Watermark(解决乱序)
当我们使用 EventTime 处理流数据的时候会遇到数据乱序的问题,流处理从数据产生,到流经是 Source,再到具体的算子,中间是有一个过程和时间的。虽然大部分情况下,传输到算子的数据都是按照数据产生的时间顺序来的,但是也不排除由于网络延迟等原因,导致乱序的产生,特别是使用 Kafka 的时候,多个分区之间的数据无法保证有序。所以在进行 Window 计算的时候,我们又不能无限期地等下去,必须要有一个机制来保证一个特定的时间后,必须触发 Window 去进行计算了,这个特别的机制就是 Watermark。使用 Watermark+EventTime 处理乱序数据。Watermark 可以翻译为水位线。
数据乱序的问题(06分产生了5条数据,实际上06分只收到了3条,而剩下的两条在07分才收到,那此时怎么办呢?在06分时该不该聚合,07分收到的两条06分数据怎么办?) 根据自身的情况,可以设置一个「延迟时间」,等延迟的时间到了,我再聚合统一聚合。
比如说:现在我知道数据有可能会延迟一分钟,那我将水位线waterMarks设置延迟一分钟。 解读:因为设置了「事件发生的时间」Event Time,所以Flink可以检测到每一条记录发生的时间,而设置了水位线waterMarks设置延迟一分钟,等到Flink发现07分:59秒的数据来到了Flink,那就确信06分的数据都来了(因为设置了1分钟延迟),此时才聚合06分的窗口数据。
watermark = 进入 Flink 窗口的最大的事件时间(maxEventTime)- 指定的延迟时间(t)
有序数据流的Watermark
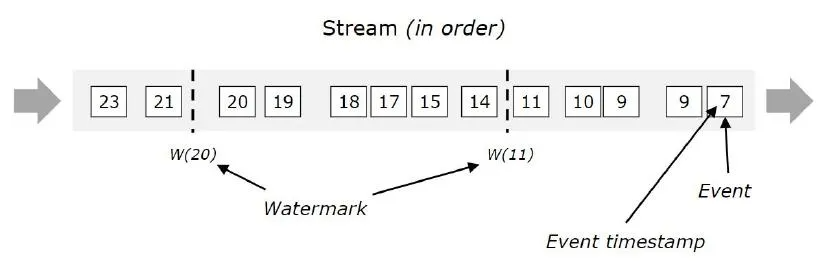
in order :有序的数据流,从左往右方块代表的是具体的数据,方块里面的数字代表的是数据产生的时间
w(11):表示 watermark 的值为 11,此时表示 11 之前的数据都到了,可以进行计算了
w(20):表示 watermark 的值为 20,此时表示 20 之前的数据都到了,可以进行计算了。
无序数据流的Watermark
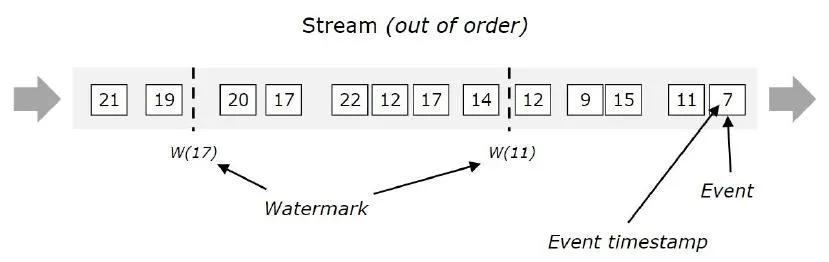
out of order:无序的数据流
w(11):此时表示 11 之前的数据都到了,可以对 11 之前的数据进行计算了,大于 11 的数据暂时不计算
w(17):此时表示 17 之前的数据都到了,可以对 17 之前的数据进行计算了,大于 17 的数据暂时不计算
多并行度数据流的Watermark
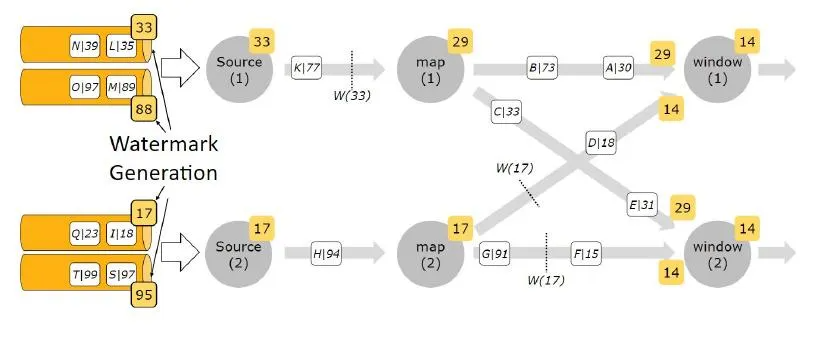
注意:在多并行度的情况下,Watermark 会有一个对齐机制,这个对齐机制会取所有 Channel中最小的 Watermark,图中的 14 和 29 这两个 Watermark,最终取值为 14。这样才不会漏掉数据。
Watermark 的生成方式
通常情况下,在接收到 Source 的数据后,应该立刻生成 Watermark,但是也可以在使用 Map或者 Filter 操作之后,再生成 Watermark。
Watermark 的生成方式有两种
- With Periodic Watermarks 周期性触发 Watermark 的生成和发送,每隔N秒自动向流里面注入一个Watermark,时间间隔由ExecutionConfig.setAutoWatermarkInterval 决定,现在新版本的 Flink 默认是 200ms。之前默认是 100ms可以定义一个最大允许乱序的时间,这种比较常用。
- With Punctuated Watermarks 基于某些事件触发 Watermark 的生成和发送。
基于事件向流里面注入一个 Watermark,每一个元素都有机会判断是否生成一个 Watermark.案例:乱序数据处理
需求分析:
通过 socket 模拟产生数据,数据的格式为:0001,1790820682000 其中 1790820682000 是数据产生的时间,也就是 EventTime。
然后使用 map 函数对数据进行处理,把数据转换为 tuple2 的形式。接着再调用assignTimestampsAndWatermarks方法抽取 timestamp 并生成 Watermark。
接着再调用 Window 打印信息来验证 Window 被触发的时机最后验证乱序数据的处理方式。
开发watermark相关代码
/*** Watermark+EventTime解决数据乱序问题* 需求:通过 socket 模拟产生数据,数据的格式为:0001,1790820682000 其中 1790820682000 是数据产生的时间,也就是 EventTime。*/object WatermarkOp {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment//设置使用数据产生的时间:EventTimeenv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)//设置全局并行度为1env.setParallelism(1)//设置自动周期性的产生watermark,默认值为200毫秒env.getConfig.setAutoWatermarkInterval(200)val text = env.socketTextStream("bigdata1", 9002)//将数据转换为tuple2的形式//第一列表示具体的数据,第二列表示是数据产生的时间戳val tupStream = text.map(line => {val arr = line.split(",")(arr(0), arr(1).toLong)})//分配(提取)时间戳和watermarkval waterMarkStream = tupStream.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10)) //最大允许的数据乱序时间 10s.withTimestampAssigner(new SerializableTimestampAssigner[Tuple2[String, Long]] {val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")var currentMaxTimstamp = 0L//从数据流中抽取时间戳作为EventTimeoverride def extractTimestamp(element: (String, Long), recordTimestamp: Long): Long = {val timestamp = element._2currentMaxTimstamp = Math.max(timestamp, currentMaxTimstamp)//计算当前watermark,为了打印出来方便观察数据,没有别的作用,watermark=currentMaxTimstamp-OutOfOrdernessval currentWatermark = currentMaxTimstamp - 10000L//此print语句仅仅是为了在学习阶段观察数据的变化println("key:" + element._1 + "," + "eventtime:[" + element._2 + "|" + sdf.format(element._2) + "],currentMaxTimstamp:[" + currentWatermark + "|" + sdf.format(currentMaxTimstamp) + "],watermark:[" + currentWatermark + "|" + sdf.format(currentWatermark) + "]")element._2}}))waterMarkStream.keyBy(0)//按照消息的EventTime分配窗口,和调用TimeWindow效果一样.window(TumblingEventTimeWindows.of(Time.seconds(3)))//使用全量聚合的方式处理window中的数据.apply(new WindowFunction[Tuple2[String, Long], String, Tuple, TimeWindow] {override def apply(key: Tuple, window: TimeWindow, input: Iterable[(String, Long)], out: Collector[String]): Unit = {val keyStr = key.toString//将window中的数据保存到arrBuff中val arrBuff = ArrayBuffer[Long]()input.foreach(tup => {arrBuff.append(tup._2)})//将arrBuff转换为arrval arr = arrBuff.toArray//对arr中的数据进行排序Sorting.quickSort(arr)val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")//将目前window内排序后的数据,以及window的开始时间和window的结束时间打印出来,便于观察val result = keyStr + "," + arr.length + "," + sdf.format(arr.head) + "," + sdf.format(arr.last) + "," + sdf.format(window.getStart) + "," + sdf.format(window.getEnd)out.collect(result)}}).print()env.execute("WatermarkOpScala")}}

若有收获,就点个赞吧
0 人点赞
