基本数据格式
Hive 的基本数据类型和关系型数据库中的基本数据类型类似。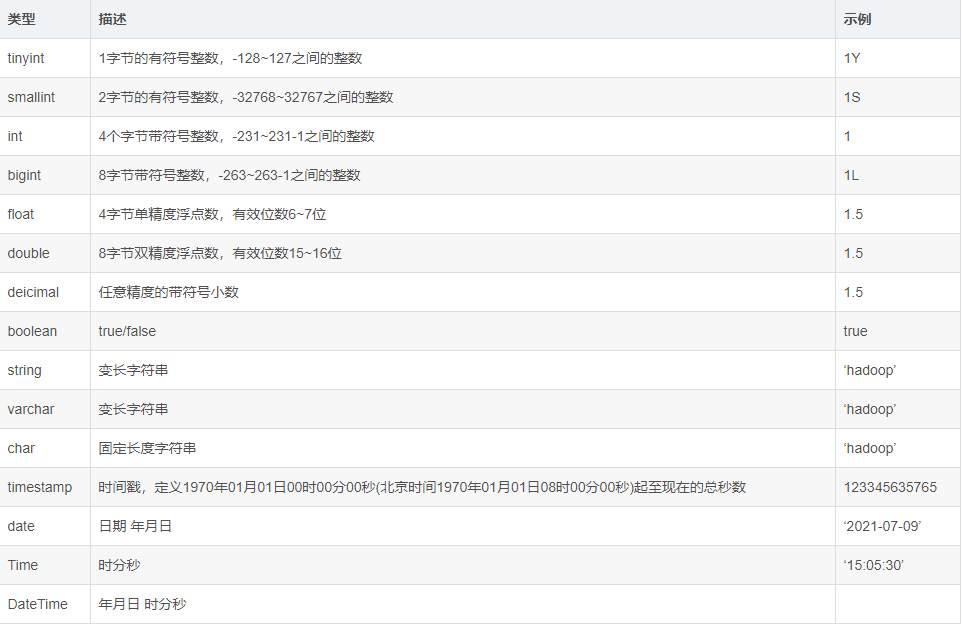
复合数据类型
Hive 除了以上支持的基本数据类型,还支持以下三种集合数据类型,分别为 array、map 和 struct。
array
使用array存储用户的兴趣爱好

建表:指定列分隔符、array分隔符,行分隔符。(注意行分隔符要放在最后)
create table stu(id int,name string,favors array<string>) row format delimitedfields terminated by '\t'collection items terminated by ','lines terminated by '\n';
加载数据
load data local inpath '/data/soft/hivedata/stu.data' into table stu;

map
使用map存储学生的考试成绩

建表
create table stu2
(
id int,
name string,
scores map<string,int>
) row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
加载数据
load data local inpath '/data/soft/hivedata/stu2.data' into table stu2;

查询学生的语文、数学成绩
select id, name, scores['chinese'] as ch_score, scores['math'] as math_score
from stu2;

struct
使用struct存储员工地址信息(户籍地址,公司地址)

建表
create table stu3
(
id int,
name string,
address struct<home_addr:string,office_addr:string>
) row format delimited
fields terminated by '\t'
collection items terminated by ','
lines terminated by '\n';
加载数据
load data local inpath '/data/soft/hivedata/stu3.data' into table stu3;

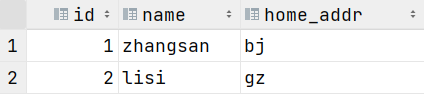
查询员工的户籍地
select id, name, address.home_addr
from stu3
综合案例
存储ID、姓名、爱好、成绩、地址

建表
create table student
(
id int,
name string,
favors array<string>,
scores map<string,int>,
address struct<home_addr:string,office_addr:string>
) row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
加载数据
load data local inpath '/data/soft/hivedata/student.data' into table student;

思考题

答:
可以一一对应迁移,优点是迁移成本非常低,包括DDL和业务逻辑,几乎不需要修改,可以直接使用。缺点是产生大量的表连接,造成查询慢。
可以一对多,mysql中的多张关联表可以创建为hive中的一张表。优点是减少表连接操作。缺点是迁移成本高,需要修改原有的业务逻辑。
实际上,在我们日常的开发过程中遇到这样的问题,要想比较完美、顺利的解决,一般都分为两个阶段,第一个阶段,现在快捷迁移,就是上面说的一一对应,让我们的系统能跑起来,在此基础之上呢,再做一张大表,尽量包含以上所有字段,例如:
stu(id, name, address struct
等第二个阶段完工之后了,就可以跑在新的系统里面了。

若有收获,就点个赞吧
0 人点赞
