小文件问题

需求: 10个小文件,统计里面单词出现的情况
SequenceFile

可以理解为把很多小文件压缩为一个大压缩包
/*** 小文件解决方案之SequenceFile*/public class SmallFileSeq {public static void main(String[] args) throws Exception {//生成SequenceFile文件write("D:\\smallFile", "/seqFile");//读取SequenceFile文件read("/seqFile");}/*** 生成SequenceFile文件** @param inputDir 输入目录-windows目录* @param outputFile 输出文件-hdfs文件* @throws Exception*/private static void write(String inputDir, String outputFile) throws Exception {//创建一个配置对象Configuration conf = new Configuration();//指定HDFS的地址conf.set("fs.defaultFS", "hdfs://bigdata1:9000");//获取操作HDFS的对象FileSystem fileSystem = FileSystem.get(conf);//删除HDFS上的输出文件fileSystem.delete(new Path(outputFile), true);//构造opts数组,有三个元素/*第一个是输出路径【文件】第二个是key的类型第三个是value的类型*/SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{SequenceFile.Writer.file(new Path(outputFile)),SequenceFile.Writer.keyClass(Text.class),SequenceFile.Writer.valueClass(Text.class)};//创建了一个writer实例SequenceFile.Writer writer = SequenceFile.createWriter(conf, opts);//指定需要压缩的文件的目录File inputDirPath = new File(inputDir);if (inputDirPath.isDirectory()) {//获取目录中的文件File[] files = inputDirPath.listFiles();//迭代文件for (File file : files) {//获取文件的全部内容String content = FileUtils.readFileToString(file, "UTF-8");//获取文件名String fileName = file.getName();Text key = new Text(fileName);Text value = new Text(content);//向SequenceFile中写入数据writer.append(key, value);}}writer.close();}/*** 读取SequenceFile文件** @param inputFile SequenceFile文件路径* @throws Exception*/private static void read(String inputFile) throws Exception {//创建一个配置对象Configuration conf = new Configuration();//指定HDFS的地址conf.set("fs.defaultFS", "hdfs://bigdata1:9000");//创建阅读器SequenceFile.Reader reader = new SequenceFile.Reader(conf, SequenceFile.Reader.file(new Path(inputFile)));Text key = new Text();Text value = new Text();//循环读取数据while (reader.next(key, value)) {//输出文件名称System.out.print("文件名:" + key.toString() + ",");//输出文件内容System.out.println("文件内容:" + value.toString() + "");}reader.close();}}
MapFile

/*** 小文件解决方案之MapFile*/public class SmallFileMap {public static void main(String[] args) throws Exception{//生成MapFile文件write("D:\\smallFile","/mapFile");//读取MapFile文件read("/mapFile");}/*** 生成MapFile文件* @param inputDir 输入目录-windows目录* @param outputDir 输出目录-hdfs目录* @throws Exception*/private static void write(String inputDir,String outputDir) throws Exception{//创建一个配置对象Configuration conf = new Configuration();//指定HDFS的地址conf.set("fs.defaultFS","hdfs://bigdata1:9000");//获取操作HDFD的对象FileSystem fileSystem = FileSystem.get(conf);//删除HDFS上的输出文件fileSystem.delete(new Path(outputDir),true);//构造opts数组,有两个元素/*第一个是key的类型第二个是value的类型*/SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{MapFile.Writer.keyClass(Text.class),MapFile.Writer.valueClass(Text.class)};//创建了一个writer实例MapFile.Writer writer = new MapFile.Writer(conf, new Path(outputDir), opts);//指定需要压缩的文件的目录File inputDirPath = new File(inputDir);if(inputDirPath.isDirectory()){//获取目录中的文件File[] files = inputDirPath.listFiles();//迭代文件for (File file: files) {//获取文件的全部内容String content = FileUtils.readFileToString(file, "UTF-8");//获取文件名String fileName = file.getName();Text key = new Text(fileName);Text value = new Text(content);//向SequenceFile中写入数据writer.append(key,value);}}writer.close();}/*** 读取MapFile文件* @param inputDir MapFile文件路径* @throws Exception*/private static void read(String inputDir)throws Exception{//创建一个配置对象Configuration conf = new Configuration();//指定HDFS的地址conf.set("fs.defaultFS","hdfs://bigdata1:9000");//创建阅读器MapFile.Reader reader = new MapFile.Reader(new Path(inputDir),conf);Text key = new Text();Text value = new Text();//循环读取数据while(reader.next(key,value)){//输出文件名称System.out.print("文件名:"+key.toString()+",");//输出文件内容System.out.println("文件内容:"+value.toString()+"");}reader.close();}}
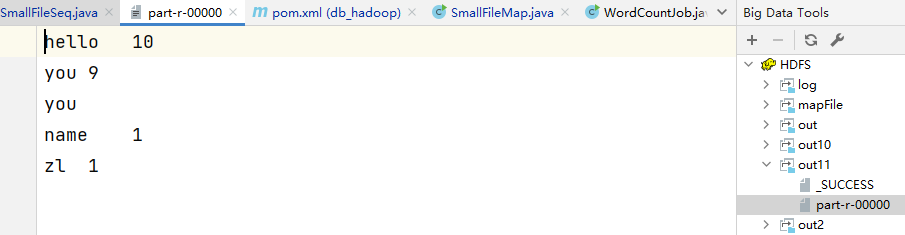
计算生成的SequenceFile
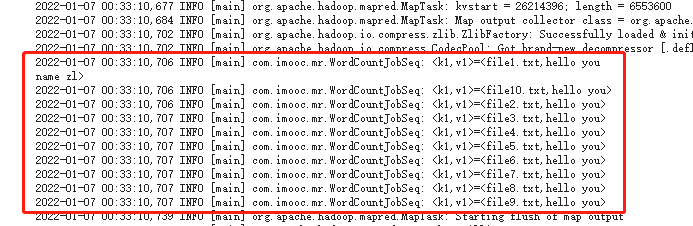
/*** 需求:读取SequenceFile文件*/@Slf4jpublic class WordCountJobSeq {/*** Map阶段*/public static class MyMapper extends Mapper<Text, Text, Text, LongWritable> {/*** 需要实现map函数* 这个map函数就是可以接收<k1,v1>,产生<k2,v2>** @param k1 这里的k1不是偏移量,而是SequenceFile的文件名* @param v1 文件内容* @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void map(Text k1, Text v1, Context context) throws IOException, InterruptedException {log.info("<k1,v1>=<{},{}>", k1.toString(), v1.toString());//对获取到的每一行数据进行切割,把单词切割出来String[] words = v1.toString().split(" ");//迭代切割出来的单词数据for (String word : words) {//把迭代出来的单词封装成<k2,v2>的形式Text k2 = new Text(word);LongWritable v2 = new LongWritable(1L);//把<k2,v2>写出去context.write(k2, v2);}}}/*** Reduce阶段*/public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {/*** 针对<k2,{v2...}>的数据进行累加求和,并且最终把数据转化为k3,v3写出去** @param k2* @param v2s* @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void reduce(Text k2, Iterable<LongWritable> v2s, Context context) throws IOException, InterruptedException {//创建一个sum变量,保存v2s的和long sum = 0L;//对v2s中的数据进行累加求和for (LongWritable v2 : v2s) {log.info("<k2,v2>=<{},{}>", k2.toString(), v2.get());sum += v2.get();}//组装k3,v3Text k3 = k2;LongWritable v3 = new LongWritable(sum);log.info("<k3,v3>=<{},{}>", k3.toString(), v3.get());// 把结果写出去context.write(k3, v3);}}/*** 组装Job=Map+Reduce*/public static void main(String[] args) {try {if (args.length != 2) {//如果传递的参数不够,程序直接退出System.exit(100);}//指定Job需要的配置参数Configuration conf = new Configuration();//创建一个JobJob job = Job.getInstance(conf);//注意了:这一行必须设置,否则在集群中执行的时候是找不到WordCountJob这个类的job.setJarByClass(WordCountJobSeq.class);//指定输入路径(可以是文件,也可以是目录)FileInputFormat.setInputPaths(job, new Path(args[0]));//指定输出路径(只能指定一个不存在的目录)FileOutputFormat.setOutputPath(job, new Path(args[1]));//指定map相关的代码job.setMapperClass(MyMapper.class);//指定k2的类型job.setMapOutputKeyClass(Text.class);//指定v2的类型job.setMapOutputValueClass(LongWritable.class);//设置输入数据处理类job.setInputFormatClass(SequenceFileInputFormat.class);//指定reduce相关的代码job.setReducerClass(MyReducer.class);//指定k3的类型job.setOutputKeyClass(Text.class);//指定v3的类型job.setOutputValueClass(LongWritable.class);//提交jobjob.waitForCompletion(true);} catch (Exception e) {e.printStackTrace();}}}
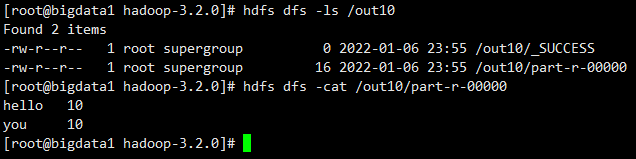
计算之前生成的seqFile
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mr.WordCountJobSeq /seqFile /out10


总结
1、将一堆小文件合并为一个SequenceFile
2、使用MapReduce计算SequenceFile
附:一个小文件有多行的情况时,可能需要修改


若有收获,就点个赞吧
0 人点赞
