什么是Hive
Apache Hive 是建立在 Hadoop 之上的开源数据仓库系统,可以将存储在 Hadoop 文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似 SQL 的查询模型,称为 Hive 查询语言(HQL),用于访问和分析存储在 Hadoop 文件中的大型数据集。Hive 核心是将 HQL 转换为 MapReduce 程序,然后将程序提交到 Hadoop 群集执行。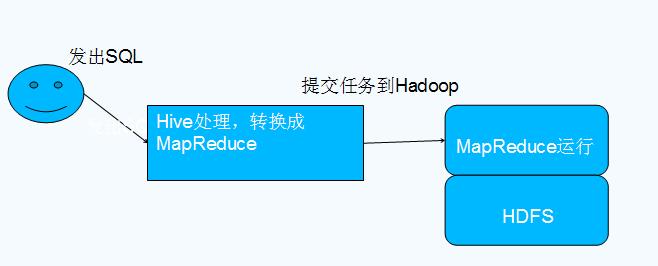
Hive的数据存储
大部分的查询由 MapReduce 完成(包含 的查询,比如 select from table 不会生成 MapRedcue 任务)
Hive的数据存储基于Hadoop的 HDFS
Hive没有专门的数据存储格式,Hive默认可以直接加载文本文件(TextFile),还支持SequenceFile、RCFile等文件格式
针对普通文本数据,我们在创建表时,只需要指定数据的列分隔符与行分隔符,Hive即可解析里面的数据
hive的系统架构
看这个图,下面表示是Hadoop集群,上面是Hive,从这也可以看出来Hive是基于Hadoop的。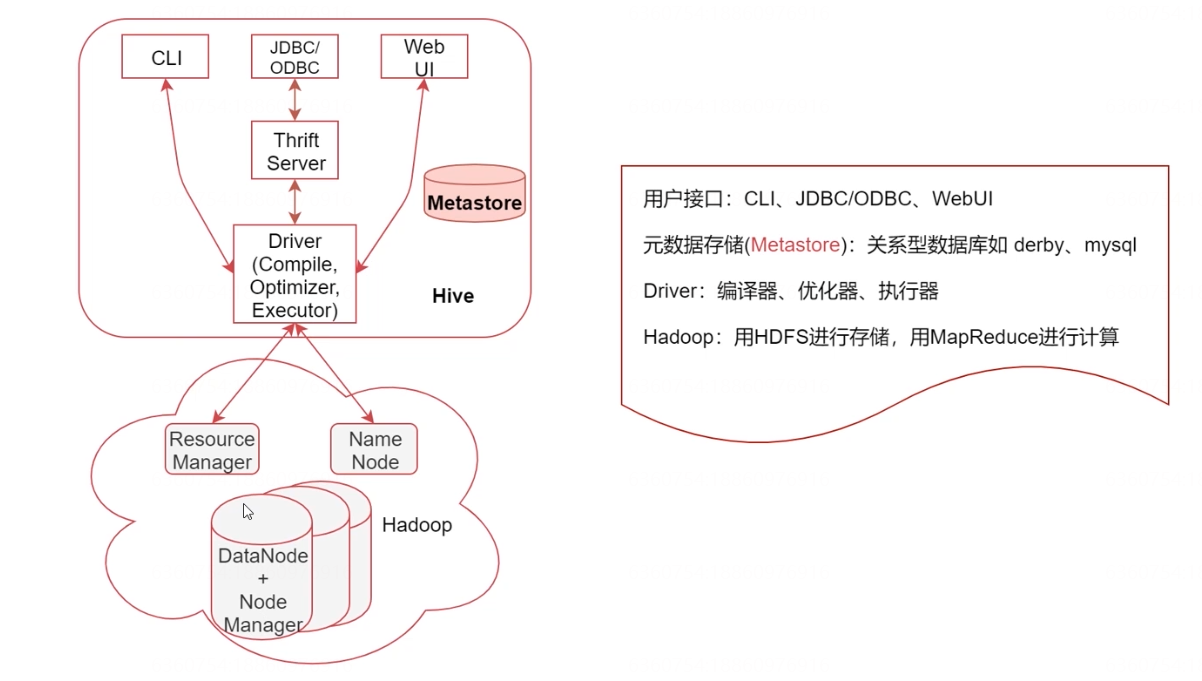
看右边的几个概念的解释
- 用户接口,包括 CLI、JDBC/ODBC、WebGUI
- CLI,即Shell命令行,表示我们可以通过shell命令行操作Hive
- JDBC/ODBC 是 Hive 的Java操作方式,与使用传统数据库JDBC的方式类似
- WebUI是通过浏览器访问 Hive
- 元数据存储(Metastore),注意:这里的存储是名词,Metastore表示是一个存储系统
- Hive中的元数据包括表的相关信息,Hive会将这些元数据存储在Metastore中,目前Metastore只支持 mysql、derby。
- Driver:包含:编译器、优化器、执行器
- 编译器、优化器、执行器可以完成 Hive的 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划最终存储在 HDFS 中,并在随后由 MapReduce 调用执行
- Hadoop:Hive会使用 HDFS 进行存储,利用 MapReduce 进行计算
- Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(特例 select * from table 不会生成 MapRedcue 任务,如果在SQL语句后面再增加where过滤条件就会生成MapReduce任务了。)
大数据计算引擎发展

MapReduce
第一代大数据计算引擎:MapReduce
在这有一点需要注意的,就是从Hive2开始,其实官方就不建议默认使用MapReduce引擎了,而是建议使用Tez引擎或者是Spark引擎,不过目前一直到最新的3.x版本中mapreduce还是默认的执行引擎。Tez
第二代大数据计算引擎:Tez,Tez的存在感比较低,它是源于MapReduce,主要和Hive结合在一起使用,它的核心思想是将Map和Reduce两个操作进一步拆分,这些分解后的元操作可以灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可以形成一个大的作业,这样可以提高计算效率,我们在实际工作中Hive使用的就是 Tez引擎,替换Hive的执行引擎也很简单,只需要把Tez安装好(Tez也是支持在YARN上执行的),然后到Hive中配置一下就可以了,不管使用什么引擎,不会对我们使用hive造成什么影响,也就说对上层的使用没有影响。Spark
第三代大数据计算引擎:Spark,Spark在当时属于一个划时代的产品,改变了之前基于磁盘的计算思路,而是采用内存计算,就是说Spark把数据读取过来以后,中间的计算结果是不会进磁盘的,一直到出来最终结果,才会写磁盘,这样就大大提高了计算效率,而MapReduce的中间结果是会写磁盘的,所以效率没有Spark高。Spark的执行效率号称比MapReduce 快100倍,当然这需要在一定数据规模下才会差这么多,如果我们就计算几十兆或者几百兆的文件,你去对比发现其实也不会差多少,后面我也会分享到Spark这个基于内存的大数据计算引擎。注意:spark也是支持在YARN上执行的
- Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(特例 select * from table 不会生成 MapRedcue 任务,如果在SQL语句后面再增加where过滤条件就会生成MapReduce任务了。)
Flink
第四代大数据计算引擎,:Flink,Flink是一个可以支持纯实时数据计算的计算引擎,在实时计算领域要优于Saprk,Flink和Spark其实是有很多相似之处,在某些方面他们两个属于互相参考,互相借鉴,互相成长,Flink后面我也会分享到,等后面我分享到这个计算引擎的时候再详细分析。
注意:Flink也是支持在YARN上执行的。
所以发现没有,MapReduce、Tez、Spark、Flink这些计算引擎都是支持在yarn上执行的,所以说Hadoop2中对架构的拆分是非常明智的。
解释完这些名词之后其实我们就对这个架构有了一个基本理解。
再看来这个图
用户通过接口传递Hive SQL,然后经过Driver对SQL进行分析、编译,生成查询计划,查询计划会存储在HDFS中,然后再通过MapReduce进行计算出结果,这就是整个大的流程。
其实在这里我们可以发现,Hive这个哥们是既不存储数据,也不计算数据,这些活都给了Hadoop来干,Hive底层最核心的东西其实就是Driver这一块,将SQL语句解析为最终的查询计划。
Metastore

数据库和数据仓库的区别
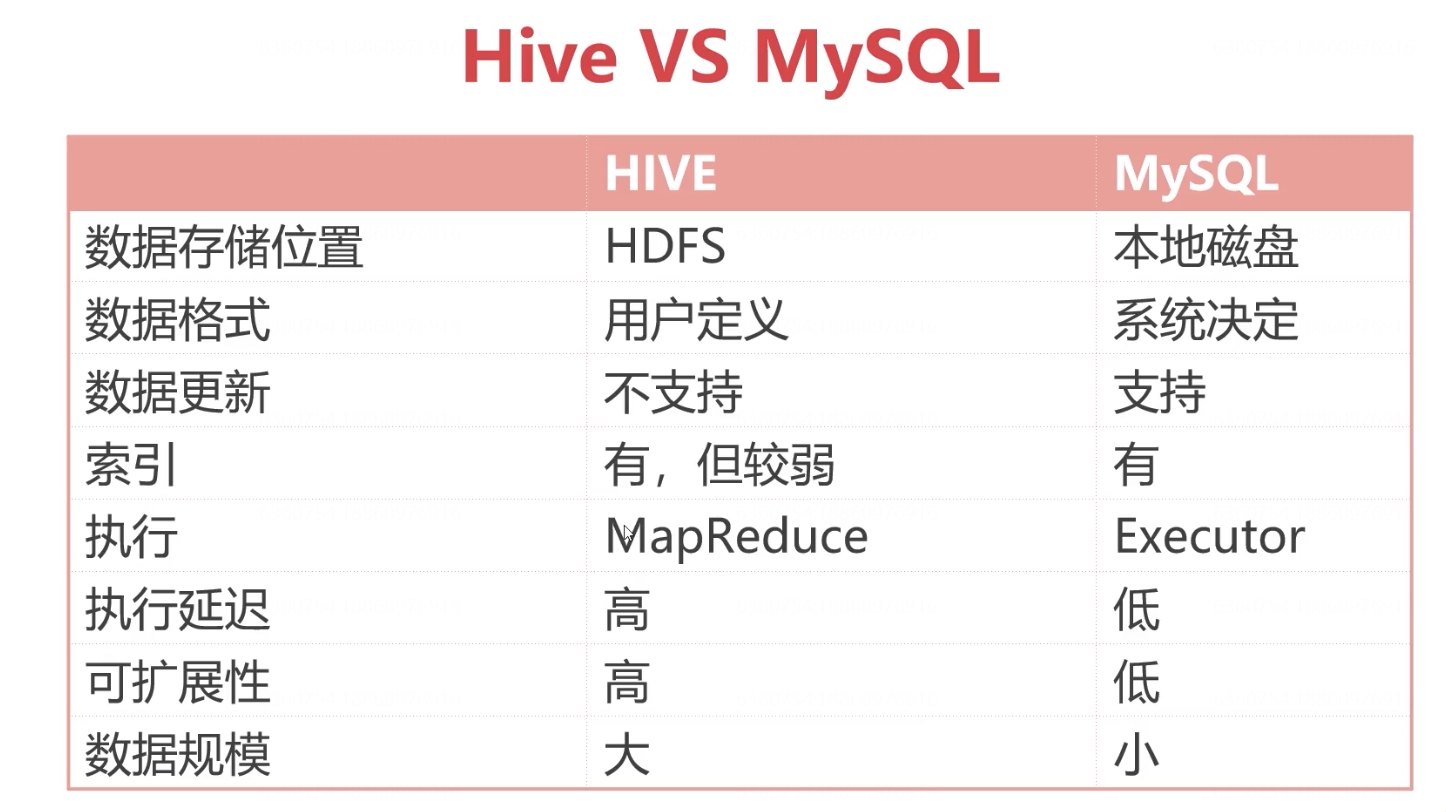


使用hive进行小数据分析如何?
因为Hive是基于HDFS进行文件的存储,所以理论上能够支持的数据存储规模很大,天生适合大数据分析。假如Hive中的数据是小数据,再使用Hive开展分析效率如何呢?
➢ Hive 底层的确是通过 MapReduce 执行引擎来处理数据的
➢ 执行完一个 MapReduce 程序需要的时间不短
➢ 如果是小数据集,使用 hive 进行分析将得不偿失,延迟很高
➢ 如果是大数据集,使用 hive 进行分析,底层 MapReduce 分布式计算,很爽

若有收获,就点个赞吧
0 人点赞
