针对Spark Streaming我们主要讲一些基本的使用,因为目前在实时计算领域,Flink的应用场景会更多。
Spark Streaming介绍
Spark Streaming是Spark Core API的一种扩展,它可以用于进行大规模、高吞吐量、容错的实时数据流的处理。
但是注意:这个实时属于近实时,最小可以支持秒级别的实时处理。
SparkStreaming工作原理
Spark Streaming的工作原理是这样的:
接收实时输入数据流,然后将数据拆分成多个batch,比如每收集1秒的数据封装为一个batch,然后将每个batch交给Spark计算引擎进行处理,最后会生产出一个结果数据流,其中的数据,也是由一个一个的batch所组成的。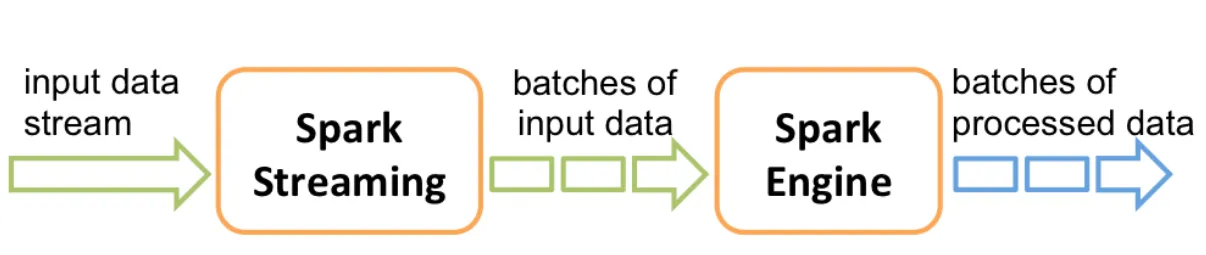
案例:实时WordCount
下面我们来开发一个Spark Streaming 的实时WordCount程序感受一下
创建db_sparkstreaming项目
添加spark streaming的maven依赖
注意:由于目前我们下载的spark的安装包中使用的scala是2.11的,所以在这里要选择对应的scala 2.11版本的依赖。
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.11</artifactId><version>2.4.3</version><scope>provided</scope></dependency>
配置一下项目,创建scala目录,并且在项目中引入2.11版本的scala SDK
开发实时WordCount程序
需求:通过socket模拟产生数据,实时计算数据中单词出现的次数
/**
* 需求:通过socket模拟产生数据,实时计算数据中单词出现的次数
*/
object StreamWordCountScala {
def main(args: Array[String]): Unit = {
//创建SparkConf配置对象
val conf = new SparkConf()
//注意:此处的local[2]表示启动2个进程,一个进程负责读取数据源的数据,一个进程负责处理数据
.setMaster("local[2]")
.setAppName("StreamWordCountScala")
//创建StreamingContext,指定数据处理间隔为5秒
val ssc = new StreamingContext(conf, Seconds(5))
//通过socket获取实时产生的数据
val linesRDD = ssc.socketTextStream("bigdata1", 9002)
//对接收到的数据使用空格进行切割,转换成单个单词
val wordsRDD = linesRDD.flatMap(_.split(" "))
//把每个单词转换成tuple2的形式
val tupRDD = wordsRDD.map((_, 1))
//执行reduceByKey操作
val wordcountRDD = tupRDD.reduceByKey(_ + _)
//将结果数据打印到控制台
wordcountRDD.print()
//启动任务
ssc.start()
//等待任务停止
ssc.awaitTermination()
}
}
开启socket,输入数据
[root@bigdata1 ~]# nc -l 9002
hello you
hello me

案例:Spark Streaming整合Kafka
需求:使用SparkStreaming实时消费Kafka中的数据
需要引入spark-streaming-kafka的依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.3</version>
</dependency>
/**
* Spark 消费Kafka中的数据
*/
object StreamKafkaScala {
def main(args: Array[String]): Unit = {
//创建StreamingContext
val conf = new SparkConf().setMaster("local[2]").setAppName("StreamKafkaScala")
val ssc = new StreamingContext(conf, Seconds(5))
//指定Kafka的配置信息
val kafkaParams = Map[String,Object](
//kafka的broker地址信息
"bootstrap.servers"->"bigdata1:9092",
//key的序列化类型
"key.deserializer"->classOf[StringDeserializer],
//value的序列化类型
"value.deserializer"->classOf[StringDeserializer],
//消费者组id
"group.id"->"con_2",
//消费策略
"auto.offset.reset"->"latest",
//自动提交offset
"enable.auto.commit"->(true: java.lang.Boolean)
)
//指定要读取的topic的名称
val topics = Array("t1")
//获取消费kafka的数据流
val kafkaDStream = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)
)
//处理数据
kafkaDStream.map(record=>(record.key(),record.value()))
//将数据打印到控制台
.print()
//启动任务
ssc.start()
//等待任务停止
ssc.awaitTermination()
}
}
使用kafka的console生产者模拟产生数据
[root@bigdata1 ~]# cd /data/soft/kafka_2.12-2.4.1/
[root@bigdata1 kafka_2.12-2.4.1]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic t1
>hello spark
>
查看结果

若有收获,就点个赞吧
0 人点赞
