需求:Flume按天把日志数据采集到HDFS中的对应目录中,使用SQL按天统计每天数据的相关指标
使用外部分区表和视图实现:Flume采集数据存储到HDFS,按天按、类型分目录存储,Hive建外部分区表绑定这些目录。
Flume采集数据
原始数据:
video_info{"id":"14943445328940974601","uid":"840717325115457536","lat":"53.530598","lnt":"-2.5620373","hots":0,"title":"0","status":"1","topicId":"0","end_time":"1494344570","watch_num":0,"share_num":"1","replay_url":null,"replay_num":0,"start_time":"1494344544","timestamp":1494344571,"type":"video_info"}user_info{"uid":"861848974414839801","nickname":"mick","usign":"","sex":1,"birthday":"","face":"","big_face":"","email":"abc@qq.com","mobile":"","reg_type":"102","last_login_time":"1494344580","reg_time":"1494344580","last_update_time":"1494344580","status":"5","is_verified":"0","verified_info":"","is_seller":"0","level":1,"exp":0,"anchor_level":0,"anchor_exp":0,"os":"android","timestamp":1494344580,"type":"user_info"}gift_record{"send_id":"834688818270961664","good_id":"223","video_id":"14943443045138661356","gold":"10","timestamp":1494344574,"type":"gift_record"}
Flume按天把日志数据保存到HDFS中的对应目录中
针对Flume的source可以使用execsource、channel可以使用基于文件的或者内存的,sink使用hdfssink,在hdfssink的path路径中需要使用%Y%m%d获取日期,将每天的日志数据采集到指定的hdfs目录中
这个是我们在前面分享Flume的时候已经讲过的了,这个倒不难
后面就是需要对按天采集的日志数据建表,由于这份数据可能会被多种计算引擎使用,所以建议使用外部表,这样就算我们不小心把表删了,数据也还是在的,不影响其他人使用,还有就是这份数据是按天分目录存储的,在实际工作中,离线计算的需求大部分都是按天计算的,所以在这里最好在表中增加日期这个分区字段,所以最终决定使用外部分区表。
前面FLume采集数据的流程我们就不再演示了,在这我就直接使用之前我们使用hdfs落盘的数据了。
目录结构是这样的,首先是按天,然后是按照类型
这里面的数据是json格式的,也是有规律的,如果我们在建表的时候该怎么创建?
[root@bigdata1 ~]# hdfs dfs -cat /moreType/20220111/giftRecord/*
{"send_id":"834688818270961664","good_id":"223","video_id":"14943443045138661356","gold":"10","timestamp":1494344574,"type":"giftRecord"}
建外部分区表
针对json格式的数据建表的时候没办法直接把每个字段都定义出来。
通常的解决方案是先写一个mapreduce数据清洗任务,只需要map阶段就行了,对json格式的数据进行解析,把里面每个字段的值全部解析出来,拼成一行,字段值中间可以使用逗号分割,然后再基于解析之后的数据在hive中建表就可以了。
这个解决方案没有任何问题,如果硬要挑问题,那就只能鸡蛋里面挑骨头,说这个解决方案比较麻烦,还需要写MapReduce,不够优雅了。
我们开发人员有时候一定要懒,这个懒不是说什么都不敢,而是要想办法把复杂的问题简单化,这个懒可以督促你去找出最方便快捷的解决方案。
在这里我们需要提前涉及一个函数get_json_object,这个函数可以从json格式的数据中解析出指定字段
所以我的思路是这样的,
先基于原始的json数据创建一个外部分区表,表中只有一个字段,保存原始的json字符串即可,分区字段是日期和数据类型
然后再创建一个视图,视图中实现的功能就是查询前面创建的外部分区表,在查询的时候会解析json数据中的字段
这样就方便了,我们以后查询直接查视图就可以查询出我们需要的字段信息了,并且一行代码都不需要写。
下面开始建表
create external table ex_par_more_type
(
log string
) partitioned by (dt string,d_type string)
row format delimited
fields terminated by '\t'
location '/moreType';
加载数据
【注意,此时的数据已经通过flume采集到hdfs中了,所以不需要使用load命令了,只需要使用一个alter命令添加分区信息就可以了,但是记得要把那三个子目录都添加进去】
绑定分区
【注意,这个步骤每天都要做一次】
alter table ex_par_more_type add partition(dt='20220111',d_type='giftRecord') location '/moreType/20220111/giftRecord';
alter table ex_par_more_type add partition(dt='20220111',d_type='userInfo') location '/moreType/20220111/userInfo';
alter table ex_par_more_type add partition(dt='20220111',d_type='videoInfo') location '/moreType/20220111/videoInfo';
创建视图
接下来就是重点了,需要创建视图,在创建视图的时候从数据中查询需要的字段信息
注意了,由于这三种类型的数据字段是不一样的,所以创建一个视图还搞不定,只能针对每一种类型创建一个视图。
如果这三种类型的数据字段都是一样的,就可以只创建一个视图了。
注意:由于字段数量太多,在这里针对每个每种数据只获取里面的前4个字段
giftRecord类型的视图
create view gift_record_view as
select get_json_object(log, '$.send_id') as send_id
, get_json_object(log, '$.good_id') as good_id
, get_json_object(log, '$.video_id') as video_id
, get_json_object(log, '$.gold') as gold
, dt
from ex_par_more_type
where d_type = 'giftRecord';

userInfo类型的视图
create view user_info_view as
select get_json_object(log, '$.uid') as uid
, get_json_object(log, '$.nickname') as nickname
, get_json_object(log, '$.usign') as usign
, get_json_object(log, '$.sex') as sex
, dt
from ex_par_more_type
where d_type = 'userInfo';

videoInfo类型的视图
create view video_info_view as
select get_json_object(log, '$.id') as id
, get_json_object(log, '$.uid') as uid
, get_json_object(log, '$.lat') as lat
, get_json_object(log, '$.lnt') as lnt
, dt
from ex_par_more_type
where d_type = 'videoInfo';

后面想要查询数据就直接通过视图,指定日期查询就可以了,不指定日期的话会查询这个类型下面所有的数据。
创建添加分区脚本
其实到这里还没完,因为后期flume每天都会采集新的数据上传到hdfs上面,所以我们需要每天都做一次添加分区的操作。
这个操作肯定是要写到脚本中定时调度的,否则每天手工执行还不疯了
开发脚本,脚本名称为addPartition.sh
#!/bin/bash
# 每天凌晨1点定时添加当天日期的分区
if [ "a$1" = "a" ]
then
dt=`date +%Y%m%d`
else
dt=$1
fi
# 指定添加分区操作
hive -e "
alter table ex_par_more_type add partition(dt='${dt}',d_type='giftRecord') location '/moreType/${dt}/giftRecord';
alter table ex_par_more_type add partition(dt='${dt}',d_type='userInfo') location '/moreType/${dt}/userInfo';
alter table ex_par_more_type add partition(dt='${dt}',d_type='videoInfo') location '/moreType/${dt}/videoInfo';
"

注意:此脚本不能重复执行,如果指定的分区已存在,重复添加分区会报错,为了避免报错,可以这样修改一下,添加if not exists

#!/bin/bash
# 每天凌晨1点定时添加当天日期的分区
if [ "a$1" = "a" ]
then
dt=`date +%Y%m%d`
else
dt=$1
fi
# 指定添加分区操作
hive -e "
alter table ex_par_more_type add if not exists partition(dt='${dt}',d_type='giftRecord') location '/moreType/${dt}/giftRecord';
alter table ex_par_more_type add if not exists partition(dt='${dt}',d_type='userInfo') location '/moreType/${dt}/userInfo';
alter table ex_par_more_type add if not exists partition(dt='${dt}',d_type='videoInfo') location '/moreType/${dt}/videoInfo';
"
在执行脚本之前把之前添加的分区先删一下
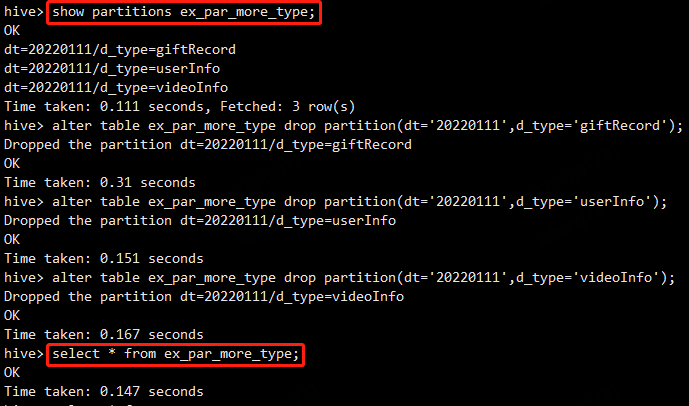
show partitions ex_par_more_type;
alter table ex_par_more_type drop partition(dt='20220111',d_type='giftRecord');
alter table ex_par_more_type drop partition(dt='20220111',d_type='userInfo');
alter table ex_par_more_type drop partition(dt='20220111',d_type='videoInfo');
执行脚本
sh addPartition.sh 20220111

添加crontab
这个脚本需要配置一个定时任务,每天凌晨1点执行,可以使用crontab
00 01 * * * root sh /root/myShell/addPartition.sh >> /root/myShell/addPartition.log
总结
这就是一个完整的开发流程,针对需要多次执行的sql一般都是需要配置到脚本中使用hive -e去执行的。
最后再来分析一下,针对这个需求如果数据量不算太打,并且大家对计算效率要求也不算太高的话是没有问题的。
因为现在这种逻辑是每次在查询视图的时候会对原始数据进行解析再计算,如果每天的数据量达到几百G,甚至上T的时候,查询效率就有点低了,大致需要10~20分钟左右,每次查询都是这样,不管你查询多少次,,每次都要根据原始数据进行解析。
如果感觉这个时间不能接受,想要优化,那只能从源头进行优化了,就是先对原始的json数据进行清洗,把需要的字段解析出来,存储到hdfs中,再建表,这个时候就可以提高效率了,因为对原始数据解析的过程只需要一次,后期计算的时候都是对解析过的数据直接计算了,省略了解析步骤,效率可以提升一倍以上。
所以这个就要综合实际情况去考虑了,选便捷性还是选效率。

若有收获,就点个赞吧
0 人点赞
