数据库的操作
查看数据库
show databases;
Hive的数据是存在HDFS上面的,default数据库的目录在HDFS的/user/hive/warehouse
Hive 会为每个创建的数据库在 HDFS 上创建一个目录,该数据库中的表会以子目录的形式存储。表中的数据会以文件的形式存储。
数据库的信息在 Metastore 中也有记录,在 hive 数据库中的 dbs 表里,如下图所示:
创建数据库
create database mydb1;
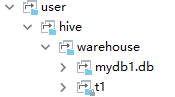
如果不希望创建的数据库在这个目录下面,想要手工指定,那也是可以的,在创建数据库的时候通过location来指定hdfs目录的位置
create database mydb2 location '/user/hive/mydb2';
选择数据库
use mydb1;
删除数据库
drop database mydb2;
DROP DATABASE IF EXISTS hive2 或者是 DROP DATABASE hive2。 加上 IF EXISTS,可以避免要删除的数据库不存在而引起的警告。
hive (hive2)> DROP DATABASE IF EXISTS hive2;
默认情况下,Hive 不允许删除非空数据库,如果强行删除,会出现下面这样的错误信息。
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask.
InvalidOperationException(message:Database hive2 is not empty. One or more tables exist.)
使用CASCADE语句,则表示删除数据库时,会将其中的表一起删除,
hive (hive2)> DROP DATABASE IF EXISTS hive2 CASCADE;
OK
Time taken: 0.288 seconds
hive (hive2)>
当某个数据库被删除后,其对应的HDFS目录也将被一起删除。
表的操作
创建表
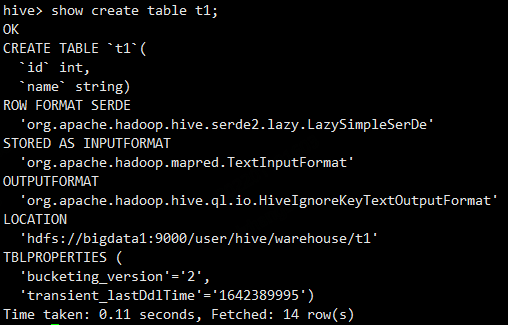
create table t1(id int,name string);
create table t2(id int);
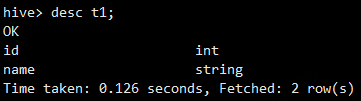
查看表信息
desc t1;
查看创建表SQL
show create table t1;
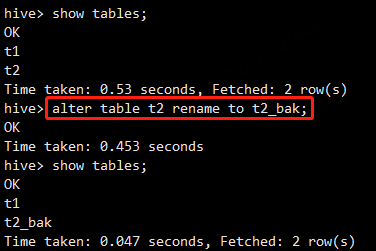
修改表名
alter table t2 rename to t2_bak;
表增加字段和注释
alter table t2 add columns (column_2 int);
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
如果你的表创建了分区的话就要再执行两条命令:
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
删除表
drop table t2;
加载数据(load)
前面向表中添加数据是使用的insert命令,其实使用insert向表里面添加数据只是在测试的时候使用,实际中向表里面添加数据很少使用insert命令的
在 Hive 中,没有行级别的数据插入、数据更新和删除操作。向 Hive 表一次性地装载大量数据的命令为 LOAD DATA,语法如下:
LOAD DATA [local] INPATH 'filepath' [overwrite] INTO TABLE table_name [partition(part1=val1,part2= val2)]
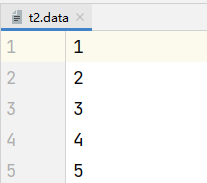
示例:将本地的/data/soft/hivedata/t2.data文件数据加载到t2表中
上传测试数据
cd /data/soft/hivedata
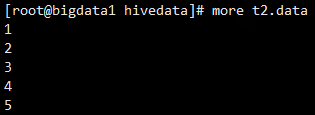
将t2.data加载到t2
load data local inpath '/data/soft/hivedata/t2.data' into table t2;
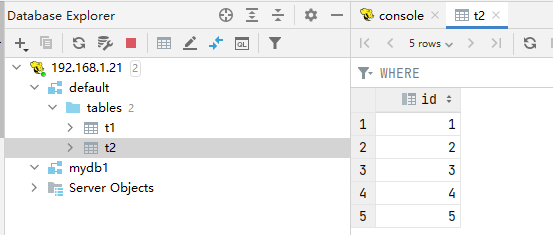
们到hdfs上去看一下这个表,发现刚才的文件其实就是上传到了t2目录中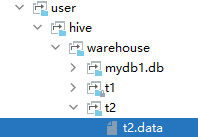
指定列和行的分隔符
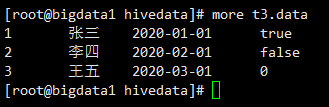
示例:将本地的/data/soft/hivedata/t3.data文件数据加载到t3表中
建表
create table t3
(
id int,
stu_name string,
stu_birthday date,
online boolean
) ;
加载
load data local inpath '/data/soft/hivedata/t3.data' into table t3;
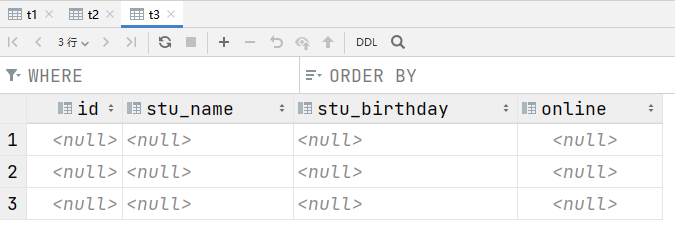
可以发现无法解析数据,因为没有指定行分隔符,列分隔符 实际上,hive是有默认的分隔符的,默认的行分隔符是
'\n',就是换行符,列分隔符是\001。
重新创建表t3_new,指定列分隔符\t(制表符),行分隔符\n
create table t3_new
(
id int,
stu_name string,
stu_birthday date,
online boolean
) row format delimited
fields terminated by '\t'
lines terminated by '\n';
注意:
lines terminated by行分隔符可以忽略不写,但是如果要写的话,只能写到最后面。
再次加载:
load data local inpath '/data/soft/hivedata/t3.data' into table t3_new;
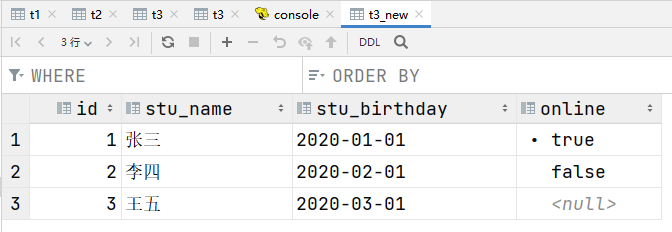
注意,针对无法识别的数据显示为NULL,因为最后一列为boolean类型,但是在数据中我故意指定了一个数字,所以导致无法解析,但是不会导致数据加载失败,也不会导致查询失败,这就是hive的特性,他不会提前检查数据,只有在使用的时候才会检查数据,如果数据有问题就显示为null,也不报错。

若有收获,就点个赞吧
0 人点赞
