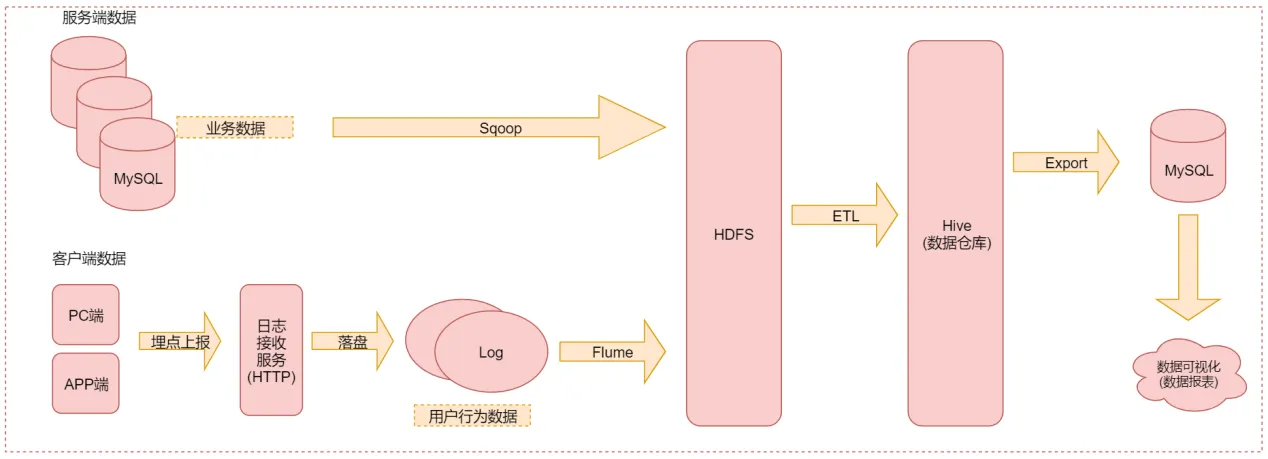
数据生成
【客户端数据】用户行为数据
首先我们模拟生成用户行为数据,也就是客户端数据,主要包含用户打开APP、点击、浏览等行为数据
用户行为数据:通过埋点上报,后端日志服务器(http)负责接收数据
埋点上报数据基本格式:
{"uid":1001, //用户ID"xaid":"ab25617-c38910-m2991", //手机设备ID"platform":2, //设备类型, 1:Android-APP, 2:IOS-APP, 3:PC"ver":"3.5.10", //大版本号"vercode":"35100083", //子版本号"net":1, //网络类型, 0:未知, 1:WIFI, 2:2G , 3:3G, 4:4G, 5:5G"brand":"iPhone", //手机品牌"model":"iPhone8", //机型"display":"1334x750", //分辨率"osver":"ios13.5", //操作系统版本号"data":[ //用户行为数据{"act":1,"acttime":1592486549819,"ad_status":1,"loading_time":100},{"act":2,"acttime":1592486549819,"goods_id":"2881992"}]}
json串中的data是一个json数组,它里面包含了多种用户行为数据。
json串中的其它字段属于公共字段
注意:考虑到性能,一般数据上报都是批量上报,假设间隔10秒上报一次,这种数据延迟是可以接受的
所以在每次上报的时候,公共字段只需要报一份就行,把不同的用户行为相关的业务字段放到data数组中,这样可以避免上报大量的重复数据,影响数据上报性能,我们只需要在后期解析的时候,把公共字段和data数组总的每一条业务字段进行拼装,就可以获取到每一个用户行为的所有字段信息。
act代表具体的用户行为,在这列出来几种
act=1:打开APP
属性 含义act 用户行为类型acttime 数据产生时间(时间戳)ad_status 开屏广告展示状态, 1:成功 2:失败loading_time 开屏广告加载耗时(单位毫秒)
act=2:点击商品
属性 含义
act 用户行为类型
acttime 数据产生时间(时间戳)
goods_id 商品ID
location 商品展示顺序:在列表页中排第几位,从0开始
act=3:商品详情页
属性 含义
act 用户行为类型
acttime 数据产生时间(时间戳)
goods_id 商品ID
stay_time 页面停留时长(单位毫秒)
loading_time 页面加载耗时(单位毫秒)
act=4:商品列表页
属性 含义
act 用户行为类型
acttime 数据产生时间(时间戳)
loading_time 页面加载耗时(单位毫秒)
loading_type 加载类型:1:读缓存 2:请求接口
goods_num 列表页加载商品数量
act=5:app崩溃数据
属性 含义
act 用户行为类型
acttime 数据产生时间(时间戳)
生成数据的代码在这里:
2:部署日志采集服务,模拟埋点上报数据的流程,代码在db_data_warehouse中的data_collect这个子项目中,将这个子项目打成jar包,部署到服务器中,并且启动此HTTP服务。
对data_collect执行打包操作,在cmd命令下执行mvn clean package -DskipTests
在/data/soft/目录下创建data_collect目录
mkdir data_collect
上传data_collect-1.0-SNAPSHOT.jar到/data/soft/data_collect目录
为了后面使用方便,我在这里面写一个启动脚本
vi start.sh
nohup java -jar data_collect-1.0-SNAPSHOT.jar >> nohup.out &
sh start.sh
确认是否成功启动
下面就可以执行GenerateUserActionData生成用户行为数据了。
传到data_collect接口的数据格式:
{
"uid":1001, //用户ID
"xaid":"ab25617-c38910-m2991", //手机设备ID
"platform":2, //设备类型, 1:Android-APP, 2:IOS-APP, 3:PC
"ver":"3.5.10", //大版本号
"vercode":"35100083", //子版本号
"net":1, //网络类型, 0:未知, 1:WIFI, 2:2G , 3:3G, 4:4G, 5:5G
"brand":"iPhone", //手机品牌
"model":"iPhone8", //机型
"display":"1334x750", //分辨率
"osver":"ios13.5", //操作系统版本号
"data":[ //用户行为数据
{"act":1,"acttime":1592486549819,"ad_status":1,"loading_time":100},
{"act":2,"acttime":1592486549819,"goods_id":"2881992"}
]
}
首先解析data属性的值,里面包含了多个用户的行为数据 并且每个用户的行为数据中还包含了多种具体的行为操作,因为客户端在上报数据的时候不是产生一条就上报一条,这样效率太低了,一般都会批量上报,所以内层json串中还有一个data参数,data参数的值是一个JSONArray,里面包含一个用户的多种行为数据 然后通过接口模拟上报数据,data_collect接口接收到数据之后,会对数据进行拆分,将包含了多个用户行为的数据拆开,打平,输出多条日志数据
data_collect解析后的数据格式:
{
"ver": "3.4.8",
"display": "1280x768",
"goods_id": "100086",
"osver": "7.1.1",
"platform": 3,
"uid": "1000030",
"act": 2,
"model": "huawei21",
"acttime": 1593511199232,
"location": 6,
"net": 4,
"xaid": "ab25617-c38910-m30",
"brand": "huawei",
"vercode": "35100044"
}
日志保存在/data/log目录下user_action.%d{yyyy-MM-dd}.log.zip
【服务端数据】商品订单相关数据
接下来需要生成商品订单相关数据,这些数据都是存储在mysql中的
相关表名为:
订单表:user_order
商品信息表:goods_info
订单商品表:order_item
商品类目码表:category_code
订单收货表:order_delivery
支付流水表:payment_flow
用户收货地址表:user_addr
用户信息表:user
用户扩展表:user_extend
表结构如下: 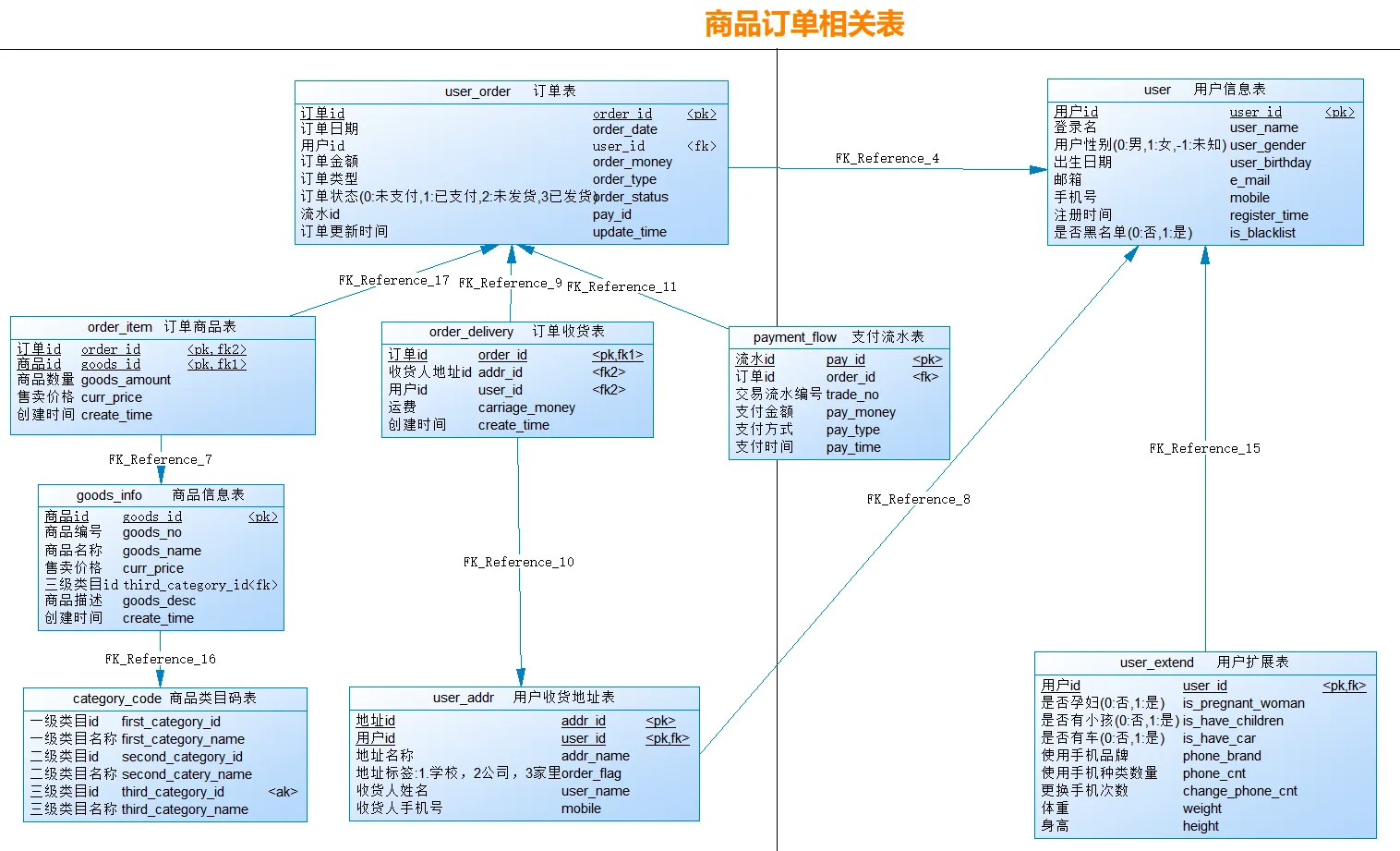
建表
使用这个脚本进行初始化:init_mysql_tables.sql
接下来需要向表中初始化数据。
使用generate_data项目中的这个类:GenerateGoodsOrderData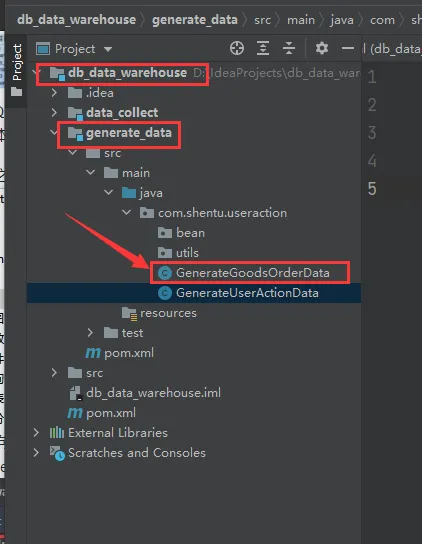
在具体执行之前需要先修改GenerateGoodsOrderData中的几个参数值
(1)code的值
(2)date的值
(3)user_num的值
(4)order_num的值
(5)修改项目的resources目录下的db.properties文件
className=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/mall?serverTimezone=UTC
user=root
password=root
下面就可以执行GenerateGoodsOrderData向MySQL中初始化数据了。
采集数据
采集用户行为数据(Flume)
配置Flume的Agent
数据接收到以后,需要使用flume采集数据,按照act值的不同,将数据分目录存储
flume Agent配置内容如下:useraction-to-hdfs.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /data/log/user_action.log
# 配置拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = regex_extractor
a1.sources.r1.interceptors.i1.regex = "act":(\\d)
a1.sources.r1.interceptors.i1.serializers = s1
#匹配到"act":"...",会往event的header中添加<"act","...">的值
a1.sources.r1.interceptors.i1.serializers.s1.name = act
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://bigdata1:9000/data/ods/user_action/%Y%m%d/%{act}
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#增加文件前缀和后缀
a1.sinks.k1.hdfs.filePrefix = data
a1.sinks.k1.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
将/data/soft目录下的user_action.log删掉,等下面将Flume的Agent进程启动起来之后再重新上报用户行为数据。
rm -rf user_action.log
重启data_collect程序,否则user_action.log被删除之后不会再产生新文件
[root@bigdata1 data_collect]# jps -l
68081 org.apache.spark.deploy.history.HistoryServer
21537 org.apache.hadoop.yarn.server.nodemanager.NodeManager
113970 data_collect-1.0-SNAPSHOT.jar
22950 org.apache.hadoop.util.RunJar
20919 org.apache.hadoop.hdfs.server.datanode.DataNode
21383 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
2632 org.apache.hadoop.mapreduce.v2.hs.JobHistoryServer
20746 org.apache.hadoop.hdfs.server.namenode.NameNode
21130 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
114059 sun.tools.jps.Jps
[root@bigdata1 data_collect]# kill 113970
[root@bigdata1 data_collect]# sh start.sh
将useraction-to-hdfs.conf配置文件配置到Flume中
首先到Flume中复制一个conf目录,修改log4j中的日志文件名称
cp -r conf conf-useraction-to-hdfs
cd conf-useraction-to-hdfs/
vi log4j.properties
.....
flume.log.file=flume-useraction-to-hdfs.log
.....
将useraction-to-hdfs.conf上传到conf-useraction-to-hdfs目录下
启动Agent
bin/flume-ng agent --name a1 --conf conf-useraction-to-hdfs --conf-file conf-useraction-to-hdfs/useraction-to-hdfs.conf
#后台方式运行
nohup flume-ng agent --name a1 --conf conf-useraction-to-hdfs --conf-file conf-useraction-to-hdfs/useraction-to-hdfs.conf &
开始采集数据
重新执行GenerateUserActionData模拟上报数据
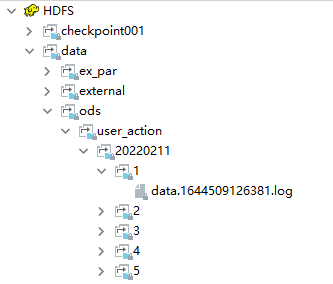
此时数据最终会被Flume采集到HDFS上面,到HDFS中查看数据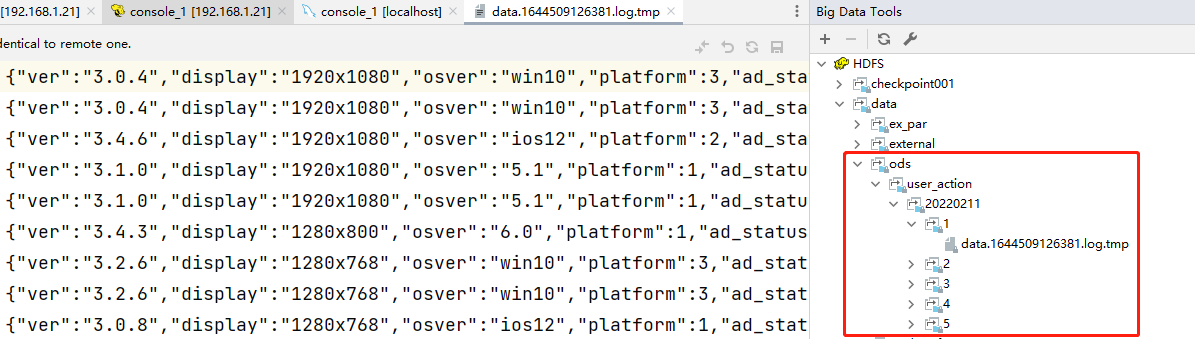
flume还在运行,所以文件结尾是.tmp
采集商品订单相关数据(Sqoop)
下面我们需要将商品订单数据采集到HDFS里面,咱们前面分析过,在这里针对关系型数据库数据的采集我们使用Sqoop
使用sqoop的导入功能,将MySQL中的数据导入到HDFS上面
采集策略
全量采集
针对用户表、商品表等这些实体表,数据量不是特别大,通常可以每天做全量采集,就是每天保存一份完整的数据
如果针对一些维度表,例如:存储城市信息的表,这种表里面的数据一般是几十年都不变的,针对这种表在采集的时候只需要做一次全量采集就可以了,不需要每天都做。
如果表中的数据可能会变,那就只能每天做一次全量采集了。
增量采集
针对订单表、订单商品表,流水表,这些表中的数据是比较多的,如果使用全量的方式,会造成大量的数据冗余,浪费磁盘空间。
所以这种表,一般使用增量的方式,每日采集新增的数据。
在这注意一点:针对订单表,如果单纯的按照订单产生时间增量采集数据,是有问题的,因为用户可能今天下单,明天才支付,但是Hive是不支持数据更新的,这样虽然MySQL中订单的状态改变了,但是Hive中订单的状态还是之前的状态。
想要比较好的解决这个问题,最好是使用拉链表的形式,这个我们在最后的时候会详细分析拉链表的实现
在这里针对订单表,我们暂时使用普通增量的方式进行数据采集,大家先带着这个问题,后面我们再详细分析拉链表。
针对目前已有的9张表,汇总一下是这样的:
| 表名 | 说明 | 导入方式 |
|---|---|---|
| user | 用户基本信息表 | 全量 |
| user_extend | 用户信息扩展表 | 全量 |
| user_addr | 用户收货地址表 | 全量 |
| goods_info | 商品信息表 | 全量 |
| category_code | 商品类目码表 | 全量 |
| user_order | 订单表 | 增量 |
| order_item | 订单商品表 | 增量 |
| order_delivery | 订单收货表 | 增量 |
| payment_flow | 支付流水表 | 增量 |
注意:手机号在采集的时候需要脱敏处理,因为数据进入到数据仓库之后会有很多人使用,为保护用户隐私,最好在采集的时候进行脱敏处理。 所以在采集user和user_addr表中的数据时对手机号进行脱敏。
数据采集脚本开发
创建目录/data/soft/warehouse_shell_good_order,针对商品订单相关的脚本全部放在这里面
cd /data/soft/
mkdir warehouse_shell_good_order
创建脚本sqoop_collect_data_util.sh
#!/bin/bash
# 采集MySQL中的数据导入到HDFS中
if [ $# != 2 ]
then
echo "参数异常:sqoop_collect_data_util.sh <sql> <hdfs_path>"
exit 100
fi
# 数据SQL
# 例如:select id,name from user where id >1
sql=$1
# 导入到HDFS的路径
hdfs_path=$2
sqoop import \
--connect jdbc:mysql://192.168.1.4:3306/mall?serverTimezone=UTC \
--username root \
--password root \
--target-dir "${hdfs_path}" \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t' \
--query "${sql}"' and $CONDITIONS' \
--null-string '\\N' \
--null-non-string '\\N'
全量数据采集collect_data_full.sh
#!/bin/bash
# 全量数据采集
# 每天凌晨执行一次
# 默认获取昨天的日期,也支持传参指定一个日期
if [ "z$1" = "z" ]
then
dt=`date +%Y%m%d --date="1 days ago"`
else
dt=$1
fi
# SQL语句
user_sql="select user_id,user_name,user_gender,user_birthday,e_mail,concat(left(mobile,3), '****' ,right(mobile,4)) as mobile,register_time,is_blacklist from user where 1=1"
user_extend_sql="select user_id,is_pregnant_woman,is_have_children,is_have_car,phone_brand,phone_cnt,change_phone_cnt,weight,height from user_extend where 1=1"
user_addr_sql="select addr_id,user_id,addr_name,order_flag,user_name,concat(left(mobile,3), '****' ,right(mobile,4)) as mobile from user_addr where 1=1"
goods_info_sql="select goods_id,goods_no,goods_name,curr_price,third_category_id,goods_desc,create_time from goods_info where 1=1"
category_code_sql="select first_category_id,first_category_name,second_category_id,second_catery_name,third_category_id,third_category_name from category_code where 1=1"
# 路径后缀
path_prefix="hdfs://bigdata1:9000/data/ods"
# 输出路径
user_path="${path_prefix}/user/${dt}"
user_extend_path="${path_prefix}/user_extend/${dt}"
user_addr_path="${path_prefix}/user_addr/${dt}"
goods_info_path="${path_prefix}/goods_info/${dt}"
category_code_path="${path_prefix}/category_code/${dt}"
# 采集数据
echo "开始采集..."
echo "采集表:user"
sh sqoop_collect_data_util.sh "${user_sql}" "${user_path}"
echo "采集表:user_extend"
sh sqoop_collect_data_util.sh "${user_extend_sql}" "${user_extend_path}"
echo "采集表:user_addr"
sh sqoop_collect_data_util.sh "${user_addr_sql}" "${user_addr_path}"
echo "采集表:goods_info"
sh sqoop_collect_data_util.sh "${goods_info_sql}" "${goods_info_path}"
echo "采集表:category_code"
sh sqoop_collect_data_util.sh "${category_code_sql}" "${category_code_path}"
echo "结束采集..."
增量数据采集collect_data_incr.sh
#!/bin/bash
# 增量数据采集
# 每天凌晨执行一次
# 默认获取昨天的日期,也支持传参指定一个日期
if [ "z$1" = "z" ]
then
dt=`date +%Y%m%d --date="1 days ago"`
else
dt=$1
fi
# 转换日期格式,20260101 改为 2026-01-01
dt_new=`date +%Y-%m-%d --date="${dt}"`
# SQL语句
user_order_sql="select order_id,order_date,user_id,order_money,order_type,order_status,pay_id,update_time from user_order where order_date >= '${dt_new} 00:00:00' and order_date <= '${dt_new} 23:59:59'"
order_item_sql="select order_id,goods_id,goods_amount,curr_price,create_time from order_item where create_time >= '${dt_new} 00:00:00' and create_time <= '${dt_new} 23:59:59'"
order_delivery_sql="select order_id,addr_id,user_id,carriage_money,create_time from order_delivery where create_time >= '${dt_new} 00:00:00' and create_time <= '${dt_new} 23:59:59'"
payment_flow_sql="select pay_id,order_id,trade_no,pay_money,pay_type,pay_time from payment_flow where pay_time >= '${dt_new} 00:00:00' and pay_time <= '${dt_new} 23:59:59'"
# 路径后缀
path_prefix="hdfs://bigdata1:9000/data/ods"
# 输出路径
user_order_path="${path_prefix}/user_order/${dt}"
order_item_path="${path_prefix}/order_item/${dt}"
order_delivery_path="${path_prefix}/order_delivery/${dt}"
payment_flow_path="${path_prefix}/payment_flow/${dt}"
# 采集数据
echo "开始采集..."
echo "采集表:user_order"
sh sqoop_collect_data_util.sh "${user_order_sql}" "${user_order_path}"
echo "采集表:order_item"
sh sqoop_collect_data_util.sh "${order_item_sql}" "${order_item_path}"
echo "采集表:order_delivery"
sh sqoop_collect_data_util.sh "${order_delivery_sql}" "${order_delivery_path}"
echo "采集表:payment_flow"
sh sqoop_collect_data_util.sh "${payment_flow_sql}" "${payment_flow_path}"
echo "结束采集..."
执行脚本
sh collect_data_full.sh 20220211
sh collect_data_incr.sh 20220211
查看HDFS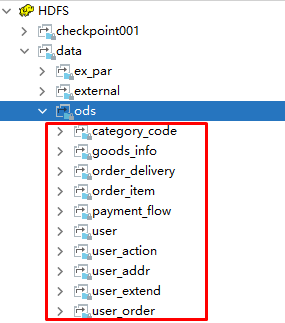
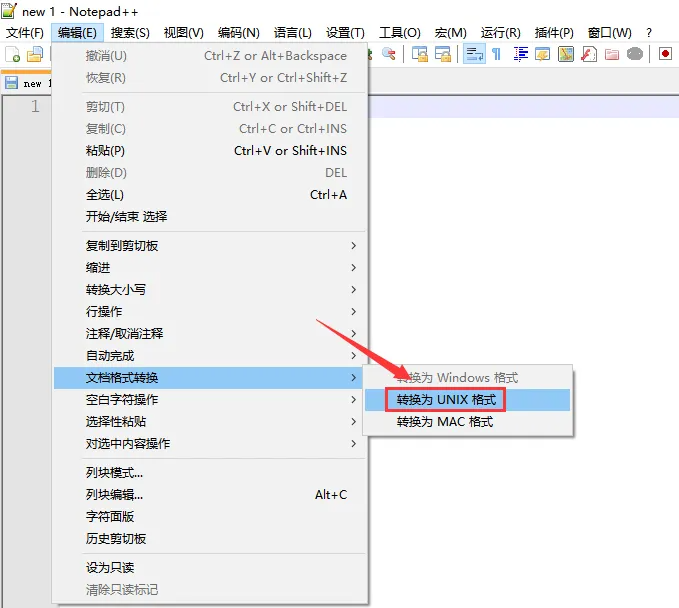
注意:如果在windows中使用notepad++开发shell脚本的时候,需要将此参数设置为UNIX。
这个我们之前在讲shell的时候已经讲过了,在这再重复一遍。
否则在windows中开发的脚本直接上传到linux中执行会报错。

若有收获,就点个赞吧
0 人点赞
