Window的概念
Flink 认为 批处理 是 流处理 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。而Window就是从 流处理 到 批处理 的一个桥梁。
Window是一种可以把无界数据切割为有界数据块的手段
例如,对流中的所有元素进行计数是不可能的,因为通常流是无限的(无界的)。
所以,流上的聚合需要由 Window 来划定范围,比如 “计算过去5分钟” 或者 “最后100个元素的和”。
window可以是时间驱动的 (Time Window)(比如:每30秒)或者数据驱动的(Count Window)(如每100个元素)。
DataStream API提供了基于Time和Count的Window。同时,由于某些特殊的需要,DataStream API也提供了定制化的Window操作,供用户自定义Window。
Window的类型
滚动窗口(没有重叠)
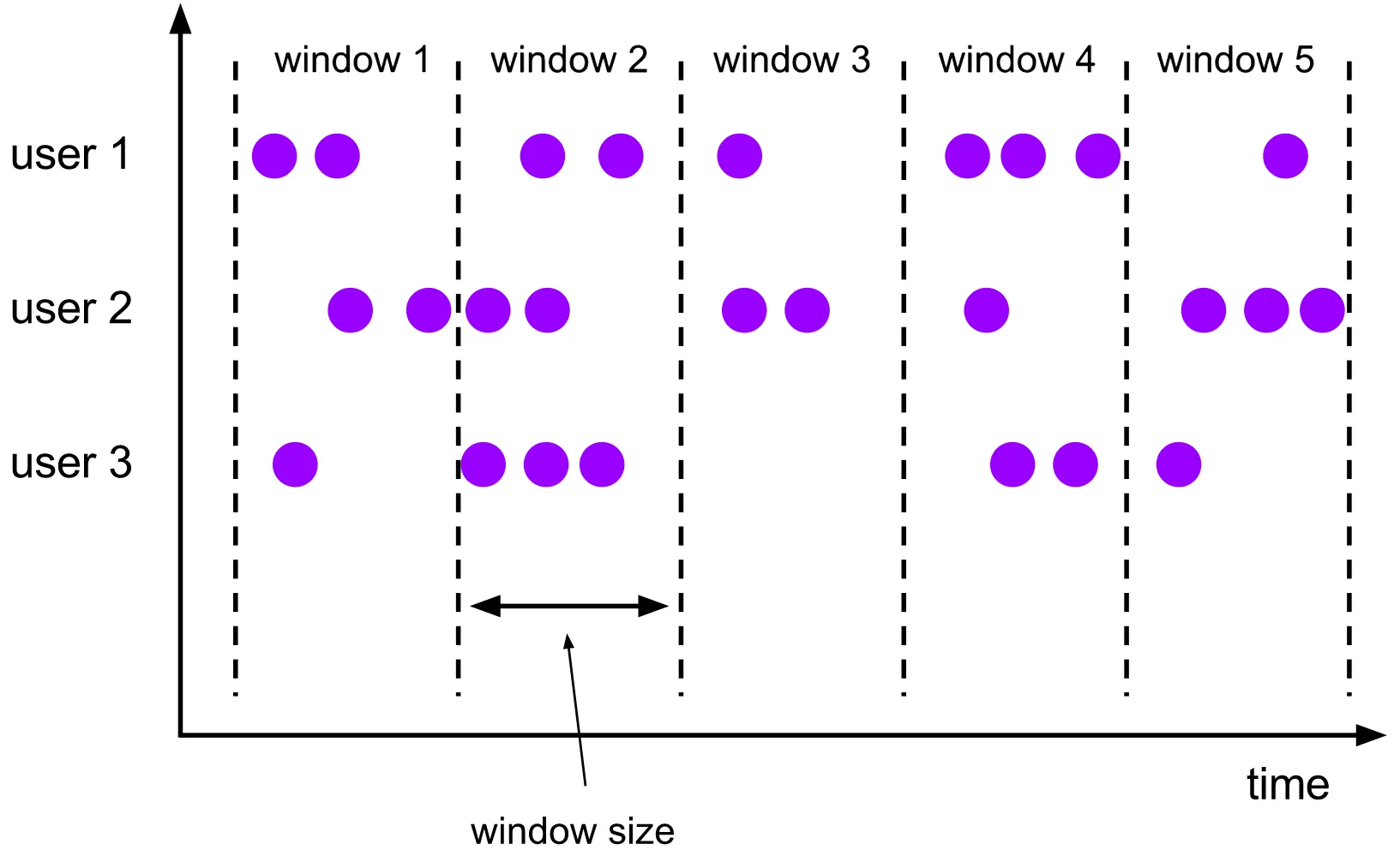
滑动窗口(有重叠)
Sliding Windows:表示窗口内的数据有重叠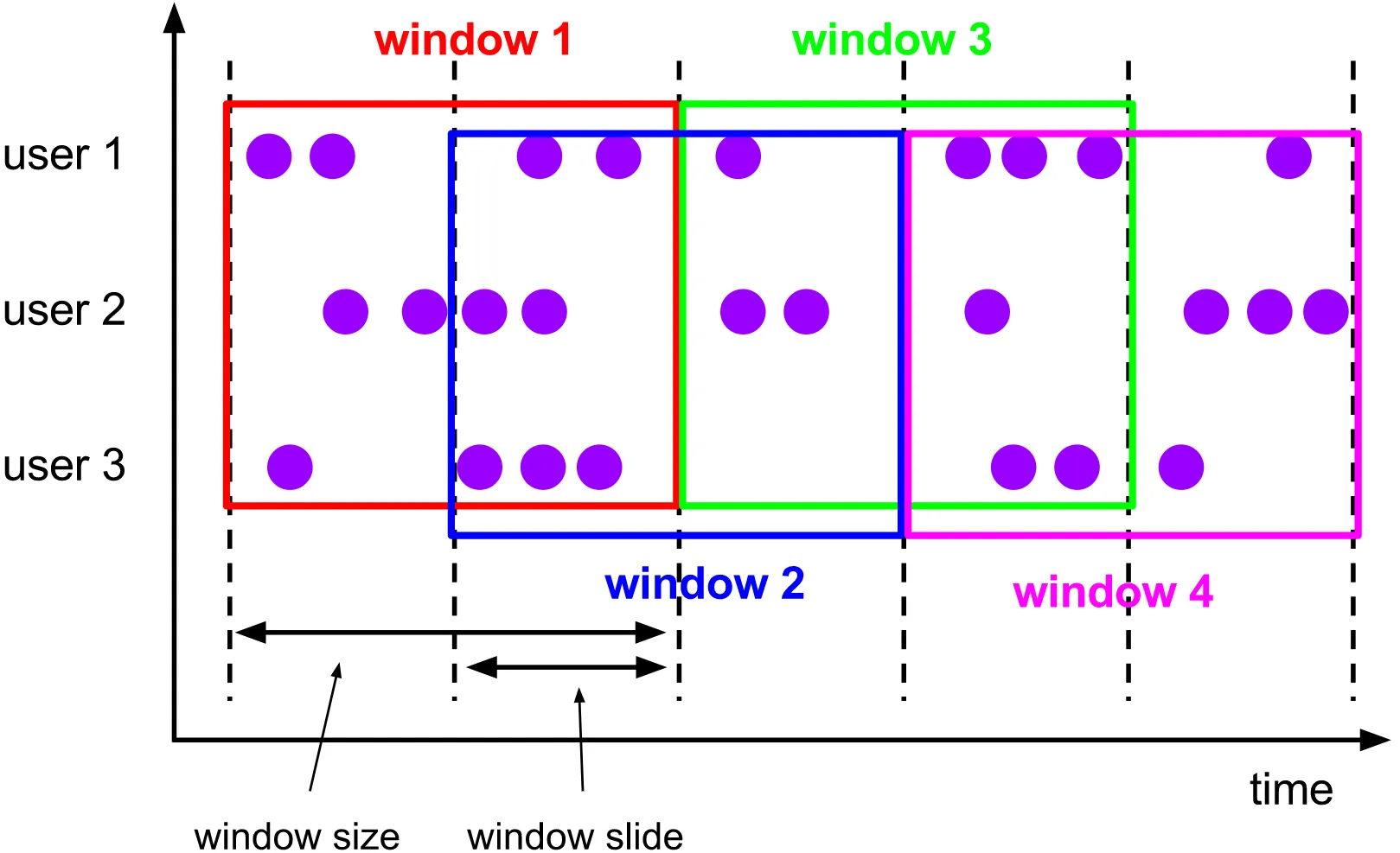
针对Window的类型关系进行一个汇总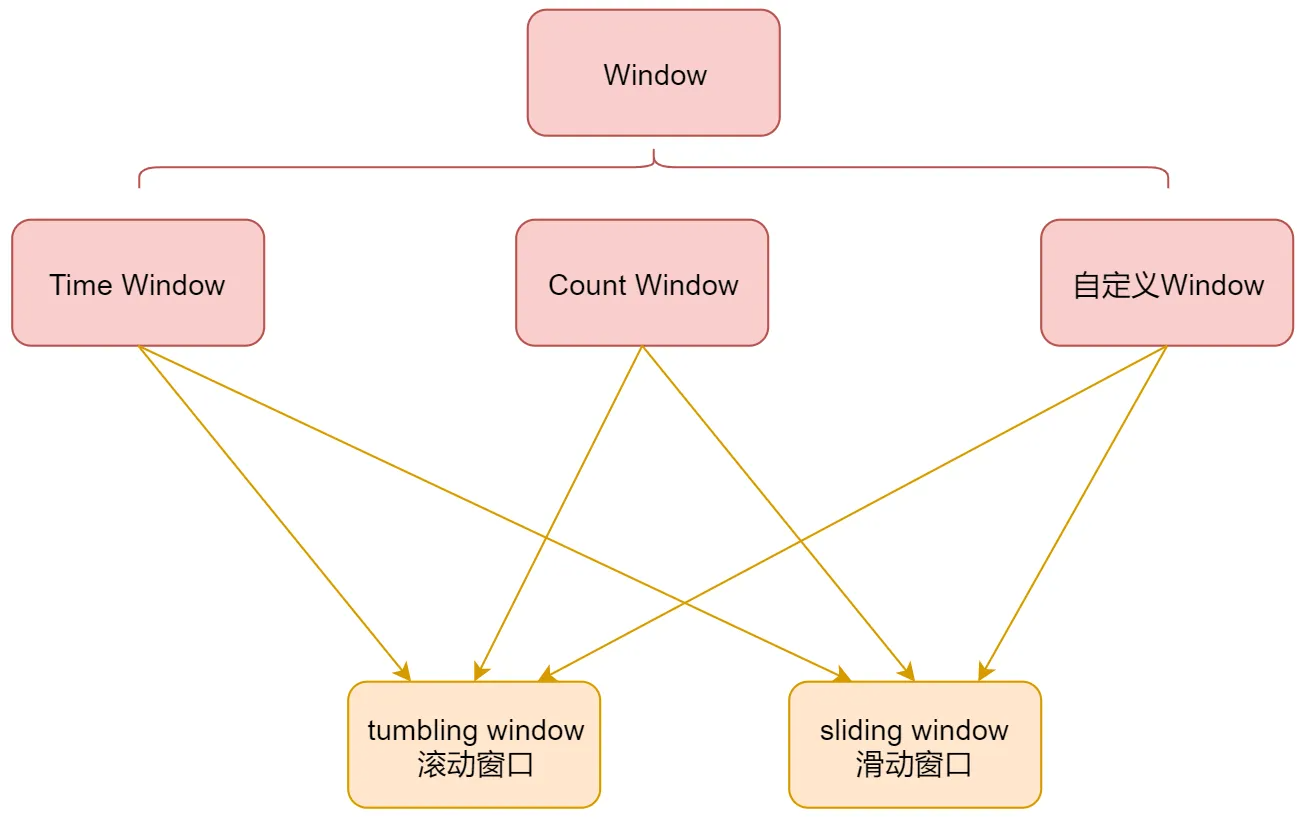
TimeWindow(时间窗口)
TimeWindow 是根据时间对数据流切分窗口,TimeWindow可以支持滚动窗口和滑动窗口。
滚动
timeWindow(Time.seconds(10)):滚动窗口的窗口大小为10秒,对每10秒内的数据进行聚合计算
object TimeWindowOp1 {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment//连接socket获取输入数据val text = env.socketTextStream("bigdata1", 9002)//TimeWindow之滚动窗口:每隔10秒计算一次前10秒时间窗口内的数据text.flatMap(_.split(" ")).map((_, 1)).keyBy(0) //根据tuple2中的第一列进行分组z.timeWindow(Time.seconds(10)).sum(1) //基于tup的第二列聚合,使用sum或者reduce都可以.print()env.execute()}}
在bigdata1上开启socket
[root@bigdata1 ~]# nc -l 9002hello youhello me
滑动
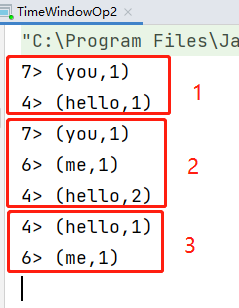
timeWindow(Time.seconds(10),Time.seconds(5)):滑动窗口的窗口大小为10秒,滑动间隔为5秒,就是每隔5秒计算前10秒内的数据
object TimeWindowOp2 {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment//连接socket获取输入数据val text = env.socketTextStream("bigdata1", 9002)//TimeWindow之滑动窗口:每隔5秒计算一次前10秒时间窗口内的数据text.flatMap(_.split(" ")).map((_, 1)).keyBy(0)//第一个参数:窗口大小,第二个参数:滑动间隔.timeWindow(Time.seconds(10), Time.seconds(5)).sum(1).print()env.execute()}}
测试
先打出hello you,等idea控制台显示出后,再打出hello me
[root@bigdata1 ~]# nc -l 9002hello youhello me
CountWindow(计数窗口)
CountWindow 是根据元素个数对数据流切分窗口,CountWindow也可以支持滚动窗口和滑动窗口。
滚动
countWindow(5):滚动窗口的大小是5个元素,也就是当窗口中填满5个元素的时候,就会对窗口进行计算了
object CountWindowOp1 {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironmentval text = env.socketTextStream("bigdata1", 9002)/*** 注意:由于我们在这里使用keyBy,会先对数据分组* 如果某个分组对应的数据窗口内达到了5个元素,这个窗口才会被触发执行*///CountWindow之滚动窗口:每隔5个元素计算一次前5个元素text.flatMap(_.split(" ")).map((_, 1)).keyBy(0)//指定窗口大小.countWindow(5).sum(1).print()env.execute()}}
通过socket输入数据
[root@bigdata1 ~]# nc -l 9002hello youhello mehello hello helloyou you you you

滑动
countWindow(5,1):滑动窗口的窗口大小是5个元素,滑动的间隔为1个元素,也就是说每新增1个元素就会对前面5个元素计算一次
object CountWindowOp2 {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironmentval text = env.socketTextStream("bigdata1", 9002)//CountWindow之滑动窗口:每隔1个元素计算一次前5个元素text.flatMap(_.split(" ")).map((_, 1)).keyBy(0)//第一个参数:窗口大小,第二个参数:滑动间隔.countWindow(5, 1).sum(1).print()}}
自定义Window
其实window还可以再细分一下
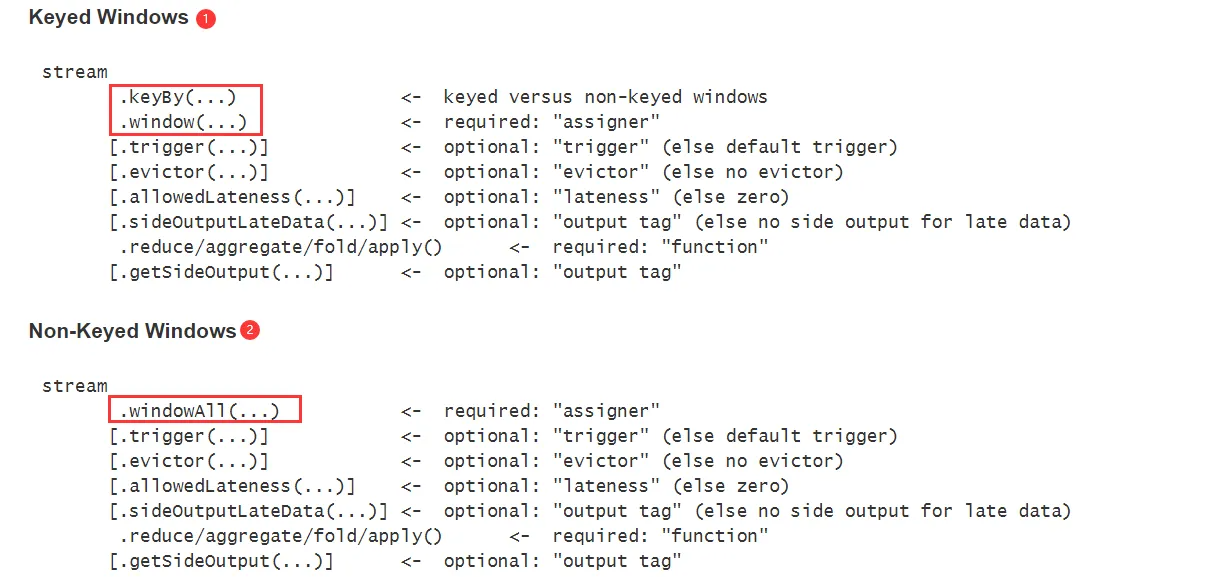
- 一种是基于Key的Window
- 一种是不基于Key的Window
咱们前面演示的都是基于key的window,就是在使用window之前,先执行了keyBy分组操作,如果需求中不需要根据key进行分组的话,可以不使用keyBy,这样在使用window的时候需要使用timeWindowAll()和countWindowAll()。
window(基于key)
windowAll(不基于key)
针对不基于key的window需要使用windowAll函数
其实我们前面所说的TimeWindow和TimeWindowAll底层用的就是window和windowAll函数,可以这样理解,TimeWindow是官方封装好的window。
以TimeWindow为例,看一下源码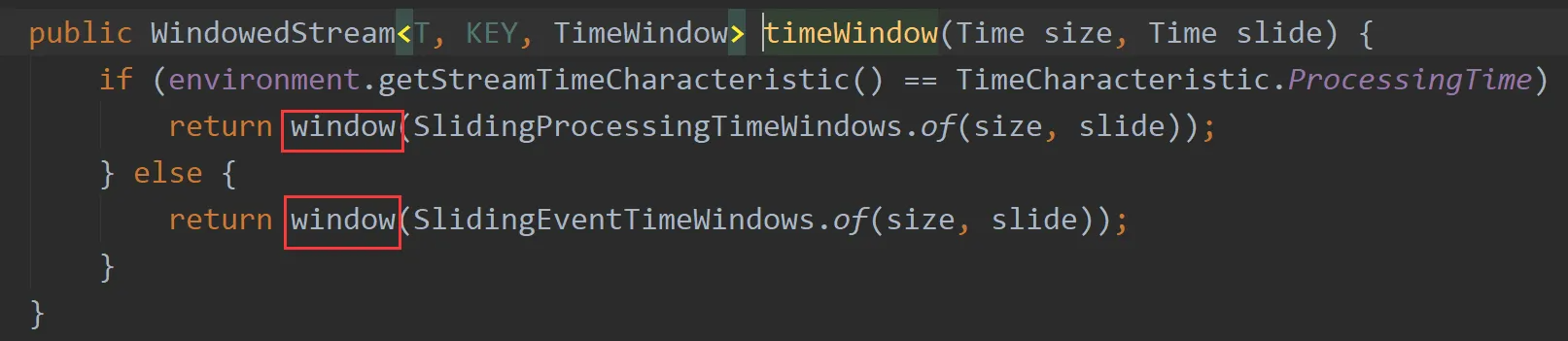
TimeWindowAll的源码是这样的
下面我们来试一下自己使用window函数封装一个MyTimeWindow
/*** 需求:自定义MyTimeWindow*/object MyTimeWindow {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironmentval text = env.socketTextStream("bigdata1", 9002)import org.apache.flink.api.scala._//自定义MyTimeWindow滚动窗口:每隔10秒计算一次前10秒时间窗口内的数据text.flatMap(_.split(" ")).map((_, 1)).keyBy(0)//窗口大小.window(TumblingProcessingTimeWindows.of(Time.seconds(10))).sum(1).print()env.execute()}}
Window聚合
增量聚合
窗口中每进入一条数据,就进行一次计算
常见的一些增量聚合函数如下:reduce()、aggregate()、sum()、min()、max()
下面我们来看一个增量聚合的例子,累加求和,对 8 、12、7、10这四条数据进行累加求和
第一次进来一条数据8,则立刻进行累加求和,结果为8。
第二次进来一条数据12,则立刻进行累加求和,结果为20。
第三次进来一条数据7,则立刻进行累加求和,结果为27。
第四次进来一条数据10,则立刻进行累加求和,结果为37。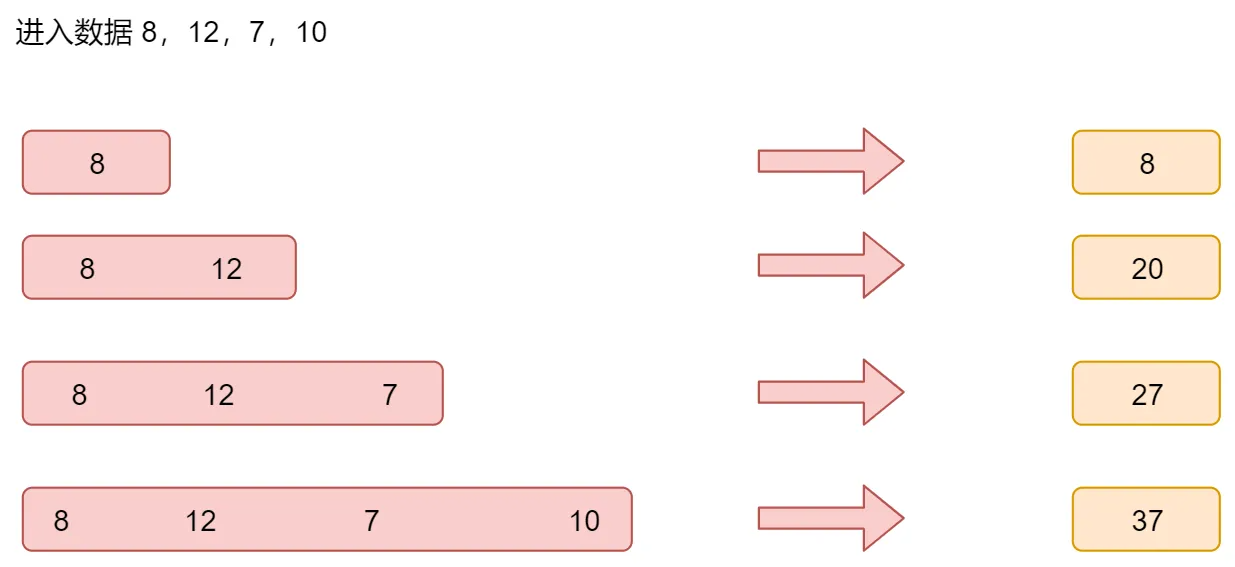
再来看一下Reduce函数的使用
从这里面可以看出来reduce是每次获取一条数据,和上一次的执行结果求和,也就是来一条数据立刻计算一次。
这就是增量聚合。
全量聚合
等属于窗口的数据到齐,才开始进行聚合计算【可以实现对窗口内的数据进行排序等需求】
常见的一些全量聚合函数为apply(windowFunction)和process(processWindowFunction)
注意:processWindowFunction比windowFunction提供了更多的Context(上下文)信息。
下面我们来看一个全量聚合的例子,求最大值,对8 、12、7、10这四条数据求最大值
第一次进来一条数据8。
第二次进来一条数据12。
第三次进来一条数据7。
第四次进来一条数据10,此时窗口触发,才会对窗口内的数据进行排序,获取最大值。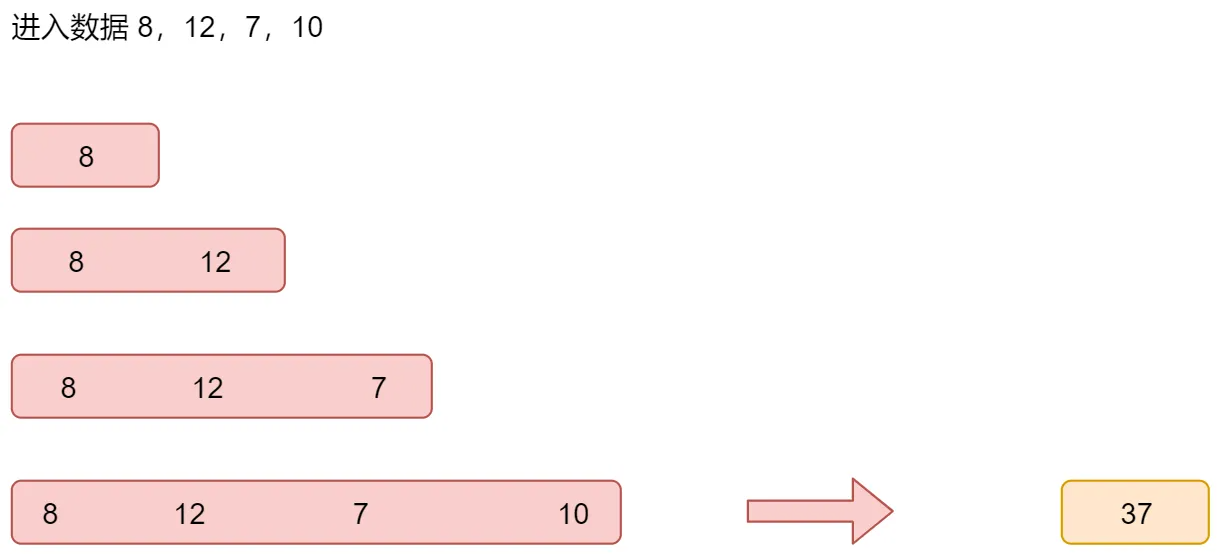
下面来看一下apply函数的使用
还有process的使用
在这我们会发现,这些全量聚合的函数获取到的输入数据是一个Iterable,里面是包含多条数据的,从这可以看出来,这两个函数是一次性获取一个窗口内的所有数据进行计算的。
Time
Flink中Time的类型
Event Time
Ingestion time
Processing Time(默认)
事件被处理时当前系统的时间
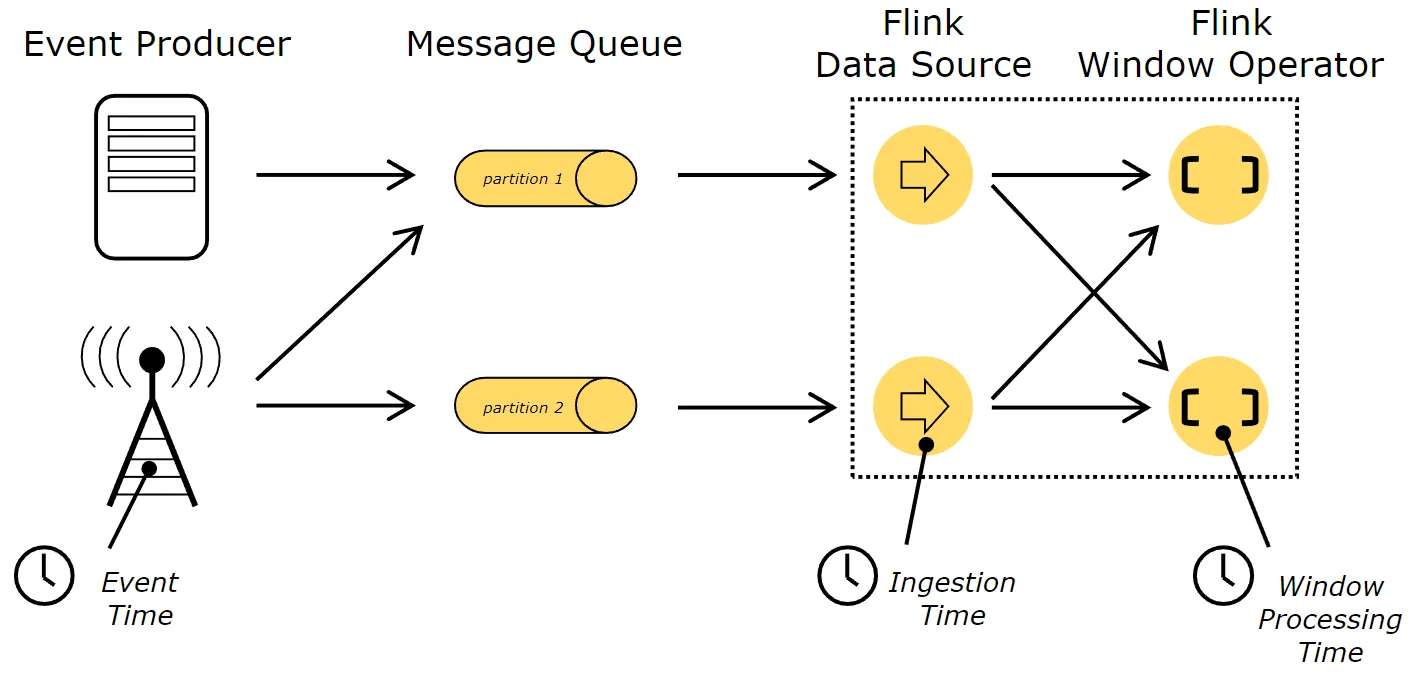
Time案例分析
举个例子:
原始日志是这样的
:::info
2026-01-01 10:00:01 INFO executor.Executor: Finished task in state 0.0
:::
2026-01-01 10:00:01是日志数据产生的时间
日志数据进入Flink的时间是:2026-01-01 20:00:01
日志数据到达Window处理的时间是:2026-01-01 20:00:02
如果我们想要统计每分钟内接口调用失败的错误日志个数,使用哪个时间才有意义?
因为数据有可能会出现延迟,如果使用 数据进入Flink的时间 或者 Window处理的时间,其实是没有意义的,这个时候需要使用原始日志中的时间Event Time才是有意义的,这个才是数据产生的时间。
Time类型设置
Flink的流处理中,默认使用的是哪个时间呢?
默认情况下Flink在流处理中使用的时间是ProcessingTime
查看源码:在类StreamExecutionEnvironment中
private static final TimeCharacteristic DEFAULT_TIME_CHARACTERISTIC = TimeCharacteristic.ProcessingTime;
如何修改呢?
想要修改的话可以使用setStreamTimeCharacteristic(…)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
或者
env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime)

若有收获,就点个赞吧
0 人点赞
