注意:由于Kafka需要依赖于Zookeeper,所以在这我们需要先把Zookeeper安装部署起来
zookeeper安装部署
zookeeper需要依赖于jdk,只要保证jdk已经正常安装即可。
具体安装步骤如下:
1:下载zookeeper的安装包
进入Zookeeper的官网
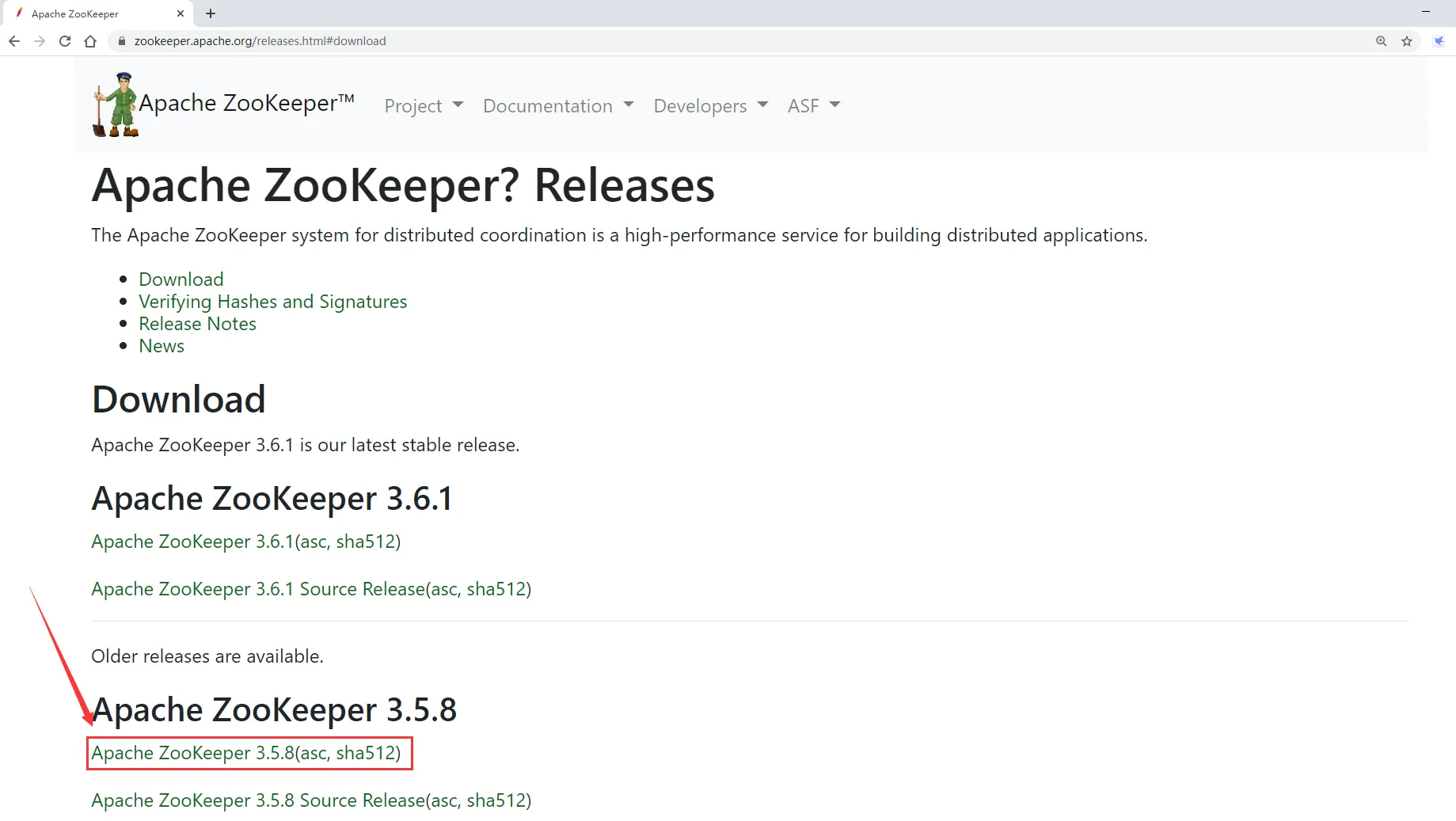
2:把安装包上传到机器的/data/soft目录下
3:解压安装包
cd /data/soft/tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz
4:修改配置文件
首先将zoo_sample.cfg重命名为zoo.cfg
然后修改zoo.cfg中的dataDir参数的值,dataDir指向的目录存储的是zookeeper的核心数据,所以这个目录不能使用tmp目录
cd apache-zookeeper-3.5.8-bin/confmv zoo_sample.cfg zoo.cfgvi zoo.cfgdataDir=/data/soft/apache-zookeeper-3.5.8-bin/data
5:启动zookeeper服务
bin/zkServer.sh start

6:验证 如果jps能看到QuorumPeerMain进程就说明zookeeper启动成功
注意:如果执行jps命令发现没有QuorumPeerMain进程,则需要到/data/soft/apache-zookeeper-3.5.8-bin/logs目录下去查看zookeeper-*.out这个日志文件
也可以通过zkServer.sh 脚本查看当前机器中zookeeper服务的状态
bin/zkServer.sh status
注意:使用zkServer.sh默认会连接本机2181端口的zookeeper服务,默认情况下zookeeper会监听2181端口,这个需要注意一下,因为后面我们在使用zookeeper的时候需要知道它监听的端口是哪个。
最下面显示的Mode信息,表示当前是一个单机独立集群
7:操作zookeeper
首先使用zookeeper的客户端工具连接到zookeeper里面,使用bin目录下面的zlCli.sh脚本,默认会连接本机的zookeeper服务
bin/zkCli.sh
[root@bigdata1 bin]# zkCli.sh
Connecting to localhost:2181
....
....
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]
这样就进入zookeeper的命令行了,在这里面可以操作Zookeeper中的目录结构
zookeeper中的目录结构和Linux文件系统的目录结构类似,zookeeper里面的每一个目录我们称之为节点(ZNode)
正常情况下我们可以把ZNode认为和文件系统中的目录类似,但是有一点需要注意:ZNode节点本身是可以存储数据的。
比较常用的功能:
- 查看根节点下面有什么内容
这里显示根节点下面有一个zookeeper节点
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
- 创建节点
在根节点下面创建一个test节点,在test节点上存储数据hello
[zk: localhost:2181(CONNECTED) 1] create /test hello
Created /test
查看节点中的信息
[zk: localhost:2181(CONNECTED) 2] get /test hello删除节点
这个删除命令可以递归删除,这里面还有一个delete命令,也可以删除节点,但是只能删除空节点,如果节点下面还有子节点,想一次性全部删除建议使用deleteall
[zk: localhost:2181(CONNECTED) 3] deleteall /test
[zk: localhost:2181(CONNECTED) 4] get /test
org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode = NoNode for /test
直接按ctrl+c就可以退出这个操作界面,想优雅一些的话可以输入quit退出
8:停止zookeeper服务
bin/zkServer.sh stop

kafka安装部署
zookeeper集群安装好了以后就可以开始安装kafka了。
注意:在安装kafka之前需要先确保zookeeper集群是启动状态。 kafka还需要依赖于基础环境jdk,需要确保jdk已经安装到位。
1:下载kafka安装包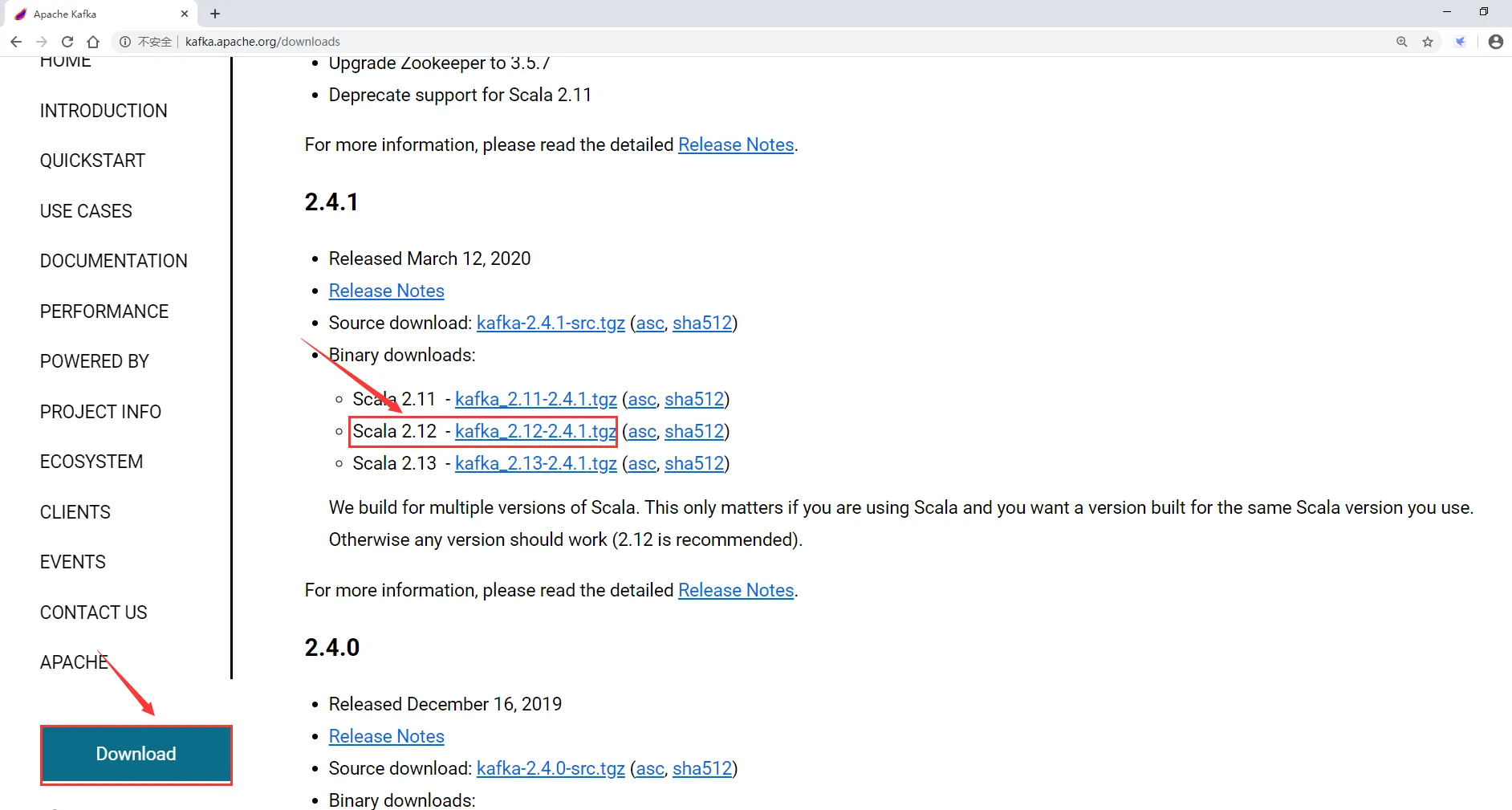
注意:kafka在启动的时候不需要安装scala环境,只有在编译源码的时候才需要,因为运行的时候是在jvm虚拟机上运行的,只需要有jdk环境就可以了
2:把kafka安装包上传到/data/soft目录下
3:解压
tar -zxvf kafka_2.12-2.4.1.tgz
cd kafka_2.12-2.4.1/config/
vi server.properties
4:修改配置文件kafka_2.12-2.4.1/config/server.properties
主要参数:
broker.id:集群节点id编号,单机模式不用修改
listeners:默认监听9092端口
log.dirs:注意:这个目录不是存储日志的,是存储Kafka中核心数据的目录,这个目录默认是指向的tmp目录,所以建议修改一下
zookeeper.connect:kafka依赖的zookeeper(针对单机模式,如果kafka和zookeeper在同一台机器上,并且zookeeper监听的端口就是那个默认的2181端口,则zookeeper.connect这个参数就不需要修改了。)
log.dirs=/data/soft/kafka_2.12-2.4.1/kafka-logs
listeners=PLAINTEXT://0.0.0.0:9092
advertised.listeners=PLAINTEXT://192.168.1.21:9092
5:启动kafka
bin/kafka-server-start.sh -daemon config/server.properties
或者
nohup bin/kafka-server-start.sh config/server.properties &
6:验证 启动成功之后会产生一个kafka进程
#创建测试topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
# 查看 Topic 列表
bin/kafka-topics.sh --list --zookeeper localhost:2181
7:停止kafka
bin/kafka-server-stop.sh

若有收获,就点个赞吧
0 人点赞
