
ip:设置静态ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33
hostname:设置主机名
vim /etc/hostname
firewalld:永久关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
ssh免密码登录
在这需要大致讲解一下ssh的含义,ssh 是secure shell,安全的shell,通过ssh可以远程登录到远程linux机器。
我们下面要讲的hadoop集群就会使用到ssh,我们在启动集群的时候只需要在一台机器上启动就行,然后hadoop会通过ssh连到其它机器,把其它机器上面对应的程序也启动起来。
但是现在有一个问题,就是我们使用ssh连接其它机器的时候会发现需要输入密码,所以现在需要实现ssh免密码登录。
那有同学可能有疑问了,你这里说的多台机器需要配置免密码登录,但是我们现在是伪分布集群啊,只有一台机器
注意了,不管是几台机器的集群,启动集群中程序的步骤都是一样的,都是通过ssh远程连接去操作,就算是一台机器,它也会使用ssh自己连自己,我们现在使用ssh自己连自己也是需要密码的。
ssh免密码登录 ssh这种安全/加密的shell,使用的是非对称加密,加密有两种,对称加密和非对称加密。非对称加密的解密过程是不可逆的,所以这种加密方式比较安全。非对称加密会产生秘钥,秘钥分为公钥和私钥,在这里公钥是对外公开的,私钥是自己持有的。
那么ssh通信的这个过程是,第一台机器会把自己的公钥给到第二台机器,当第一台机器要给第二台机器通信的时候,
第一台机器会给第二台机器发送一个随机的字符串,第二台机器会使用公钥对这个字符串加密,
同时第一台机器会使用自己的私钥也对这个字符串进行加密,然后也传给第二台机器
这个时候,第二台机器就有了两份加密的内容,一份是自己使用公钥加密的,一份是第一台机器使用私钥加密传过来的,公钥和私钥是通过一定的算法计算出来的,这个时候,第二台机器就会对比这两份加密之后的内容是否匹配。如果匹配,第二台机器就会认为第一台机器是可信的,就允许登录。如果不相等 就认为是非法的机器。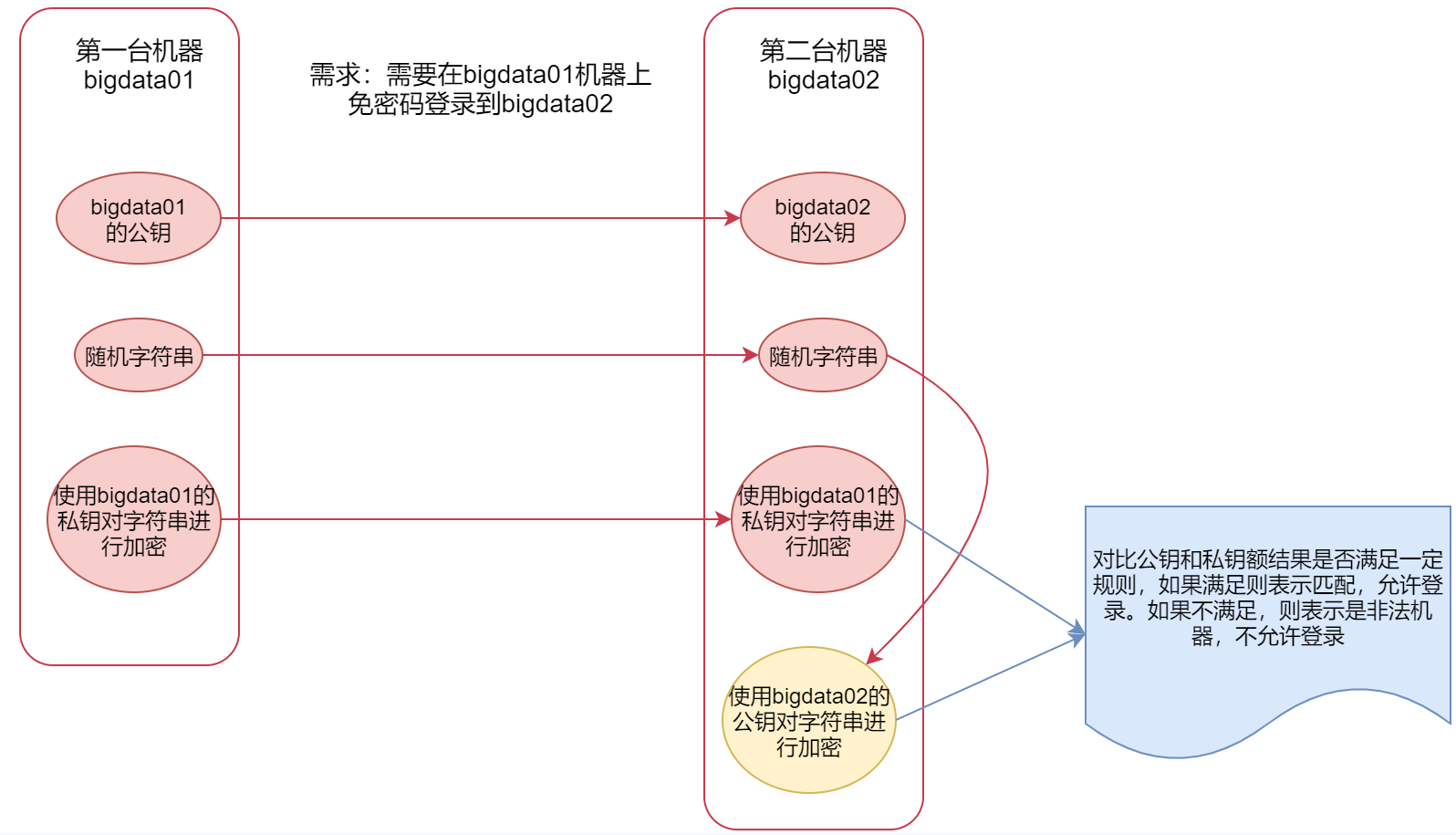
下面就开始正式配置一下ssh免密码登录,由于我们这里要配置自己免密码登录自己,所以第一台机器和第二台机器都是同一台
ssh-keygen -t rsa
执行以后会在~/.ssh目录下生产对应的公钥和秘钥文件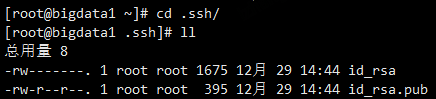
把公钥拷贝到需要免密码登录的机器上面
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
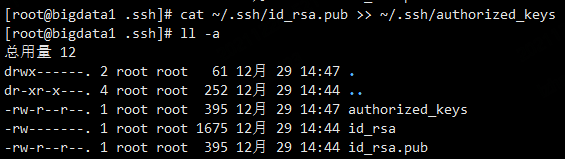
然后就可以通过ssh 免密码登录到bigdata1机器了
[root@bigdata1 .ssh]# ssh bigdata1
Last login: Wed Dec 29 14:47:51 2021 from fe80::36e4:9761:563d:69f7%ens33
[root@bigdata1 ~]#
安装JDK
1、创建/data/soft目录,并上传jdk安装包
mkdir -p /data/soft
2、解压jdk安装包
tar -zxvf jdk-8u202-linux-x64.tar.gz
3、重命名jdk
mv jdk1.8.0_202 jdk1.8
4、配置环境变量 JAVA_HOME
vim /etc/profile
.....
export JAVA_HOME=/data/soft/jdk1.8
export PATH=.:$JAVA_HOME/bin:$PATH
5、验证
source /etc/profile
java -version
伪分布集群安装
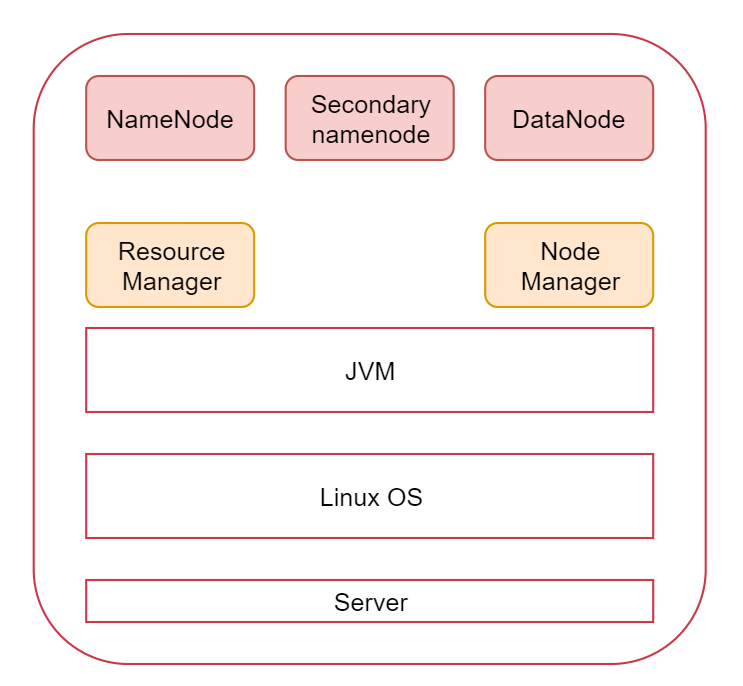
这张图代表是一台Linux机器,也可以称为是一个节点,上面安装的有JDK环境
最上面的是Hadoop集群会启动的进程,其中NameNode、SecondaryNameNode、DataNode是HDFS服务的进程,
ResourceManager、NodeManager是YARN服务的进程,
MapRedcue在这里没有进程,因为它是一个计算框架,等Hadoop集群安装好了以后MapReduce程序可以在上面执行。
Hadoop下载地址:
国内的镜像地址:https://mirrors.tuna.tsinghua.edu.cn/apache
安装Hadoop
1:首先把hadoop的安装包上传到/data/soft目录下
2、解压hadoop安装包
tar -zxvf hadoop-3.2.0.tar.gz
hadoop目录下面有两个重要的目录,一个是bin目录,一个是sbin目录
bin目录,这里面有hdfs,yarn等脚本,这些脚本后期主要是为了操作hadoop集群中的hdfs和yarn
sbin目录,这里面有很多start stop开头的脚本,这些脚本是负责启动 或者停止集群中的组件的。
配置一下环境变量:
vim /etc/profile
.......
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_HOME=/data/soft/hadoop-3.2.0
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
source /etc/profile
3:修改Hadoop相关配置文件
进入配置文件所在目录
cd etc/hadoop/
主要修改下面这几个文件:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
workers
3.1、修改 hadoop-env.sh 文件,增加环境变量信息,添加到hadoop-env.sh 文件末尾即可。
JAVA_HOME:指定java的安装位置
HADOOP_LOG_DIR:hadoop的日志的存放目录
vim hadoop-env.sh
.......
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
3.2、修改 core-site.xml 文件
注意 fs.defaultFS 属性中的主机名需要和你配置的主机名保持一致
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
</configuration>
3.3、修改hdfs-site.xml文件,把hdfs中文件副本的数量设置为1,因为现在伪分布集群只有一个节点
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3.4、修改mapred-site.xml,设置mapreduce使用的资源调度框架
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.5、修改yarn-site.xml,设置yarn上支持运行的服务和环境变量白名单
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
3.6、修改workers,设置集群中从节点的主机名信息,在这里就一台集群,所以就填写bigdata1即可
vim workers
bigdata01
配置文件到这就修改好了,但是还不能直接启动,因为Hadoop中的HDFS是一个分布式的文件系统,文件系统在使用之前是需要先格式化的,就类似我们买一块新的磁盘,在安装系统之前需要先格式化才可以使用。
4:格式化HDFS
cd /data/soft/hadoop-3.2.0
bin/hdfs namenode -format
如果能看到successfully formatted这条信息就说明格式化成功了。
5、修改sbin目录下的start-dfs.sh,stop-dfs.sh这两个脚本文件,在文件前面增加如下内容
vim start-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
vim stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改sbin目录下的start-yarn.sh,stop-yarn.sh这两个脚本文件,在文件前面增加如下内容
vim start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
vim stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
6、启动集群
cd /data/soft/hadoop-3.2.0
sbin/start-all.sh
7、验证集群进程信息
执行jps命令可以查看集群的进程信息,去掉Jps这个进程之外还需要有5个进程才说明集群是正常启动的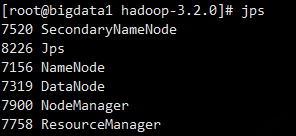
还可以通过webui界面来验证集群服务是否正常
- HDFS webui界面:http://192.168.1.21:9870/
- YARN webui界面:http://192.168.1.21:8088/
7:停止集群
如果修改了集群的配置文件或者是其它原因要停止集群,可以使用下面命令
sbin/stop-all.sh
分布式集群安装
伪分布式集群: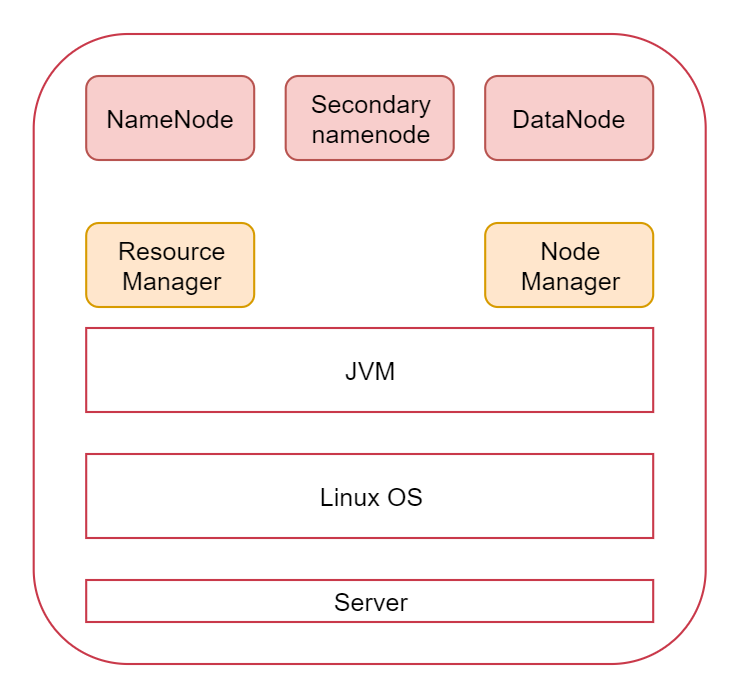
NameNode、SecondaryNameNode、DataNode是HDFS服务的进程,
ResourceManager、NodeManager是YARN服务的进程。
分布式集群: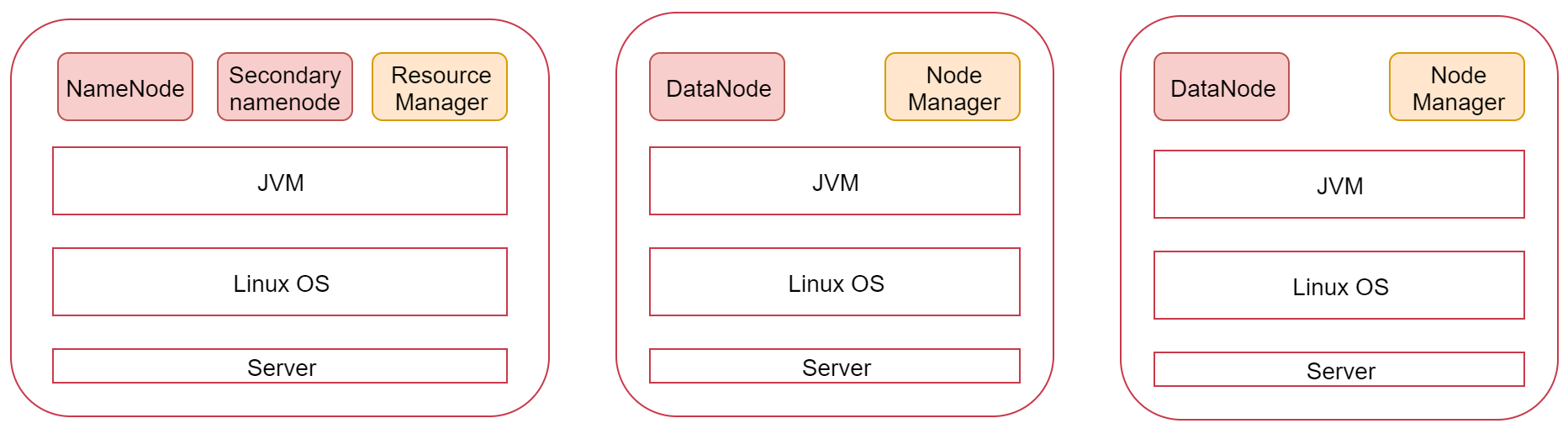
里面表示是三个节点,左边这一个是主节点,右边的两个是从节点,hadoop集群是支持主从架构的。
不同节点上面启动的进程默认是不一样的。
Hadoop的客户端节点
在实际工作中不建议直接连接集群中的节点来操作集群,直接把集群中的节点暴露给普通开发人员是不安全的
建议在业务机器上安装Hadoop,只需要保证业务机器上的Hadoop的配置和集群中的配置保持一致即可,这样就可以在业务机器上操作Hadoop集群了,此机器就称为是Hadoop的客户端节点
Hadoop的客户端节点可能会有多个,理论上是我们想要在哪台机器上操作hadoop集群就可以把这台机器配置为hadoop集群的客户端节点。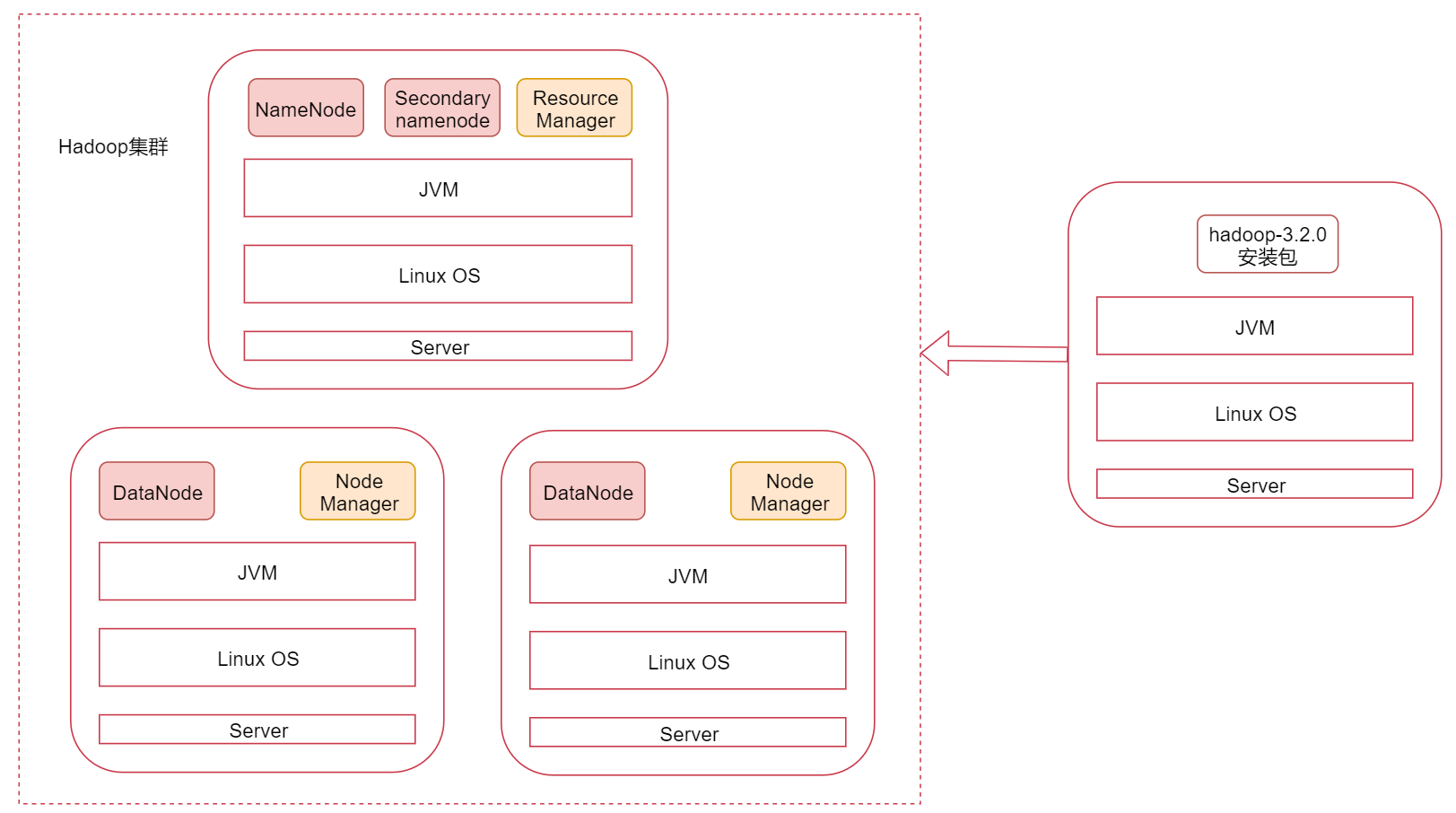

若有收获,就点个赞吧
0 人点赞
