Sqoop的介绍
Sqoop中有两大功能,数据导入和数据导出。
数据导入是指把关系型数据库中的数据导入HDFS中。
数据导出是指把HDFS中的数据导出到关系型数据库中。
安装Sqoop
“Sqoop目前有两大版本,Sqoop1和Sqoop2,这两个版本都是一直在维护者的,所以使用哪个版本都可以。
这两个版本我都用过,还是感觉Sqoop1用起来比较方便,使用Sqoop1的时候可以将具体的命令全部都写到脚本中,这样看起来是比较清晰的,但是有一个弊端,就是在操作MySQL的时候,MySQL数据库的用户名和密码会明文暴露在这些脚本中,不过一般也没有什么问题,因为在访问生产环境下的MySQL的时候,是需要申请权限的,就算你知道了MySQL的用户名和密码,但是你压根无法访问MySQL的那台机器,所以这样也是安全的,只要运维那边权限控制到位了就没问题。
sqoop2中引入了sqoop server(服务),集中管理connector(连接),而sqoop1只是客户端工具。
相对来说,Sqoop1更加简洁,轻量级。
Sqoop1的最后更新时间是2018年
Sqoop2的最后更新时间是2016年
Sqoop2我之前在使用的时候发现里面bug还是比较多的,相对来说Sqoop1更加稳定一些。
所以在这我们采用Sqoop1。”
想要使用Sqoop1,先去官网下载安装包
https://archive.apache.org/dist/sqoop/1.4.7/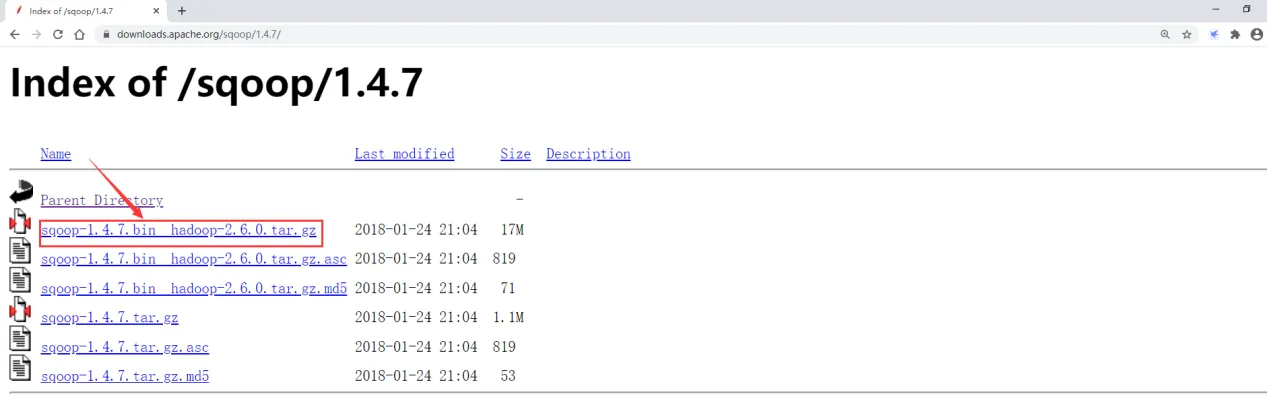
最终下载的sqoop1.4.7的安装是这个 sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz 这个安装包表示里面包含了hadoop-2.6.0的依赖,我们目前使用的是hadoop3.2.0,不过是可以兼容的,这样就没有必要重新编辑sqoop了。 Sqoop的安装部署很简单,因为Sqoop1只是一个客户端工具,直接解压,修改一下配置文件就行,不需要启动任何进程
Sqoop在执行的时候底层会生成MapReduce任务,所以Sqoop需要部署在Hadoop客户端机器上,因为它是依赖于Hadoop的。
1、把Sqoop的安装包上传到/data/soft目录下
2、解压
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
3、修改配置文件的名称
cd sqoop-1.4.7.bin__hadoop-2.6.0/confmv sqoop-env-template.sh sqoop-env.sh
4、配置SQOOP_HOME环境变量
vi /etc/profileexport SQOOP_HOME=/data/soft/sqoop-1.4.7.bin__hadoop-2.6.0export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$SPARK_HOME/bin:$SQOOP_HOME/bin:$PATHsource /etc/profile
5、将MySQL 8的驱动包mysql-connector-java-8.0.16.jar,上传到/data/soft/sqoop-1.4.7.bin__hadoop-2.6.0/lib目录下
使用hadoop 3.2.0版本的时候,将commons-lang-2.6.jar上传到/data/soft/sqoop-1.4.7.bin__hadoop-2.6.0/lib目录下
6、开放MySQL远程访问权限【开放权限以后集群中的机器才可以连接windows上的MySQL服务,否则只能在windows本地访问】
C:\Users\Administrator> mysql -uroot -prootmysql> USE mysql;##CREATE USER 'root'@'%' IDENTIFIED BY '你的密码';mysql> GRANT ALL ON *.* TO 'root'@'%';mysql> ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '你的密码';mysql> FLUSH PRIVILEGES;
导入(从MySQL导入HDFS)
Sqoop通用参数:
选项 含义说明
--connect <jdbc-uri> 指定JDBC连接字符串
--connection-manager <class-name> 指定要使用的连接管理器类
--driver <class-name> 指定要使用的JDBC驱动类
--hadoop-mapred-home <dir> 指定$HADOOP_MAPRED_HOME路径
--help 万能帮助
--password-file 设置用于存放认证的密码信息文件的路径
-P 从控制台读取输入的密码
--password <password> 设置认证密码
--username <username> 设置认证用户名
--verbose 打印详细的运行信息
--connection-param-file <filename> 可选,指定存储数据库连接参数的属性文件
导入功能相关参数
选项 含义说明
--append 将数据追加到HDFS上一个已存在的数据集上
--as-avrodatafile 将数据导入到Avro数据文件
--as-sequencefile 将数据导入到SequenceFile
--as-textfile 将数据导入到普通文本文件(默认)
--boundary-query <statement> 边界查询,用于创建分片(InputSplit)
--columns <col,col,col…> 从表中导出指定的一组列的数据
--delete-target-dir 如果指定目录存在,则先删除掉
--direct 使用直接导入模式(优化导入速度)
--direct-split-size <n> 分割输入stream的字节大小(在直接导入模式下)
--fetch-size <n> 从数据库中批量读取记录数
--inline-lob-limit <n> 设置内联的LOB对象的大小
-m,--num-mappers <n> 使用n个map任务并行导入数据
-e,--query <statement> 导入的查询语句
--split-by <column-name> 指定按照哪个列去分割数据
--table <table-name> 导入的源表表名
--target-dir <dir> 导入HDFS的目标路径
--warehouse-dir <dir> HDFS存放表的根路径
--where <where clause> 指定导出时所使用的查询条件
-z,--compress 启用压缩
--compression-codec <c> 指定Hadoop的codec方式(默认gzip)
--null-string <null-string> 如果指定列为字符串类型,使用指定字符串替换值为null的该类列的值
--null-non-string <null-string> 如果指定列为非字符串类型,使用指定字符串替换值为null的该类列的值
全表导入
直接把一个表中的所有数据全部导入到HDFS里面
先在MySQL中创建一个数据库和表
create database sqoop_test;
use sqoop_test;
create table user(id int(10),name varchar(64));
insert into user (id,name) values (1,'jack');
insert into user (id,name) values (2,'tom');
insert into user (id,name) values (3,'mike');
使用Sqoop将sqoop_test.user表中的数据导入到HDFS中
sqoop import \
--connect jdbc:mysql://192.168.1.4:3306/sqoop_test?serverTimezone=UTC \
--username root \
--password root \
--table user \
--target-dir /sqoop-out1 \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
查看HDFS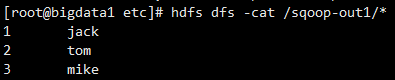
注意:如果表中没有主键则会报错(因为mapper数默认是4,需要分4个Task,根据主键来分。但是表又没有主键,MapReduce不知道以哪个字段为准来分Task。)
解决办法有三种:
- 可以选择在表中设置主键,默认根据主键字段分task
- 使用–num-mappers 1 ,表示将map任务个数设置为1,sqoop默认是4
- 使用–split-by ,后面跟上一个数字类型的列,会根据这个列分task
查询导入
使用sql语句查询表中满足条件的数据导入到HDFS里面注意:在使用–query指定sql的时候,必须包含$CONDITIONS

sqoop import \
--connect jdbc:mysql://192.168.1.4:3306/sqoop_test?serverTimezone=UTC \
--username root \
--password root \
--query 'select id,name from user where id >1 and $CONDITIONS' \
--target-dir /sqoop-out2 \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
注意:–query和–table不能同时指定

问题:null值如何处理?
默认情况下MySQL中的null值(无论字段类型是字符串类型还是数字类型),使用Sqoop导入到HDFS文件中之后,都会显示为字符串null。
针对字符串null类型:通过--null-string '*'来指定,单引号中指定一个字符即可,这个字符不能是—,因为—是保留关键字
针对非字符串的null类型:通过--null-non-string '*' 来指定,单引号中指定一个字符即可,这个字符不能是—,因为—是保留关键字
这两个参数可以同时设置,这样在导入数据的时候,针对空值字段,会替换为指定的内容。
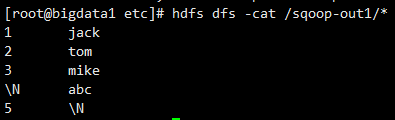
例如:可以使用\N,因为我们把数据导入到HDFS之后,最终是希望在Hive中查询的,Hive中针对NULL值在底层是使用\N存储的。
当然了,我们也可以选择给NULL值指定一个默认的其它字符。
1、测试默认
sqoop import \
--connect jdbc:mysql://192.168.1.4:3306/sqoop_test?serverTimezone=UTC \
--username root \
--password root \
--table user \
--target-dir /sqoop-out1 \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
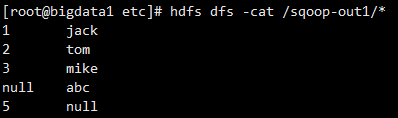
2、指定null值处理
sqoop import \
--connect jdbc:mysql://192.168.1.4:3306/sqoop_test?serverTimezone=UTC \
--username root \
--password root \
--table user \
--target-dir /sqoop-out1 \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t' \
--null-string '\\N' \
--null-non-string '\\N'
导出(从HDFS导出MySQL)
导出功能相关参数
选项 含义说明
--validate <class-name> 启用数据副本验证功能,仅支持单表拷贝,可以指定验证使用的实现类
--validation-threshold <class-name> 指定验证门限所使用的类
--direct 使用直接导出模式(优化速度)
--export-dir <dir> 导出过程中HDFS源路径
--m,--num-mappers <n> 使用n个map任务并行导出
--table <table-name> 导出的目的表名称
--call <stored-proc-name> 导出数据调用的指定存储过程名
--update-key <col-name> 更新参考的列名称,多个列名使用逗号分隔
--update-mode <mode> 指定更新策略,包括:updateonly(默认)、allowinsert
--input-null-string <null-string> 使用指定字符串,替换字符串类型值为null的列
--input-null-non-string <null-string> 使用指定字符串,替换非字符串类型值为null的列
--staging-table <staging-table-name> 在数据导出到数据库之前,数据临时存放的表名称
--clear-staging-table 清除工作区中临时存放的数据
--batch 使用批量模式导出
数据导出
将刚才导入到HDFS中的数据sqoop-out2再导出来
sqoop export \
--connect jdbc:mysql://192.168.1.4:3306/sqoop_test?serverTimezone=UTC \
--username root \
--password root \
--table user2 \
--export-dir /sqoop-out2 \
--input-fields-terminated-by '\t'
注意:这里--table指定的表名需要提前创建,sqoop不会自动创建此表。
create table user2(id int(10),name varchar(64));
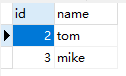
存在则更新,不存在则新增
在导出的时候可以实现插入和更新功能
如果存在就更新,不存在就插入
注意:此时表中必须有一个主键字段
将user2中的id字段设置为主键,
修改user2中id为2那条数据的name字段的值为imooc,删除id为3的那条数据
修改之后的user2表中的数据如下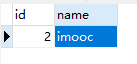
执行sqoop语句
sqoop export \
--connect jdbc:mysql://192.168.1.4:3306/sqoop_test?serverTimezone=UTC \
--username root \
--password root \
--table user2 \
--export-dir /sqoop-out2 \
--input-fields-terminated-by '\t' \
--update-key id \
--update-mode allowinsert
再验证一下结果,会发现针对已有的数据更新,没有的数据新增。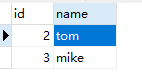
这就是Sqoop的导入和导出功能。
后期我们在使用Sqoop的时候,建议将Sqoop的命名写到shell脚本中,否则使用起来不方便。
vi sqoop-ex-user.sh
#!/bin/bash
sqoop export \
--connect jdbc:mysql://192.168.1.4:3306/sqoop_test?serverTimezone=UTC \
--username root \
--password root \
--table user2 \
--export-dir /sqoop-out2 \
--input-fields-terminated-by '\t'

若有收获,就点个赞吧
0 人点赞
