相较于其他 Fasta 序列操作功能,这一功能的主要特点即,Quick。主要原因有二:
- 通过IO优化,加速文件读取
- 无需建立索引
这一功能最适用的场景为 序列完整纪录 的 提取 或 过滤。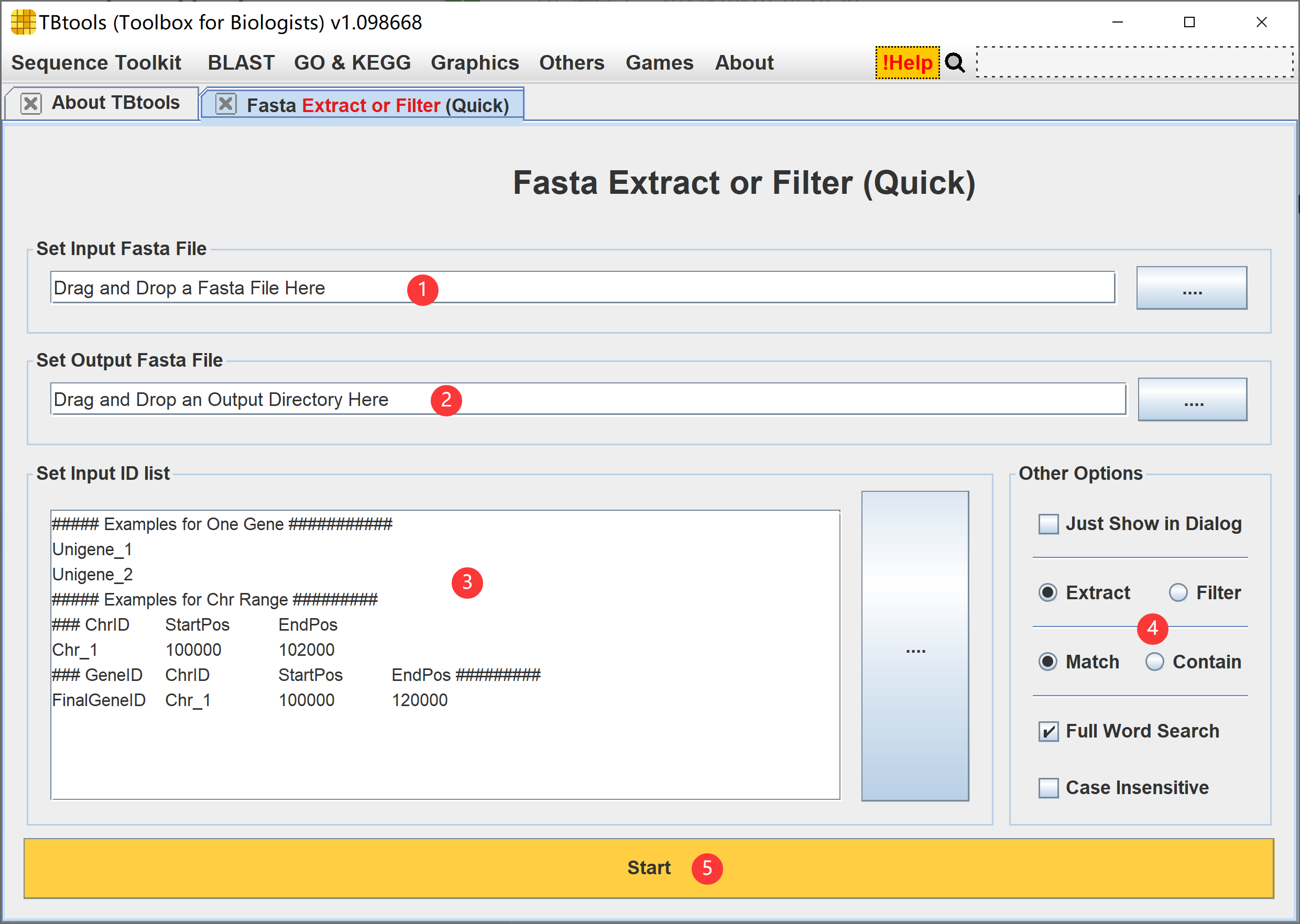
参数详解如下:
- 设置输入的 Fasta 序列文件,可以直接拖拽放置序列文件,也可以直接点击文本框后面的“…”摁钮,在弹出的文件选择框中选择对应文件即可。
- 设置输出的文件路径,可以直接拖拽放置或通过摁钮选择
- 设置待提取或待过滤的ID信息,支持模式如下:
- 序列 ID ,可用于提取序列完整记录或过滤对应记录
- 序列区间坐标,如“Chr1 100000 102000”,提取 Chr1 上从第100000到102000的碱基序列。注意事项有二:a) 制表符分隔,而不是空白符分隔;b) Quick 模式,不支持一个染色体提取多个区间(如有需要,建议使用 Fasta Extract (Recommended)功能)
- 支持提取序列 ID 重命名
- 其他可选参数:
- Just Show in Dialog,即直接弹窗显示输出,而不输出到文件,对提取少量序列或者区间的情况,较为实用
- Extract or Filter,即选择提取模式,还是过滤模式。注意过滤模式不支持区间过滤,仅支持完整 ID 过滤
- Match or Contain,即 ID 完全匹配还是包含,对应“MYB10”不完全匹配“MYB”但包含“MYB”
- Full Word Search,是否全词匹配,即“MYB10”只匹配“MYB10”不匹配“MYB101”
- Case Insensitive,是否支持 大小写不敏感
注意到,这一功能无需建立索引。

若有收获,就点个赞吧
0 人点赞
