JVM参数调忧
默认启动的Broker进程只会使用1G内存,在实际使用中会导致进程频繁GC,影响Kafka集群的性能和稳定性
通过jstat -gcutil <pid> 1000 10查看到kafka进程GC情况(查看进程xxx的GC情况,每1000ms打印一次,打印10次)
主要看YGC,YGCT,FGC,FGCT这几个参数,如果这几个值不是很大,就没什么问题
:::info
YGC:young gc发生的次数
YGCT:young gc消耗的时间
FGC:full gc发生的次数
FGCT:full gc消耗的时间
:::
[root@bigdata1 kafka_2.12-2.4.1]# jps105466 Kafka[root@bigdata1 apache-zookeeper-3.5.8-bin]# jstat -gcutil 105466 1000 10S0 S1 E O M CCS YGC YGCT FGC FGCT GCT0.00 100.00 53.94 43.75 89.69 91.69 34 0.356 0 0.000 0.3560.00 100.00 53.94 43.75 89.69 91.69 34 0.356 0 0.000 0.3560.00 100.00 53.94 43.75 89.69 91.69 34 0.356 0 0.000 0.3560.00 100.00 53.94 43.75 89.69 91.69 34 0.356 0 0.000 0.3560.00 100.00 53.94 43.75 89.69 91.69 34 0.356 0 0.000 0.3560.00 100.00 53.94 43.75 89.69 91.69 34 0.356 0 0.000 0.3560.00 100.00 53.94 43.75 89.69 91.69 34 0.356 0 0.000 0.3560.00 100.00 53.94 43.75 89.69 91.69 34 0.356 0 0.000 0.3560.00 100.00 53.94 43.75 89.69 91.69 34 0.356 0 0.000 0.3560.00 100.00 53.94 43.75 89.69 91.69 34 0.356 0 0.000 0.356
如果你发现YGC很频繁,或者FGC很频繁,就说明内存分配的少了
此时需要修改kafka-server-start.sh中的 KAFKA_HEAP_OPTS
:::info
export KAFKA_HEAP_OPTS=”-Xmx10g -Xms10g -XX:MetaspaceSize=96m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80”
:::
这个配置表示给kafka分配了10G内存,我们的Kafka服务器是16G内存
Replication参数调忧
replica.socket.timeout.ms=60000
这个参数的默认值是30秒,它是控制partiton副本之间socket通信的超时时间,如果设置的太小,有可能会由于网络原因导致造成误判,认为某一个partition副本连不上了。replica.lag.time.max.ms=50000
如果一个副本在指定的时间内没有向leader节点发送任何请求,或者在指定的时间内没有同步完leader中的数据,则leader会将这个节点从Isr列表中移除。 这个参数的值默认为10秒
如果网络不好,或者kafka压力较大,建议调大该值,否则可能会频繁出现副本丢失,进而导致集群需要频繁复制副本,导致集群压力更大,会陷入一个恶性循环
Log参数调忧
这块是针对Kafka中数据文件的删除时机进行设置,不是对kafka本身的日志参数配置log.retention.hours=24
这个参数默认值为168,单位是小时,就是7天,默认对数据保存7天,可以在这调整数据保存的时间,我们在实际工作中改为了只保存1天,因为kafka中的数据我们会在hdfs中进行备份,保存一份,所以就没有必要在kafka中保留太长时间了。 在kafka中保留只是为了能够让你在指定的时间内恢复数据,或者重新消费数据,如果没有这种需求,那就没有必要设置太长时间。
注意: 这里分析的Replication的参数和Log参数都是在server.properties文件中进行配置 JVM参数是在kafka-server-start.sh脚本中配置
Kafka Topic命名小技巧
针对Kafka中Topic命名的小技巧
建议在给topic命名的时候在后面跟上r2p10之类的内容
r2:表示Partition的副本因子是2
p10:表示这个Topic的分区数是10
这样的好处是后期我们如果要写消费者消费指定topic的数据,通过topic的名称我们就知道应该设置多少个消费者消费数据效率最高。
因为一个partition同时只能被一个消费者消费,所以效率最高的情况就是消费者的数量和topic的分区数量保持一致。
在这里通过topic的名称就可以直接看到,一目了然。
但是也有一个缺点,就是后期如果我们动态调整了topic的partiton,那么这个topic名称上的partition数量就不准了,针对这个topic,建议大家一开始的时候就提前预估一下,可以多设置一些partition,我们在工作中的时候针对一些数据量比较大的topic一般会设置40~50个partition,数据量少的topic一般设置5~10个partition,这样后期调整topic partiton数量的场景就比较少了。
Kafka集群监控管理工具(CMAK)
现在我们操作Kafka都是在命令行界面中通过脚本操作的,后面需要传很多参数,用起来还是比较麻烦的,那kafka没有提供web界面的支持吗?
很遗憾的告诉你,Apache官方并没有提供,不过好消息是有一个由雅虎开源的一个工具,目前用起来还是不错的。
它之前的名字叫KafkaManager,后来改名字了,叫CMAK
CMAK是目前最受欢迎的Kafka集群管理工具,最早由雅虎开源,用户可以在Web界面上操作Kafka集群
可以轻松检查集群状态(Topic、Consumer、Offset、Brokers、Replica、Partition)
下载地址:https://github.com/yahoo/CMAK/releases
注意:由于cmak-3.0.0.5.zip版本是在java11这个版本下编译的,所以在运行的时候也需要使用java11这个版本,我们目前服务器上使用的是java8这个版本
我们为什么不使用java11版本呢?因为自2019年1月1日1起,java8之后的更新版本在商业用途的时候就需要收费授权了。
在这针对cmak-3.0.0.5这个版本,如果我们想要使用的话有两种解决办法
1:下载cmak的源码,使用jdk8编译
2:额外安装一个jdk11
如果想要编译的话需要安装sbt这个工具对源码进行编译, sbt 是 Scala 的构建工具, 类似于 Maven。
由于我们在这使用不属于商业用途,所以使用jdk11是没有问题的,那就不用重新编译了。
下载jdk11,jdk-11.0.7_linux-x64_bin.tar.gz
将jdk11的安装包上传到/data/soft目录下
只需要解压即可,不需要配置环境变量,因为只有cmak这个工具才需要使用jdk11
tar -zxvf jdk-11.0.7_linux-x64_bin.tar.gz
上传cmak-3.0.0.5.zip到/data/soft目录下
1:解压
yum install -y unzipunzip cmak-3.0.0.5.zip
2:修改CMAK配置 首先修改bin目录下的cmak脚本 在里面配置JAVA_HOME指向jdk11的安装目录,否则默认会使用jdk8
cd cmak-3.0.0.5/binvi cmak....JAVA_HOME=/data/soft/jdk-11.0.7.....
然后修改conf目录下的application.conf文件 只需要在里面增加一行cmak.zkhosts参数的配置即可,指定zookeeper的地址
注意:在这里指定zookeeper地址主要是为了让CMAK在里面保存数据,这个zookeeper地址不一定是kafka集群使用的那个zookeeper集群,随便哪个zookeeper集群都可以。
cd conf/vi application.conf....cmak.zkhosts="bigdata1:2181"....
3:修改kafka启动配置
想要在CMAK中查看kafka的一些指标信息,在启动kafka的时候需要指定JMX_PORT
停止kafka集群
cd /data/soft/kafka_2.12-2.4.1bin/kafka-server-stop.sh
重新启动kafka,指定JXM_PORT
JMX_PORT=9988 bin/kafka-server-start.sh -daemon config/server.properties
4:启动cmak
bin/cmak -Dconfig.file=conf/application.conf -Dhttp.port=9001
如果想把cmak放在后台执行的话需要添加上nohup和&
nohup bin/cmak -Dconfig.file=conf/application.conf -Dhttp.port=9001 &
5:访问cmak:http://bigdata1:9001/
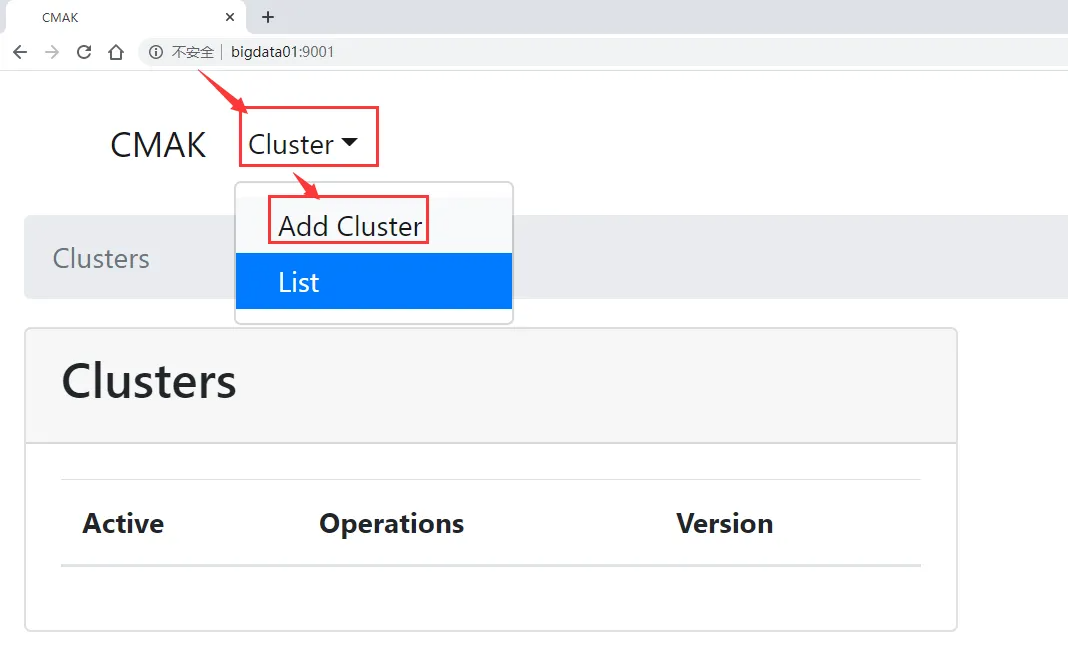
6:操作CMAK
- 添加集

这几个参数配置好了以后还需要配置以下几个线程池相关的参数,这几个参数默认值是1,在保存的时候会提示需要大于1,所以可以都改为10
:::info
brokerViewThreadPoolSize:10
offsetCacheThreadPoolSize:10
kafkaAdminClientThreadPoolSize:10
:::
最后点击Save按钮保存即可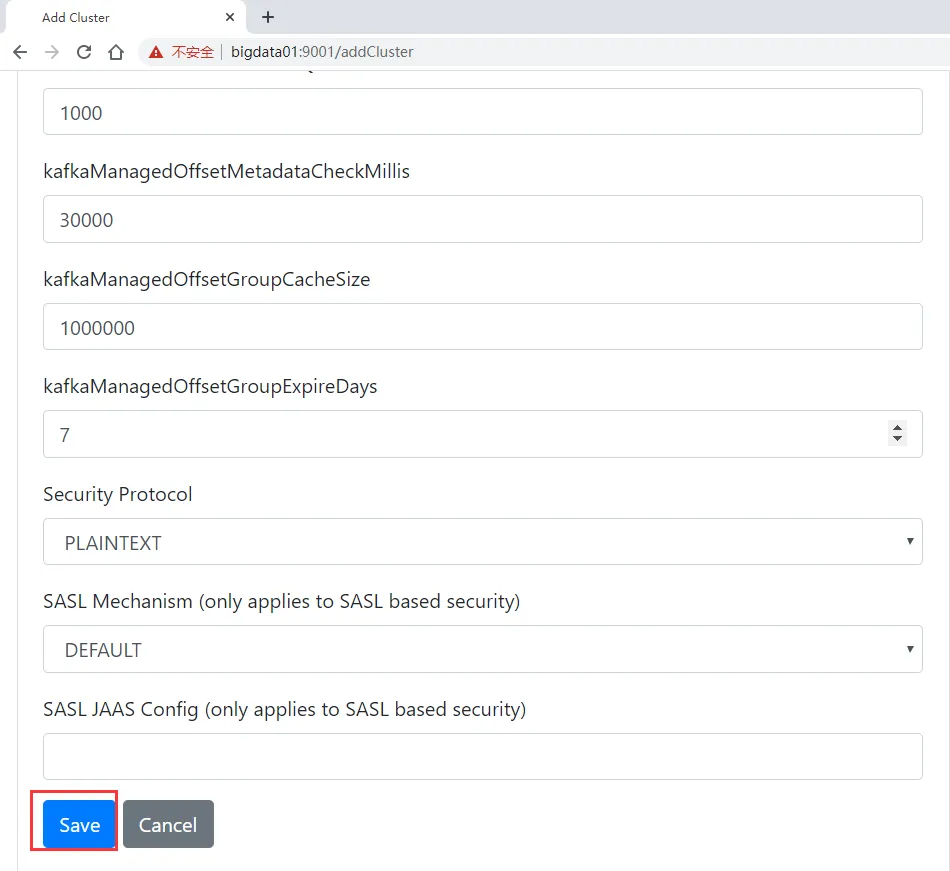
最后进来是这样的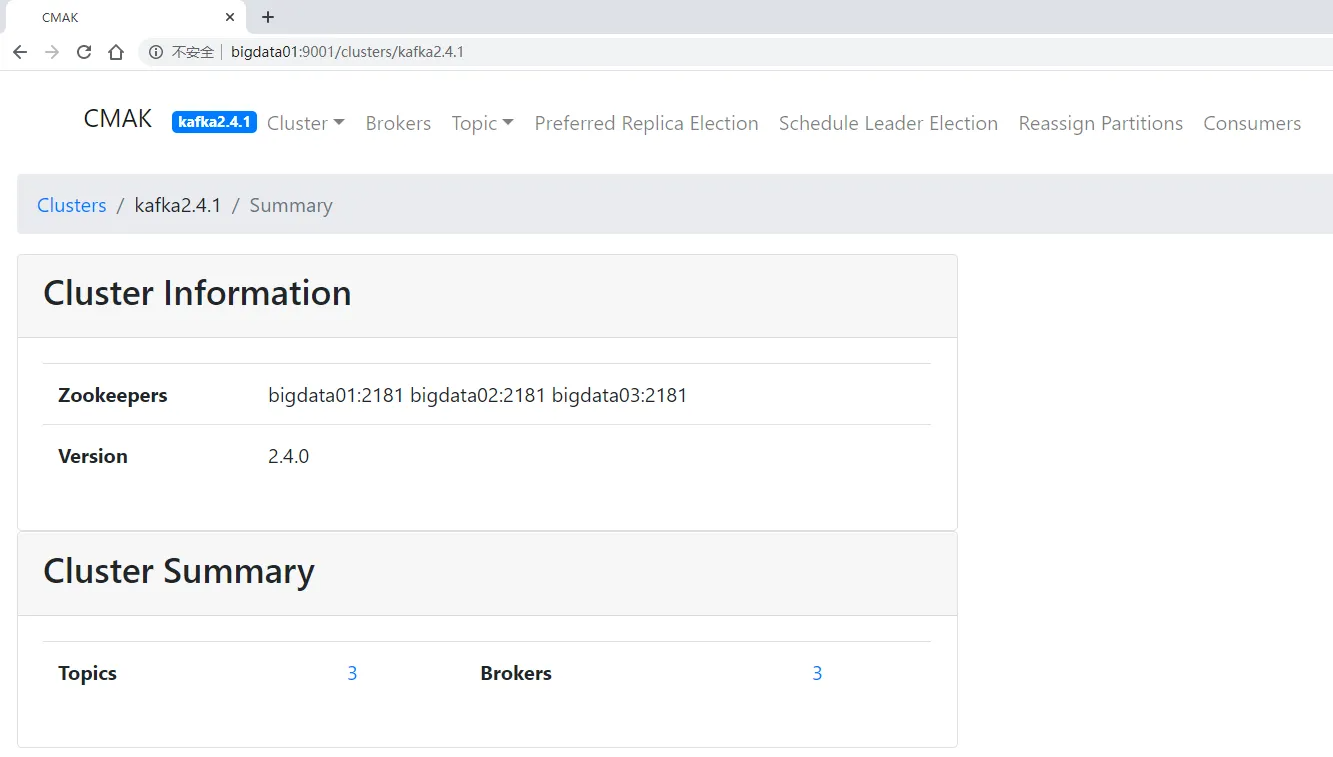
查看kafak集群的所有broker信息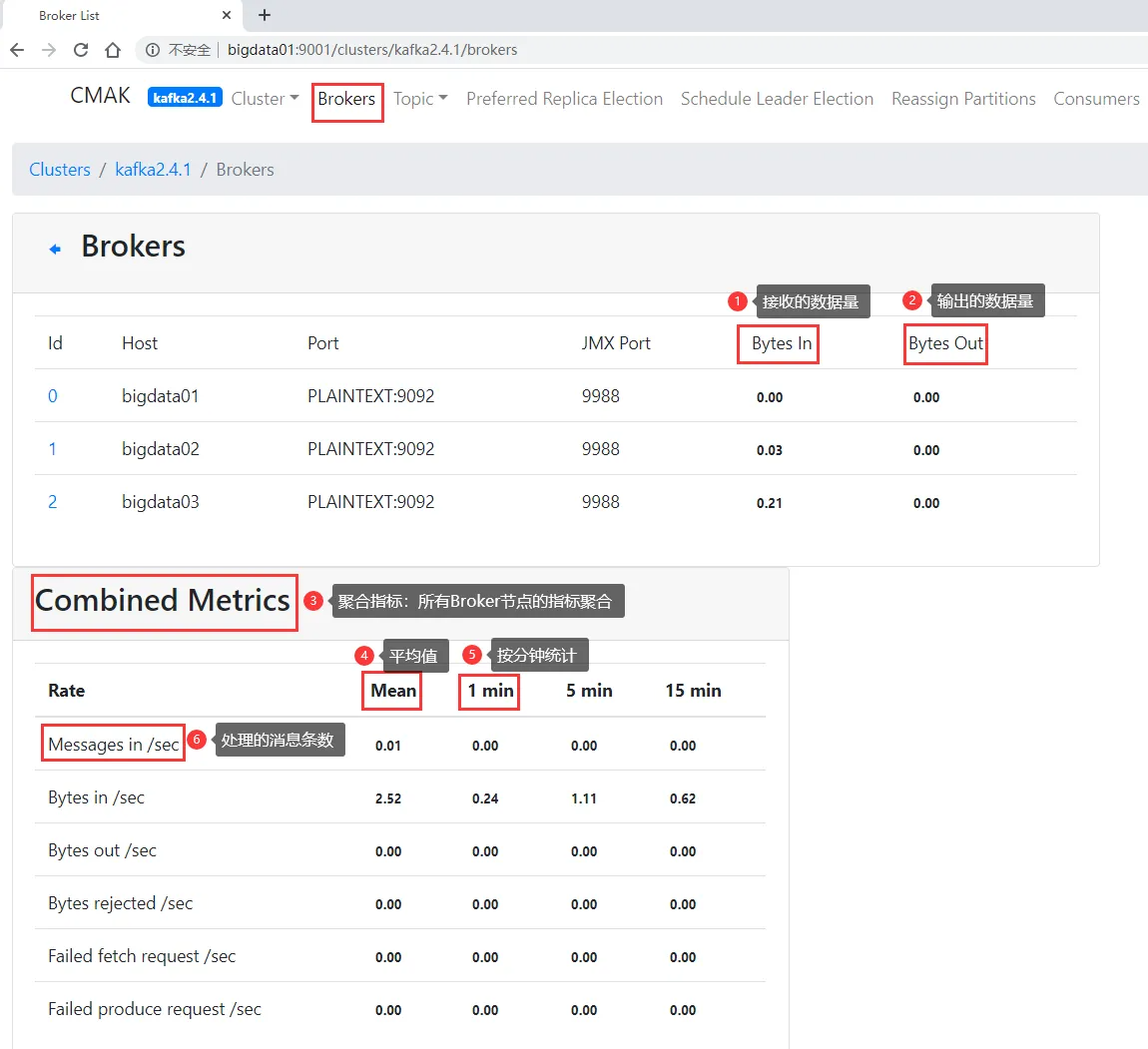
查看kafak集群的所有topic信息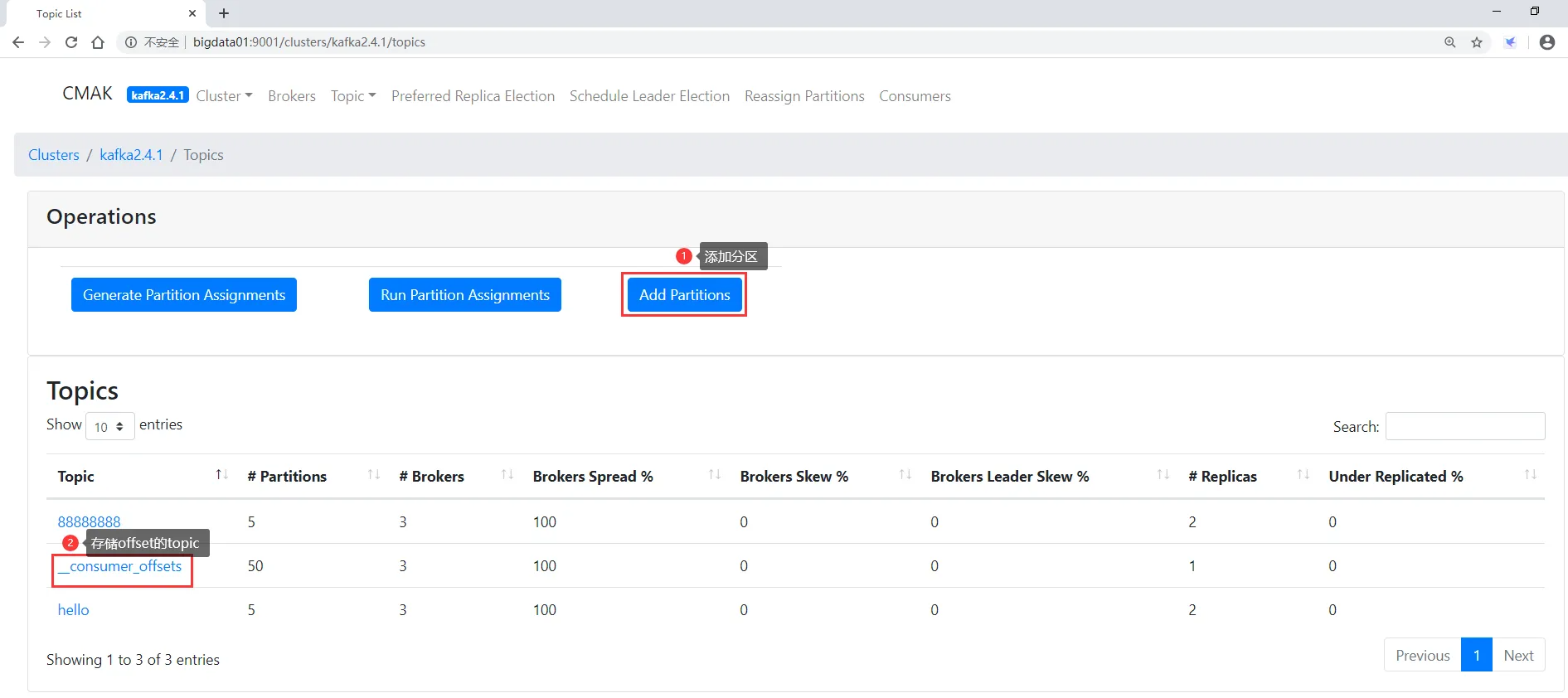
查看某一个topic的详细信息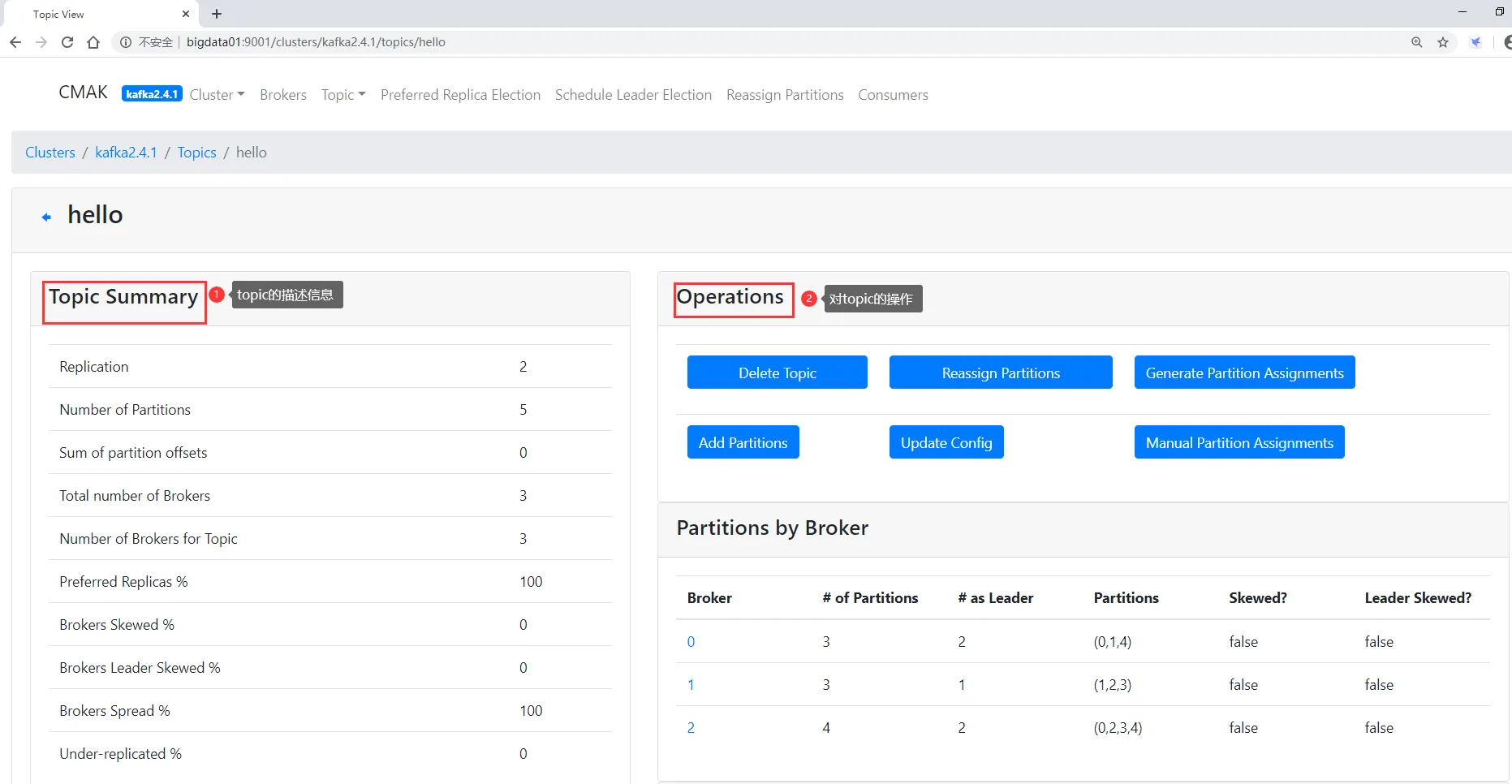
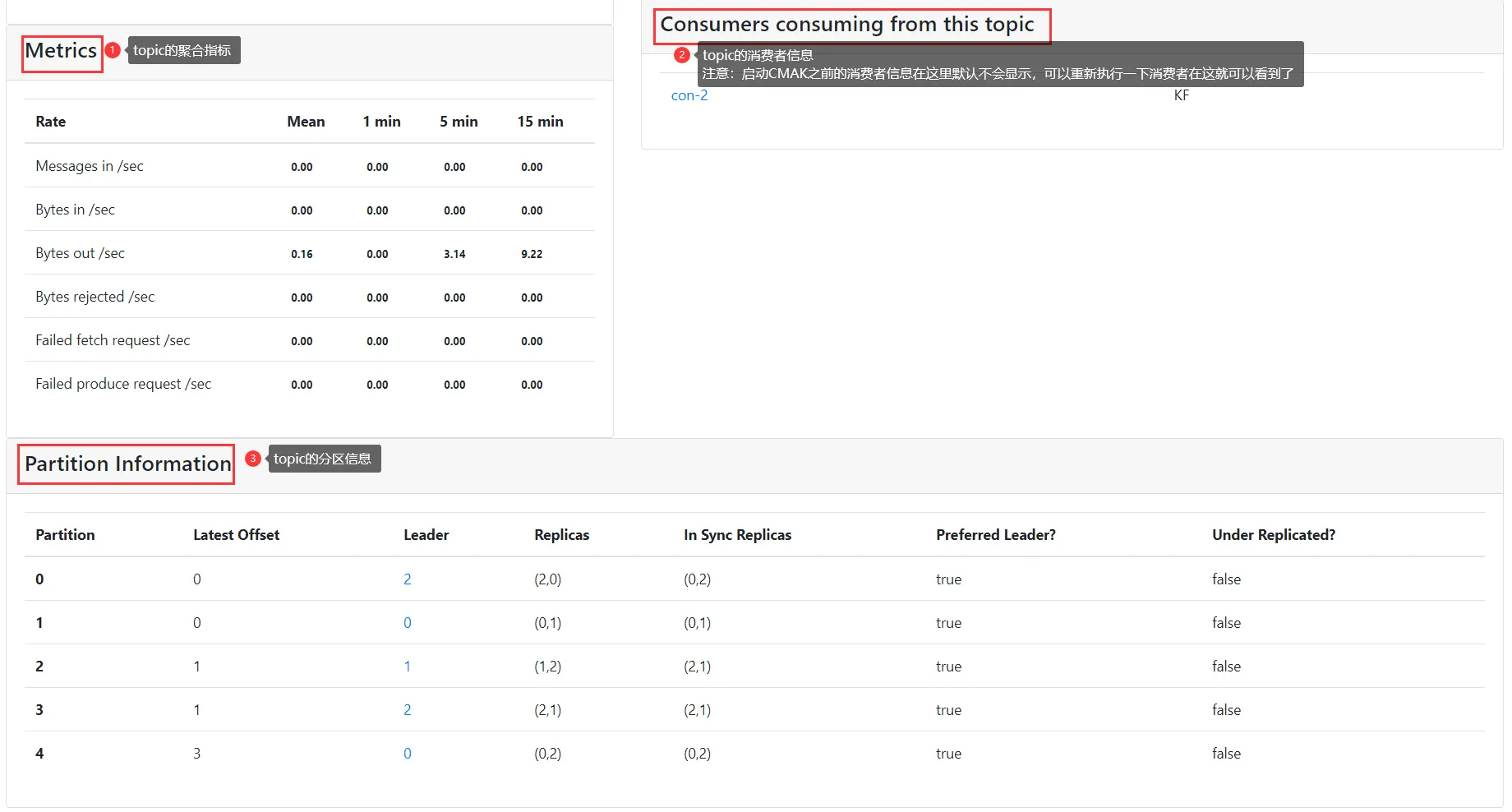
点击topic的消费者信息是可以进来查看的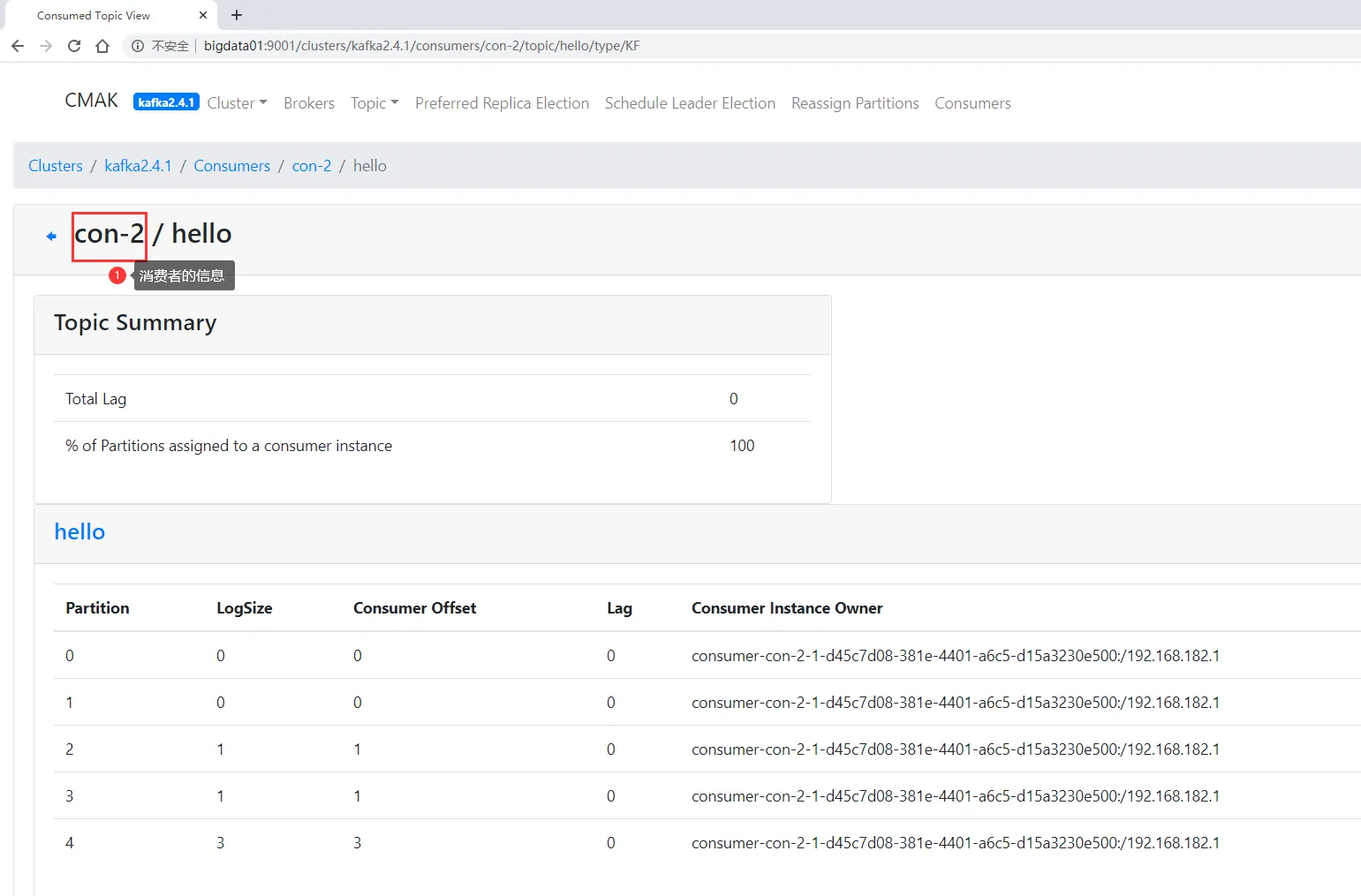
创建一个topic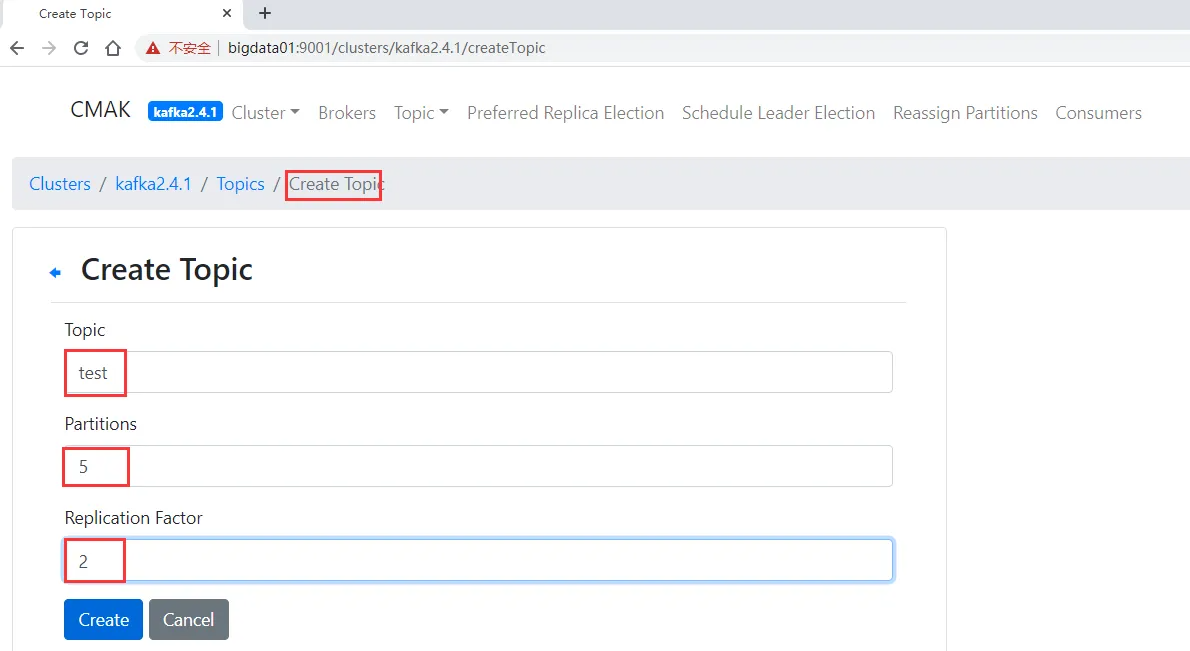
给topic增加分区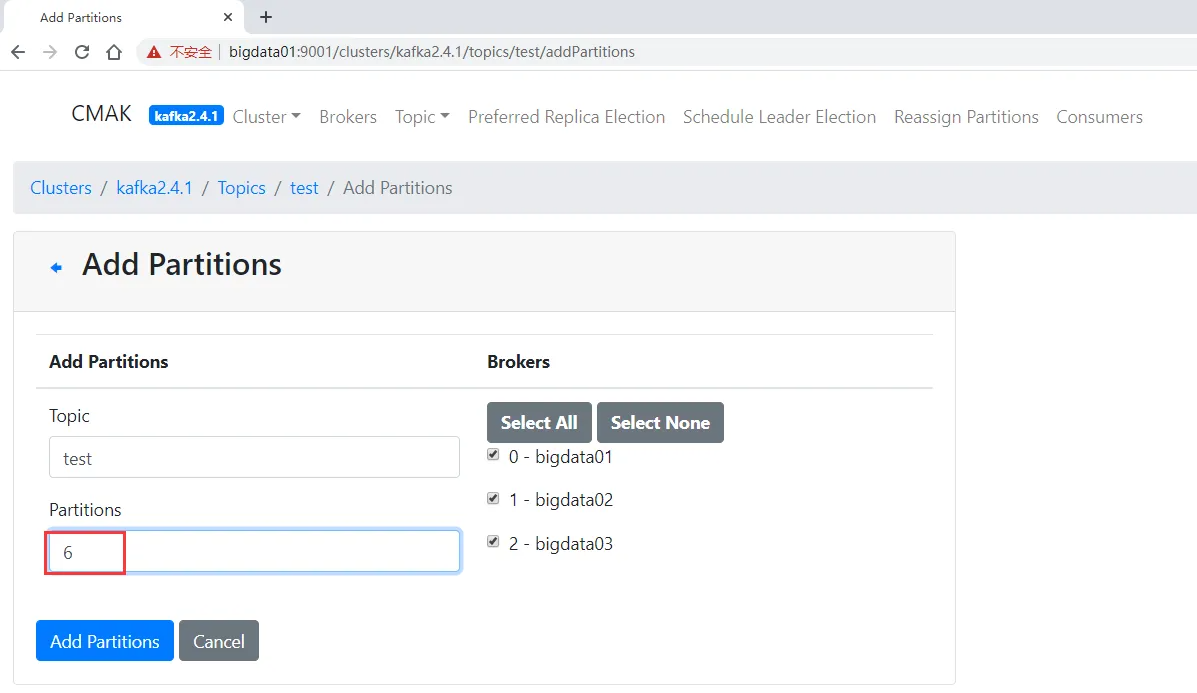
这是CMAK中常见的功能,当然了这里面还要一些我们没有说到的功能就留给大家以后来发掘了。

若有收获,就点个赞吧
0 人点赞
