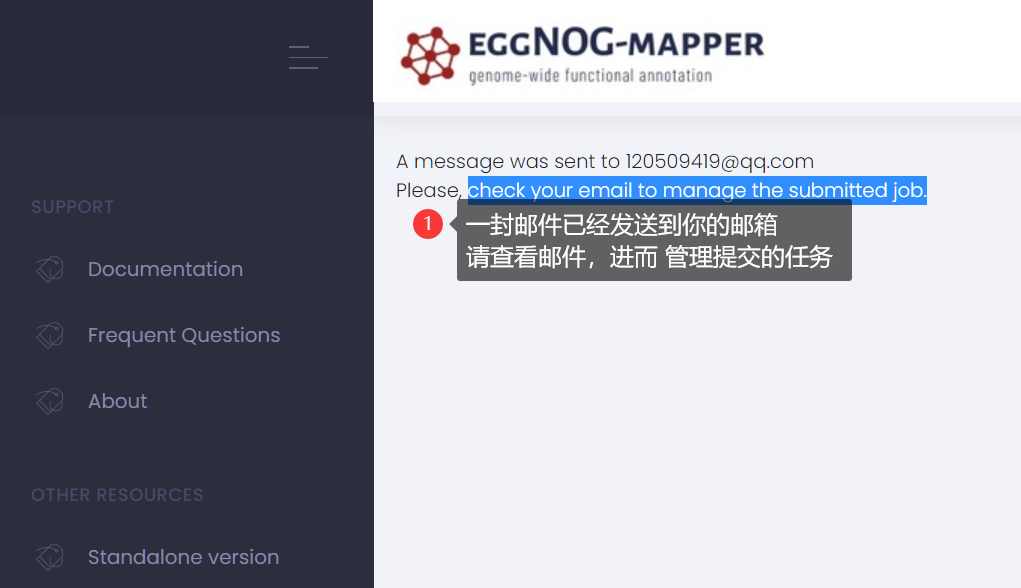
随后,检查自己的邮箱,可以看到如下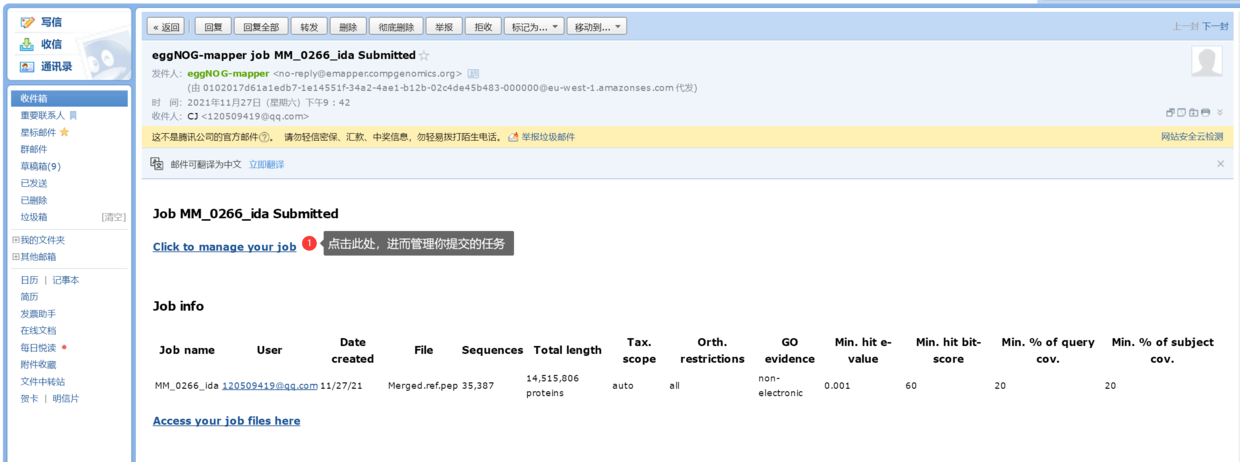
打开收到的邮件,其中有“Click to manage your job”,点击即可看到(如果点击进去,看不到任何东西,那么请复制该链接,使用 谷歌浏览器 、火狐浏览器、edge浏览器 任意一个打开)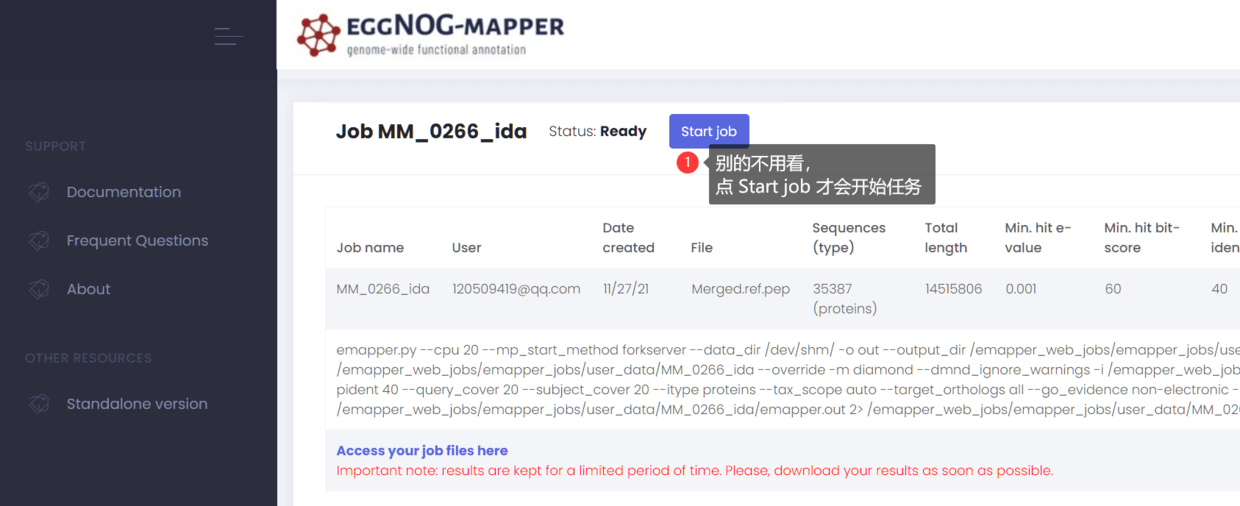
点击 “Start job”即可,然后可以去打球或者去休息,上个洗手间等等。
任务完成时,会自动发送邮件到邮箱,当然也可以选择过几分钟来看看这个页面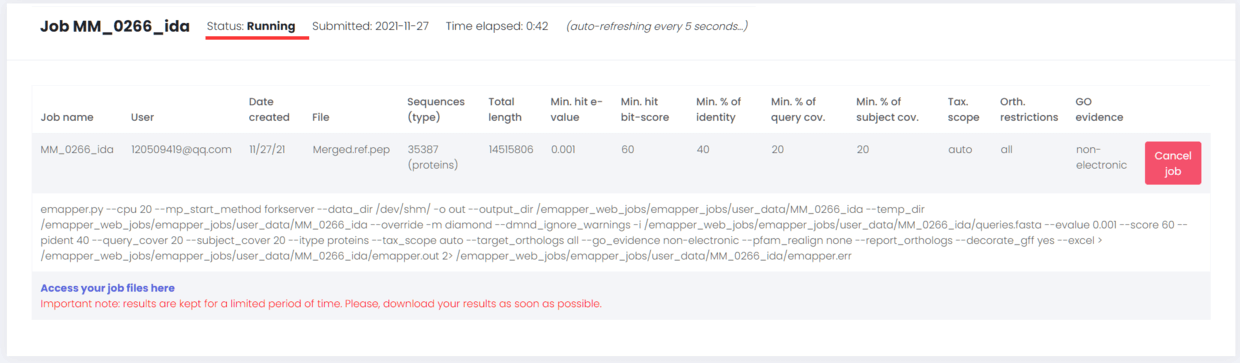
这是我昨天邮箱里的邮件,也是此次的示例文件来源
进入任务完成的邮件,可以看到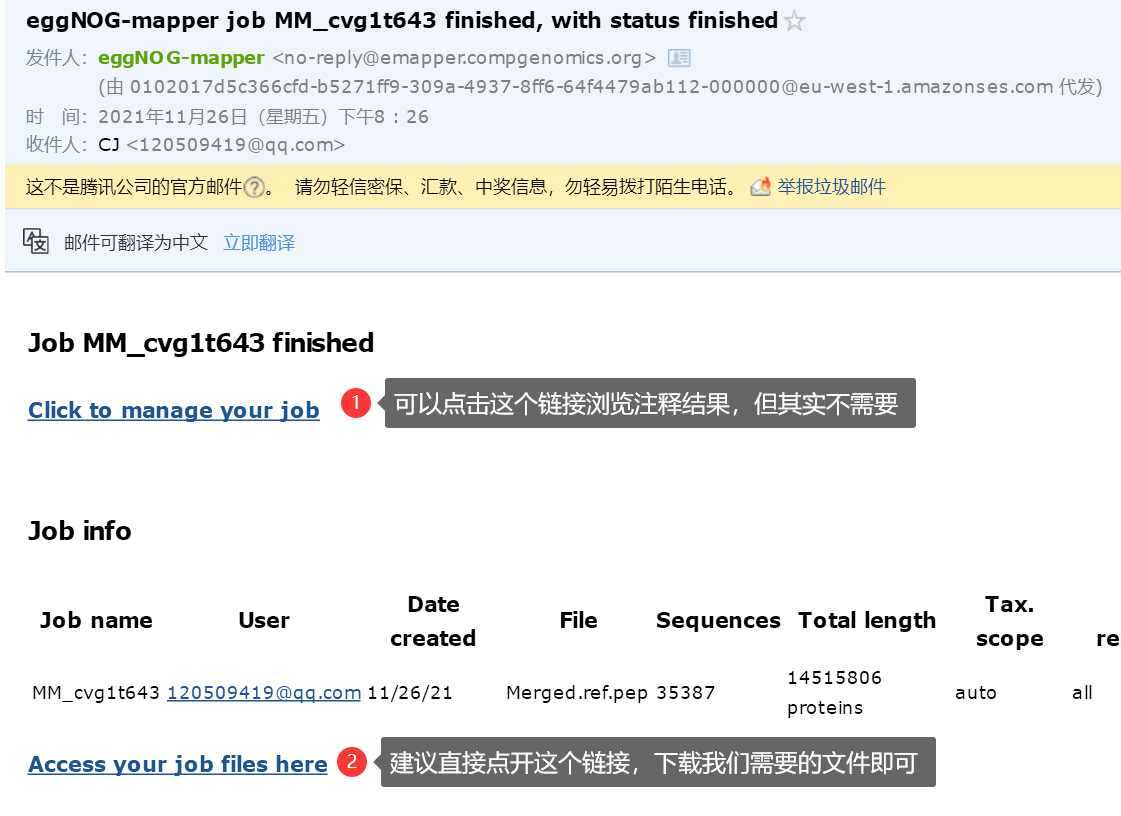
建议直接点击第二个链接下载我们需要的文件,但是你也可以打开第一个文件,那么会看到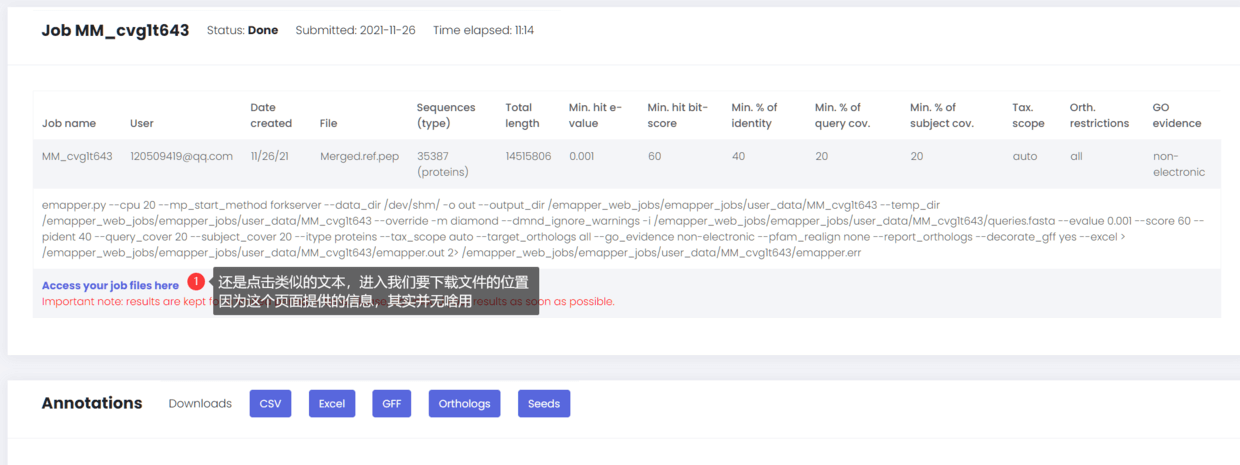
最后还是会进入文件下载链接,看到如下
下载的是一个制表符分隔的文本文件,你可以用 Excel 打开,结果如下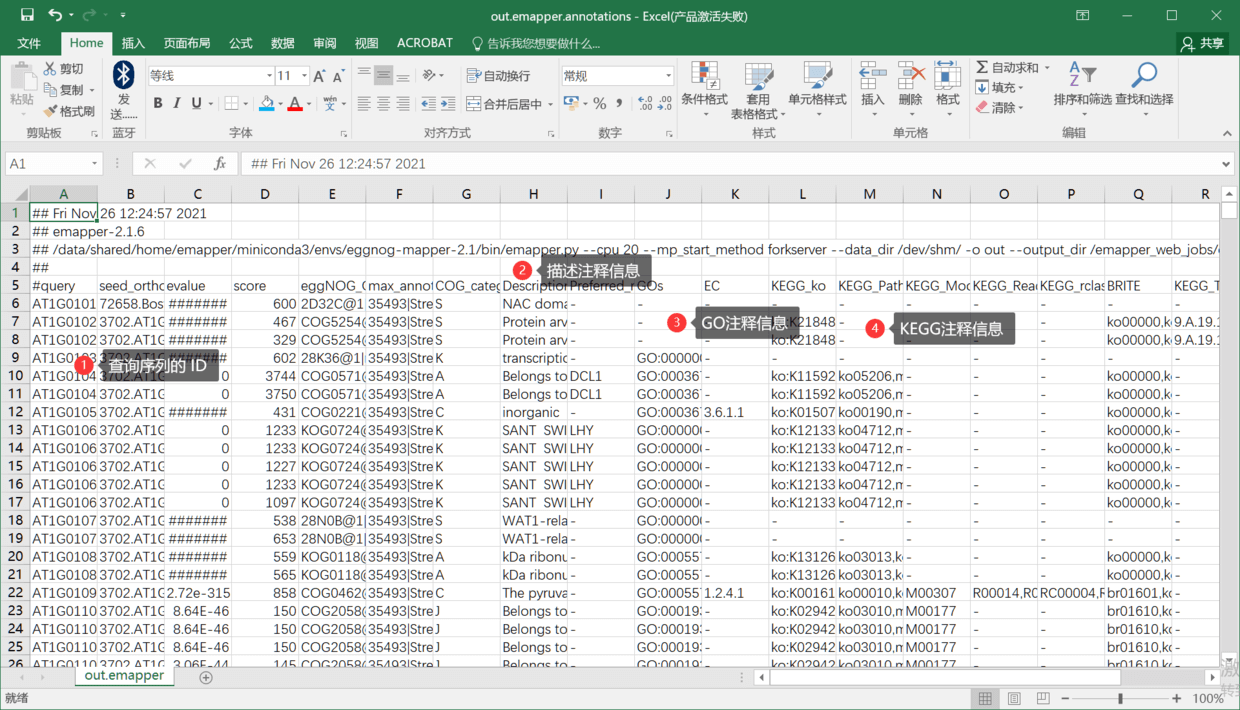
结果很全面,只是还是不能满足我们的需求,或者说,这里开始可能才是不少 TBtools 用户遇到的问题。那就是怎么整理这些信息,用于TBtools的 GO富集分析或者KEGG富集分析?
eggNOG-mapper Helper
为了解决这个问题,我想来想去,还是谢了一个功能,就叫 eggNOG-mapper Helper,可以一键直接整理 eggNOG-mapper 的结果,输出几个文件,分别满足不同下游分析需要。
功能如下,注意更新到 v1.9868 或更高版本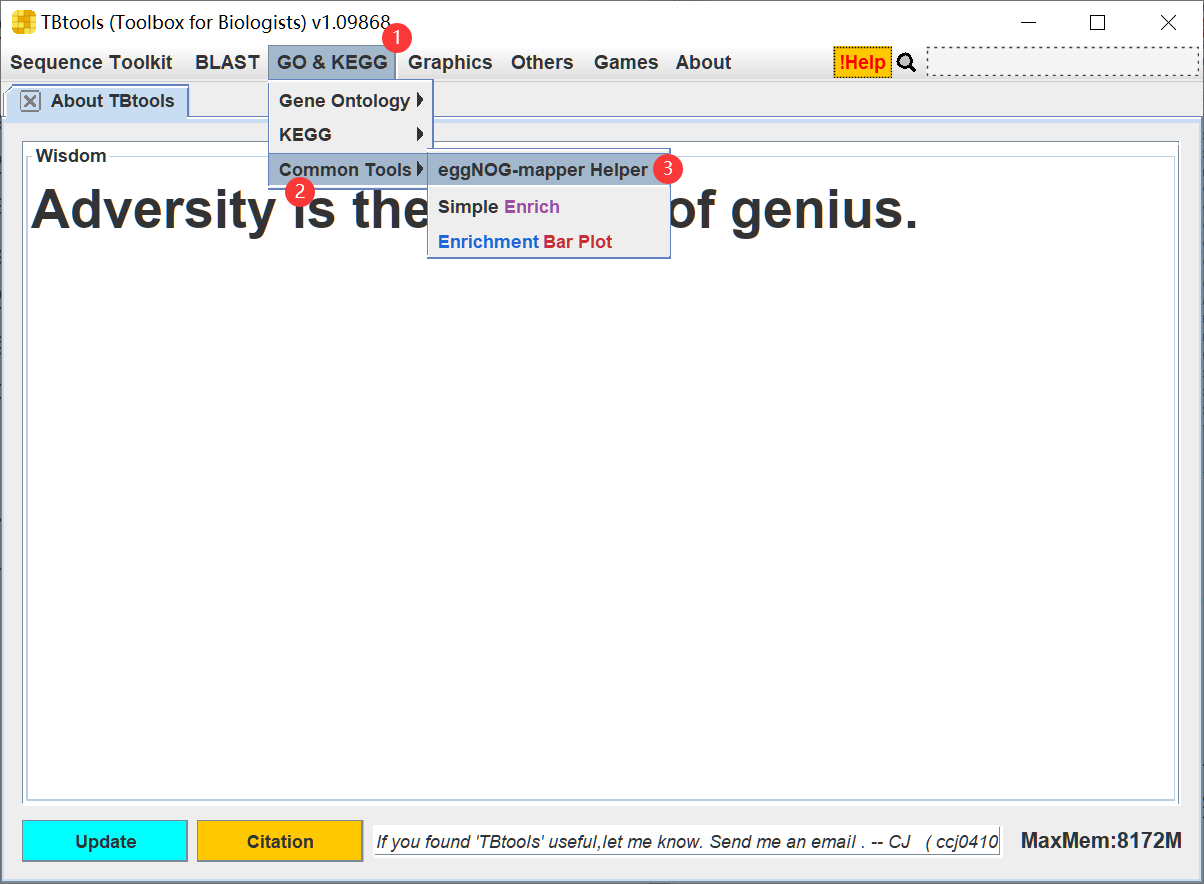
打开该功能,可见非常简单的输入界面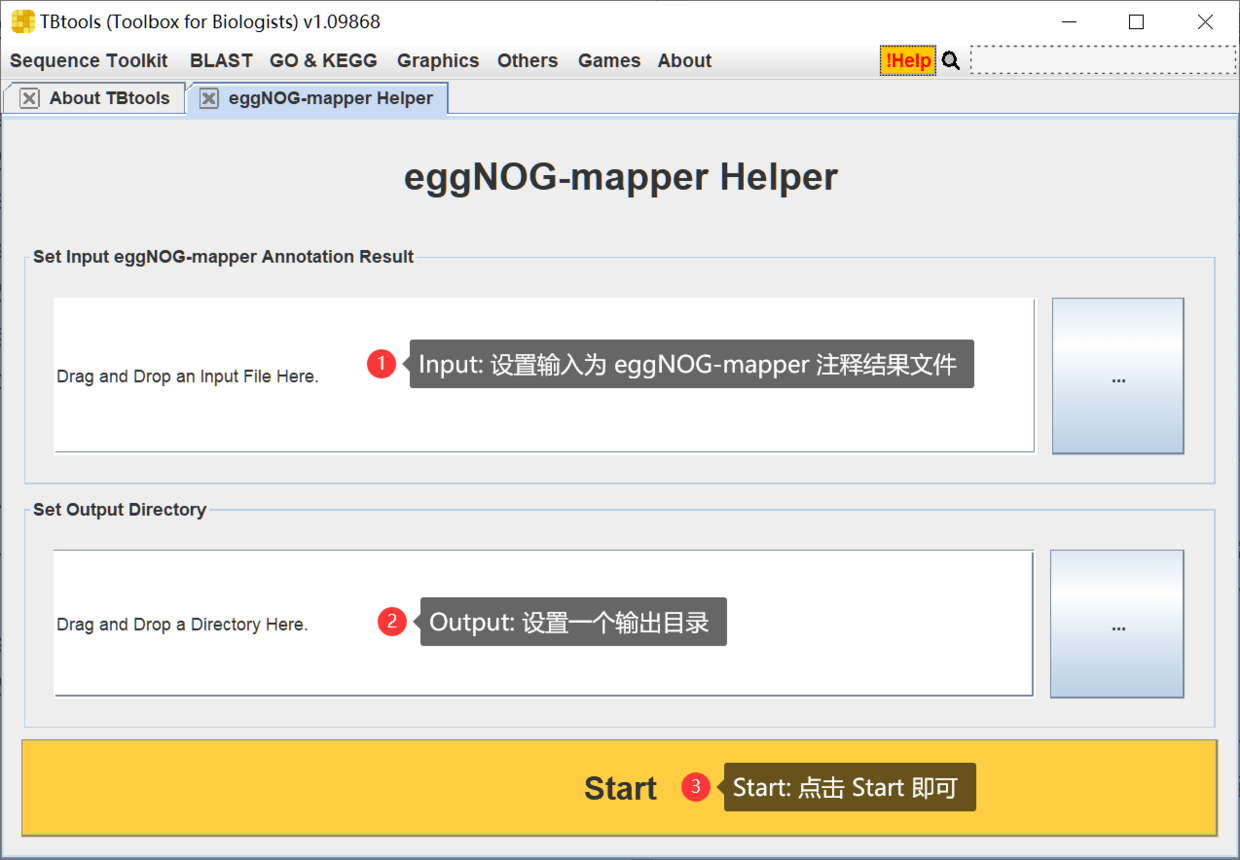
使用非常简单,具体示例如下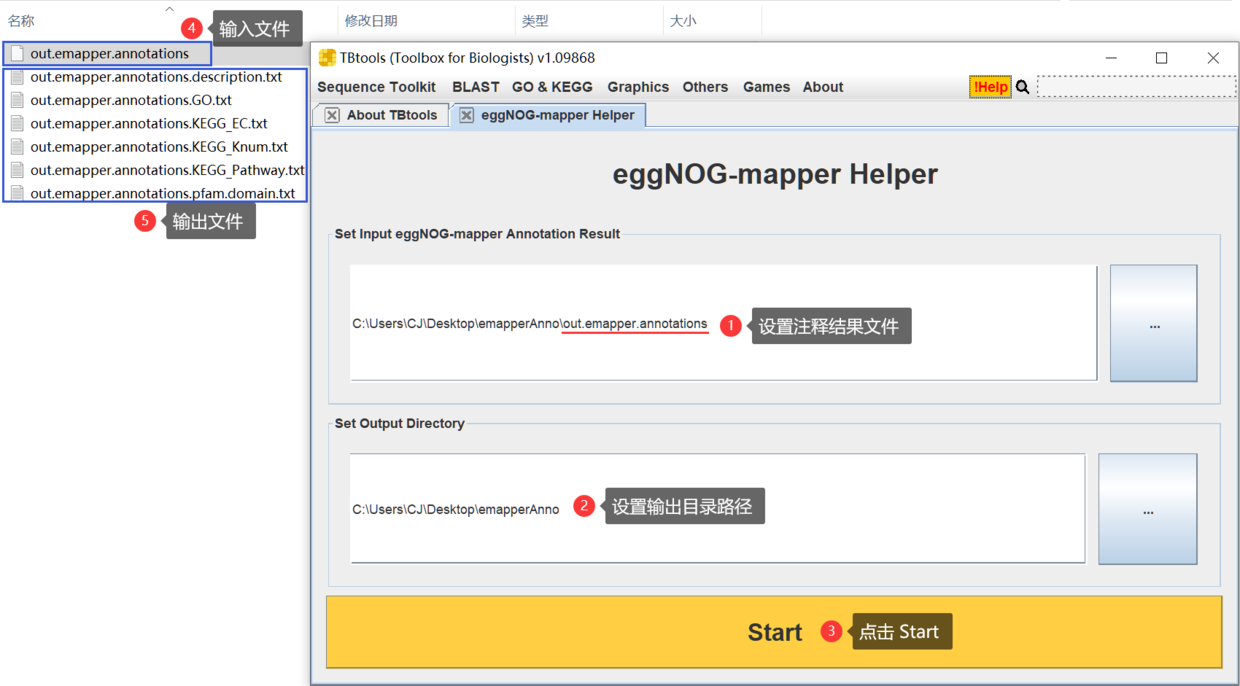
输出文件中,大家可能最关注的有四个:
out.emapper.annotations.description.txt,对应的功能文本描述out.emapper.annotations.GO.txt,对应的是GO注释结果,可直接用于 TBtools GO富集分析,当注释背景文件out.emapper.annotations.KEGG_Knum.txt,对应的是KEGG注释结果,可直接用于 TBtools KEGG富集分析,当背景注释文件out.emapper.annotations.pfam.domain.txt,对应的是PFAM结构域注释,注意,这个注释结果是定性的,即有无某结构域,如果一个序列有多个相同结构域,只会显示一个
四个文件的具体信息,截图可看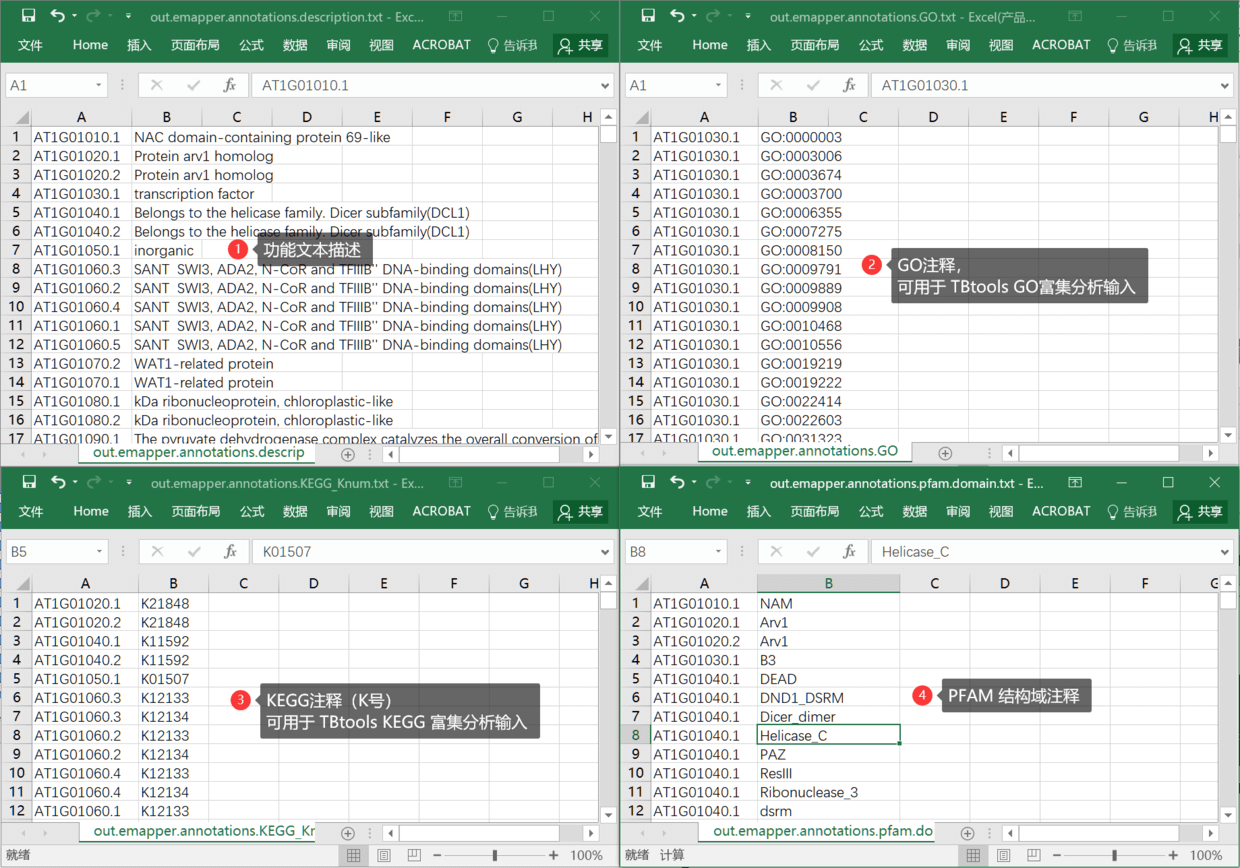
(注意,尽管我使用 Excel 打开,但这些文件仍然是制表符分隔的文本文件,千万不要保存为 Excel 格式,以免有后续问题)
写在最后
Emmm… 很久没有写教程了,不过我觉得这个教程应该还是比较详细,完全可以解决几乎所有人的 GO 或者 KEGG 甚至是基因功能注释的烦恼。

若有收获,就点个赞吧
0 人点赞
