函数的基本操作
和mysql一样的,hive也是一个主要做统计的工具,所以为了满足各种各样的统计需要,他也内置了相当多的函数,我们可以通过show functions;来查看hive中的内置函数
hive (default)> show functions;OKtab_nameabsacosadd_monthsaes_decryptaes_encryptandarrayarray_containsasciiasinassert_trueassert_true_oomatanavg........
desc function FUNC
查看指定函数的描述信息:desc function FUNC;
hive> desc function year;
OK
year(param) - Returns the year component of the date/timestamp/interval
Time taken: 0.524 seconds, Fetched: 1 row(s)
显示函数的扩展内容
hive> desc function extended year;
OK
year(param) - Returns the year component of the date/timestamp/interval
param can be one of:
1. A string in the format of 'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd'.
2. A date value
3. A timestamp value
4. A year-month interval valueExample:
> SELECT year('2009-07-30') FROM src LIMIT 1;
2009
Function class:org.apache.hadoop.hive.ql.udf.UDFYear
Function type:BUILTIN
Time taken: 0.035 seconds, Fetched: 10 row(s)
Hive高级函数应用:
普通的就不说了,mysql中支持的函数这里面大部分都支持,并且hive支持的函数比mysql还要多,在这里我们主要挑几个典型的说一下
分组排序取TopN
主要需要使用到ROW_NUMBER() 和 OVER()函数,row_number和over函数通常搭配在一起使用
row_number()
over()
over可以理解为把数据划分到一个窗口内,里面可以加上partition by,表示按照字段对数据进行分组,还可以加上order by 表示对每个分组内的数据按照某个字段进行排序
我们的需求是这样,有一份学生的考试分数信息,语文、数学、英语这三门,需要计算出班级中单科排名前三名学生的姓名
基础数据是这样的: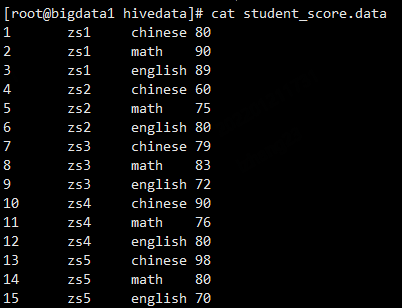
建表
create external table student_score
(
id int,
name string,
sub string,
score int
) row format delimited
fields terminated by '\t'
location '/data/student_score';
加载数据
hdfs dfs -put /data/soft/hivedata/student_score.data /data/student_score
我们先使用row_number对数据编号,看一下是什么样子,row_number不能单独使用,在这里需要加上over
select *, row_number() over () from student_score;
结果如下:在这里相当于给表里面的所有数据编了一个号,从1开始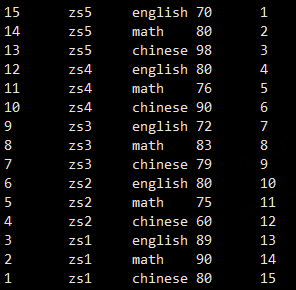
但是我们是希望对这些数据,先分组,再对组内数据进行排序,再编号
需要在over函数内部添加partiton by进行分组,添加order by 进行排序,最终给生成的编号起了换一个别名num
select *, row_number() over (partition by sub order by score desc) as num from student_score;
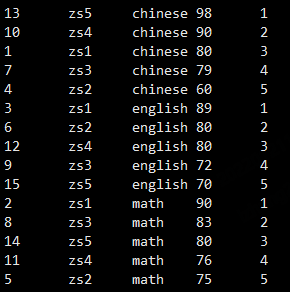
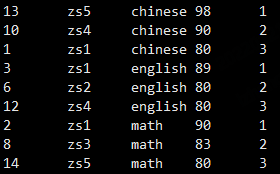
取前三名
select * from (
select *, row_number() over (partition by sub order by score desc) as num
from student_score
) s where s.num<=3;
row_number、rank和dense_rank
前面SQL中的row_number()可以替换为rank()或者dense_rank()
rank()
rank()表示上下两条记录的score相等时,记录的行号是一样的,但下一个score值的行号递增N(N是重复的次数),比如:有两条并列第一,下一个是第三,没有第二
select *, rank() over (partition by sub order by score desc) as num from student_score;
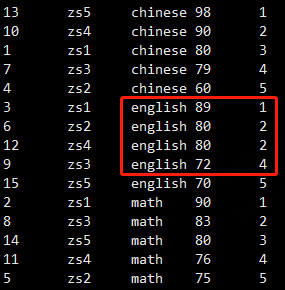
dense_rank()
dense_rank()表示上下两条记录的score相等时,下一个score值的行号递增1,比如:有两条并列第一,下一个是第二
select *, dense_rank() over (partition by sub order by score desc) as num from student_score;
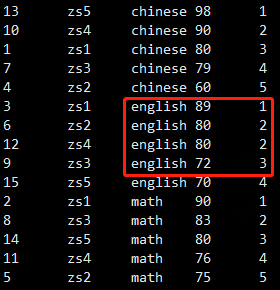
总结一下:
row_number() over() 是正常排序,不处理分数一样的情况
rank() over()是跳跃排序,有两个第一名时接下来就是第三名
dense_rank() over()是连续排序,有两个第一名时仍然跟着第二名
行转列(多行合并展示)
行转列就是把多行数据转为一列数据
针对行转列这种需求主要需要使用到CONCAT_WS()、COLLECT_SET() 、COLLECT_LIST()函数.
concat_ws()
hive> desc function concat_ws;
OK
concat_ws(separator, [string | array(string)]+) - returns the concatenation of the strings separated by the separator.
Time taken: 0.119 seconds, Fetched: 1 row(s)
concat_ws函数可以实现根据指定的分隔符拼接多个字段的值,最终转化为一个带有分隔符的字符串
它可以接收多个参数,第一个参数是分隔符,后面的参数可以是字符串或者字符串数组,最终就是使用分隔符把后面的所有字符串拼接到一块
collect_list()
hive> desc function collect_list;
OK
collect_list(x) - Returns a list of objects with duplicates
Time taken: 0.036 seconds, Fetched: 1 row(s)
这个函数可以返回一个list集合,集合中的元素会重复,一般和group by 结合在一起使用
collect_set()
hive> desc function collect_set;
OK
collect_set(x) - Returns a set of objects with duplicate elements eliminated
Time taken: 0.038 seconds, Fetched: 1 row(s)
这个函数可以返回一个set集合,集合汇中的元素不重复,一般和group by 结合在一起使用
案例
某位学生有很多爱好,数据如下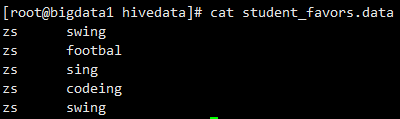
期望的结果:
swing,footbal,sing,codeing,swing
建表
create external table student_favors
(
name string,
favor string
) row format delimited
fields terminated by '\t'
location '/data/student_favors';
上传数据
hdfs dfs -put /data/soft/hivedata/student_favors.data /data/student_favors
查看数据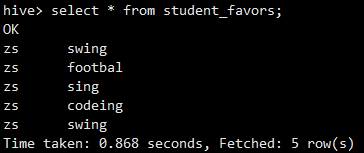
我们想要把数据转换为这种格式:zs swing,footbal,sing,codeing,swing
先对name字段进行分组,把favor转成一个数组
select name, collect_list(favor) as favor_list
from student_favors
group by name;

然后再使用concat_ws把数组中的元素按照指定分隔符转成字符串
这样就实现了多行数据转为一列数据了
执行行转列操作
select name, concat_ws(',', collect_list(favor)) as favor_list
from student_favors
group by name;

我们发现这里面有一些爱好是重复的,如果不希望出现重复的话可以使用COLLECT_SET()
执行sql
select name, concat_ws(',', collect_set(favor)) as favor_list
from student_favors
group by name;

总结:
1、使用collect_list或collect_set行转列 2、使用concat_ws()将集合转为拼接的字符串
列转行
列转行是和刚才的行转列反着来的,列转行可以把一列数据转成多行
主要使用到SPLIT()、EXPLODE()和LATERAL VIEW
split()
hive> desc function SPLIT;
OK
SPLIT(str, regex) - Splits str around occurances that match regex
Time taken: 0.036 seconds, Fetched: 1 row(s)
接受一个字串符和切割规则,就类似于java中的split函数,使用切割规则对字符串中的数据进行切割,最终返回一个array数组
explode()
hive> desc function EXPLODE;
OK
EXPLODE(a) - separates the elements of array a into multiple rows, or the elements of a map into multiple rows and columns
Time taken: 0.037 seconds, Fetched: 1 row(s)
explode函数可以接受array或者map
explode(ARRAY):表示把数组中的每个元素转成一行
explode(MAP) :表示把map中每个key-value对,转成一行,key为一列,value为一列
lateral view
Lateral view 通常和split, explode等函数一起使用。
split可以对表中的某一列进行切割,返回一个数组类型的字段,explode可以对这个数组中的每一个元素转为一行,lateral view可以对这份数据产生一个支持别名的虚拟表
案例
原始数据如下
希望的结果是这样的
zs swing
zs footbal
zs sing
ls codeing
ls swing
建表
create external table student_favors_2
(
name string,
favorlist string
) row format delimited
fields terminated by '\t'
location '/data/student_favors_2';
上传数据
hdfs dfs -put /data/soft/hivedata/student_favors_2.data /data/student_favors_2
查看数据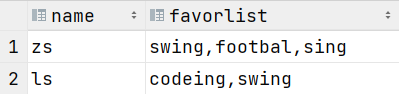
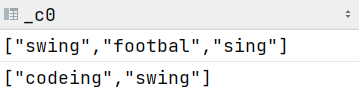
先使用split对favorlist字段进行切割
select split(favorlist,',') from student_favors_2;
再使用explode对数据进行操作
select explode(split(favorlist,',')) from student_favors_2;

其实到这里已经实现了列转行了,但是还需要把name字段拼接上,这时候就需要使用later view了,否则直接查询name字段会报错
laterview相当于把explode返回的数据作为一个虚拟表来使用了,起名字为table1,然后给这个表里面的那一列数据起一个名字叫favor_new,如果有多个字段,可以再后面指定多个。这样在select后面就可以使用这个名字了,有点类似join操作了
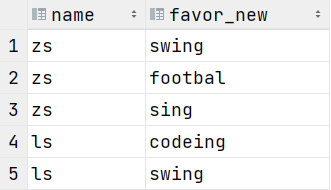
select name, favor_new
from student_favors_2 lateral view explode(split(favorlist, ',')) table1 as favor_new;
总结:
1、先用split拆分成数组 2、再用explode将数组拆分成一行一行
排序相关函数
ORDER BY(全局有序)
Hive中的order by跟传统的sql语言中的order by作用是一样的,会对查询的结果做一次全局排序,使用这个语句的时候生成的reduce任务只有一个
SORT BY(局部有序)
Hive中指定了sort by,如果有多个reduce,那么在每个reducer端都会做排序,也就是说保证了局部有序(每个reducer出来的数据是有序的,但是不能保证所有的数据是全局有序的,除非只有一个reducer)
原始数据:
select id from t2 sort by id;

刚才我们说sort by是局部有序,为什么最终的结果还是全局有序呢?
看里面的日志,现在只有一个reduce任务,所以最终结果还是有序的
动态设置reduce任务数量为2,然后再执行排序的SQL
set mapreduce.job.reduces = 2;
select id from t2 sort by id;

此时会发现数据就没有全局排序了,因为有多个reduce了。
不过针对ORDER BY来说,你动态设置再多的reduce数量都没有用,最后还是只产生1个reduce。
DISTRIBUTE BY(只分区不排序)
ditribute by是控制map的输出到reducer是如何划分的
ditribute by:只会根据指定的key对数据进行分区,但是不会排序。一般情况下可以和sort by 结合使用,先对数据分区,再进行排序
两者结合使用的时候distribute by必须要写在sort by之前
先来看一下单独ditribute by的使用
set mapreduce.job.reduces = 2;
select id from t2 distribute by id;

可以结合sort by实现分区内的排序,默认是升序,可以通过desc来设置倒序
set mapreduce.job.reduces = 2;
select id from t2 distribute by id sort by id;

CLUSTER BY
cluster by的功能就是distribute by和sort by的简写形式
cluster by id 等于 distribute by id sort by id
注意被cluster by指定的列只能是升序,不能指定asc和desc
分组和去重函数
group by(分组,性能高)
distinct(去重,性能低)
案例
https://blog.csdn.net/qq_41455420/article/details/83388955
统计order表中name去重之后的数量
第一种:
select count(distinct name) from order;
使用distinct会将所有的name都shuffle到一个reducer里面,性能较低
第二种:
select count(tmp.name) from (select name from order group by name) tmp;
group by对name分组,会启动多个reduce,性能高
由于没有设置Reduce的个数,Hive会根据数据的大小动态的指定Reduce大小,也可以手动设置set mapred.reduce.tasks=300;

若有收获,就点个赞吧
0 人点赞
