Broker扩展
Broker的参数可以配置在kafka_2.12-2.4.1/config/server.properties这个配置文件中,Broker中支持的完整参数在官方文档中有
https://kafka.apache.org/24/documentation.html#brokerconfigs
针对Broker的参数,我们主要分析两块
写到磁盘策略
Log Flush Policy:数据flush到磁盘的策略
为了减少磁盘写入的次数,broker会将消息暂时缓存起来,当消息的个数达到一定阀值或者过了一定的时间间隔后,再flush到磁盘,这样可以减少磁盘IO调用的次数。
这块主要通过两个参数控制
log.flush.interval.messages一个分区的消息数阀值,达到该阈值则将该分区的数据flush到磁盘,注意这里是针对分区,因为topic是一个逻辑概念,分区是真实存在的,每个分区会在磁盘上产生一个目录#server.properties的log.dirscd /data/soft/kafka_2.12-2.4.1/kafka-logsll

这个参数的默认值为9223372036854775807,long的最大值 默认值太大了,所以建议修改,可以使用server.properties中针对这个参数指定的值10000,需要去掉注释之后这个参数才生效。log.flush.interval.ms间隔指定时间
默认间隔指定的时间将内存中缓存的数据flush到磁盘中,由文档可知,这个参数的默认值为null,此时会使用log.flush.scheduler.interval.ms参数的值,log.flush.scheduler.interval.ms参数的值默认是9223372036854775807,long的最大值
所以这个值也建议修改,可以使用server.properties中针对这个参数指定的值1000,单位是毫秒,表示每1秒写一次磁盘,这个参数也需要去掉注释之后才生效数据保存周期
Log Retention Policy:数据保存周期,默认7天
kafka中的数据默认会保存7天,如果kafka每天接收的数据量过大,这样是很占磁盘空间的,建议修改数据保存周期,我们之前在实际工作中是将数据保存周期改为了1天。
数据保存周期主要通过这几个参数控制log.retention.hours,这个参数默认值为168,单位是小时,就是7天,可以在这调整数据保存的时间,超过这个时间数据会被自动删除log.retention.bytes,这个参数表示当分区的文件达到一定大小的时候会删除它,如果设置了按照指定周期删除数据文件,这个参数不设置也可以,这个参数默认是没有开启的log.retention.check.interval.ms,这个参数表示检测的间隔时间,单位是毫秒,默认值是300000,就是5分钟,表示每5分钟检测一次文件看是否满足删除的时机Producer扩展
根据key分区
Producer默认是随机将数据发送到topic的不同分区中,也可以根据用户设置的算法来根据消息的key来计算输入到哪个partition里面
此时需要通过partitioner来控制,这个知道就行了,因为在实际工作中一般在向kafka中生产数据的都是不带key的,只有数据内容,所以一般都是使用随机的方式发送数据数据通讯方式
同步发送
生产者发出数据后,等接收方发回响应以后再发送下个数据的通讯方式异步发送
生产者发出数据后,不等接收方发回响应,接着发送下个数据的通讯方式。acks=1/all/0
具体的数据通讯策略是由acks参数控制的
acks默认为1,表示需要Leader节点回复收到消息,这样生产者才会发送下一条数据
acks:all,表示需要所有Leader+副本节点回复收到消息(acks=-1),这样生产者才会发送下一条数据
acks:0,表示不需要任何节点回复,生产者会继续发送下一条数据
再来看一下这个图: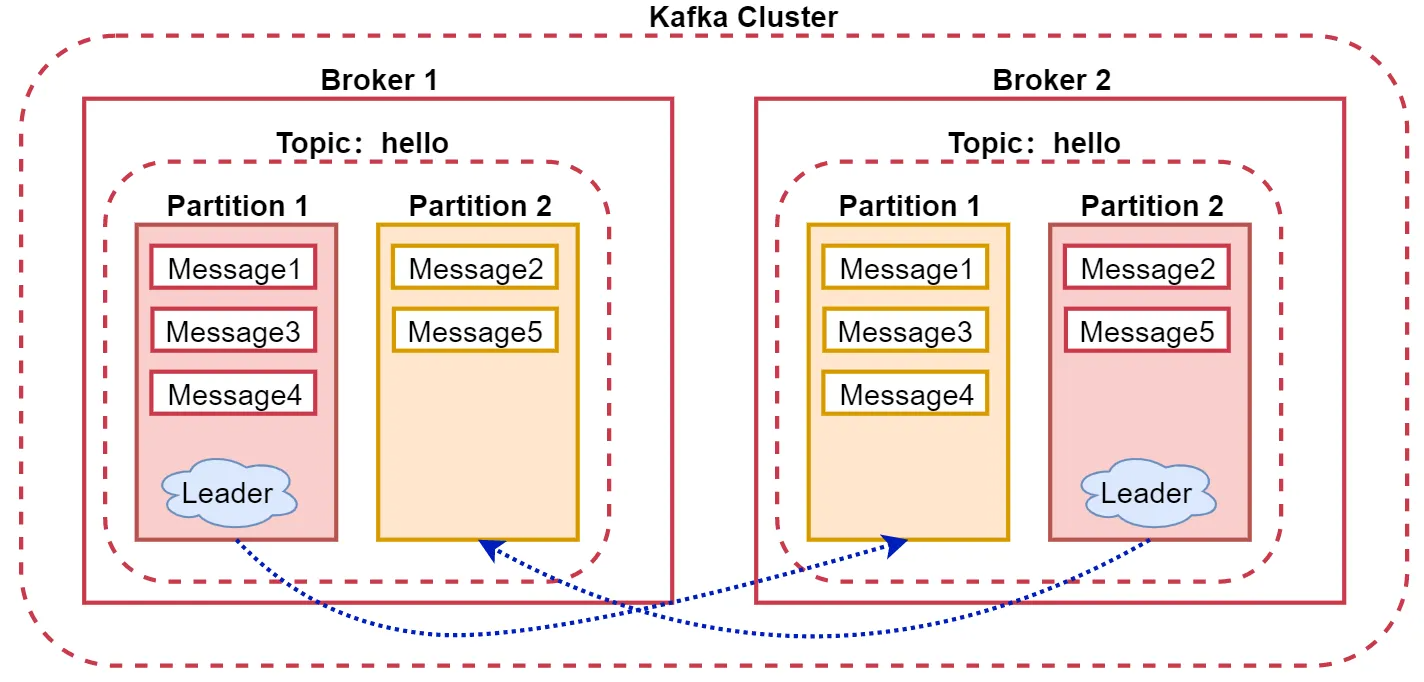
acks=1:向hello这个topic的partition1这个分区写数据的时候,只需要让leader所在的broker1这个节点回复确认收到的消息就可以了,这样生产者就可以发送下一条数据了
acks=all:需要partition1的这两个副本所在的节点(包含Leader)都回复收到消息,生产者才会发送下一条数据
acks=0:生产者不会等待任何partition所在节点的回复,它只管发送数据,不管你有没有收到,所以这种情况丢失数据的概率比较高。
Kafka如何保证数据不丢?
其实就是通过acks机制保证的,如果设置acks=all,则可以保证数据不丢,因为此时把数据发送给kafka之后,会等待对应partition所在的所有leader和副本节点都确认收到消息之后才会认为数据发送成功了,所以在这种策略下,只要把数据发送给kafka之后就不会丢了。
如果acks设置为1,则当我们把数据发送给partition之后,partition的leader节点也确认收到了,但是leader回复完确认消息之后,leader对应的节点就宕机了,副本partition还没来得及将数据同步过去,所以会存在丢失的可能性。
不过如果宕机的是副本partition所在的节点,则数据是不会丢的
如果acks设置为0的话就表示是顺其自然了,只管发送,不管kafka有没有收到,这种情况表示对数据丢不丢都无所谓了。
Consumer扩展
消费者组
每个consumer属于一个消费者组,通过group.id指定消费者组
查看消费者组
bin/kafka-consumer-groups.sh --list --bootstrap-server localhost:9092
组间
组内
组内的所有消费者消费同一份数据
Group中的一个分区只能被一个消费者消费,一个消费者可以消费多个分区 有三种情况: 1.消费者实列数小于分区数:一个消费者实列会消费多个分区 2.消费者实列数等于分区数: 一个消费者消费一个分区 3.消费者实列数大于分区数:会有几个消费者处于空闲的状态下。
理想情况下,Group中的Consumer实例的数量应该等于该Group订阅主题的总分区数。
来看下面这个图,加深一下理解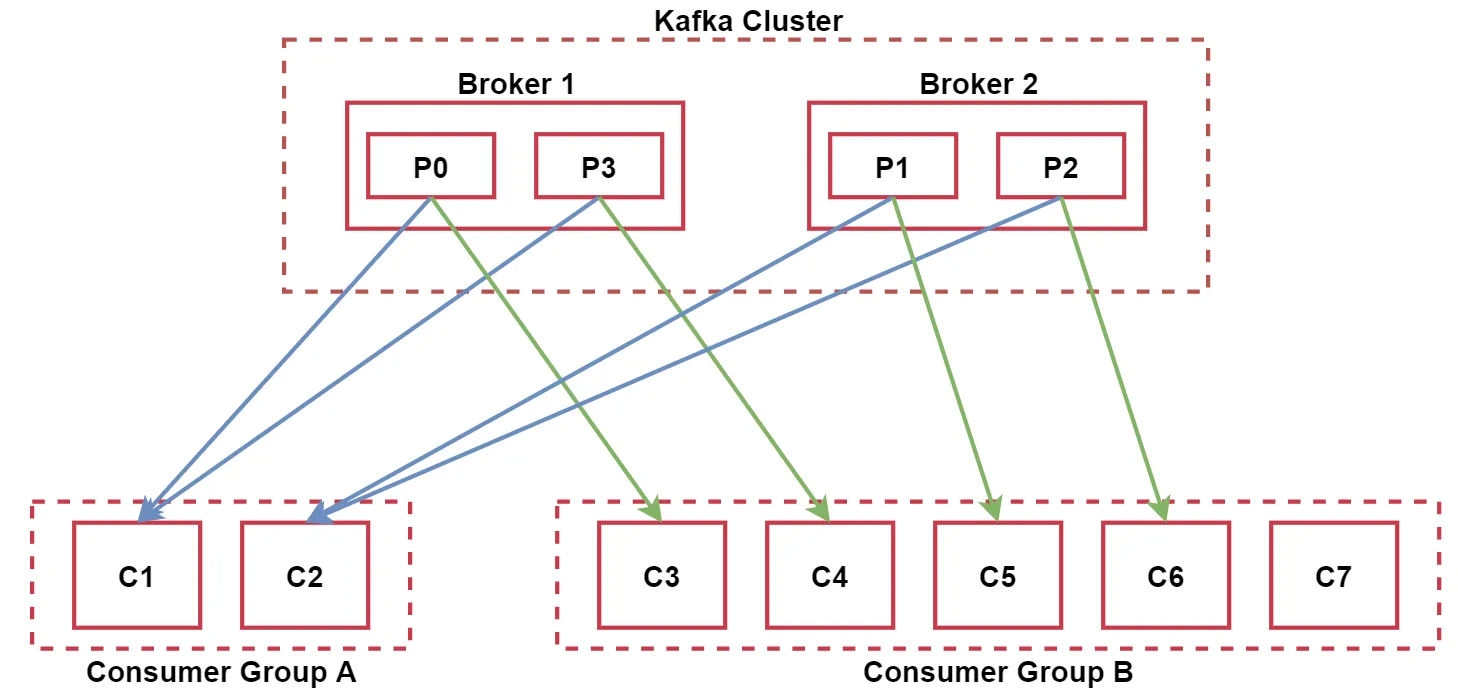
集群内有一个topic,这个topic有4个分区,P0,P1,P2,P3(没有副本)
下面有两个消费者组
Consumer Group A和Consumer Group B
其中Consumer Group A中有两个消费者 C1和C2,由于这个topic有4个分区,所以,C1负责消费两个分区的数据,C2负责消费两个分区的数据,这个属于组内消费
Consumer Group B有5个消费者,C3~C7,其中C3,C4,C5,C6分别消费一个分区的数据,而C7就是多余出来的了,因为现在这个消费者组内的消费者的数量比对应的topic的分区数量还多,但是一个分区同时只能被一个消费者消费,所以就会有一个消费者处于空闲状态。
这个也属于组内消费
Consumer Group A和Consumer Group B这两个消费者组属于组间消费,互不影响。
以QMQ为例
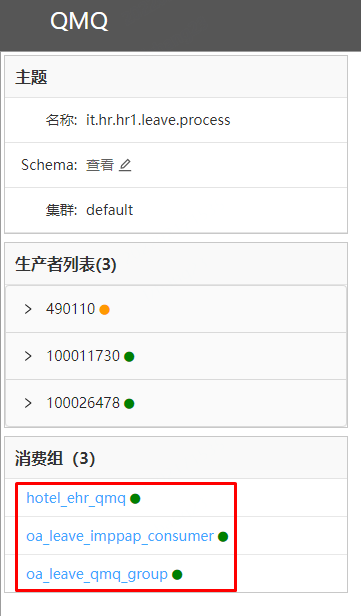
以QMQ为例
组间:hotel_ehr_qmq、oa_leave_imppap_consumer、oa_leave_qmq_group这三个消费者组都可以拿到相同的全部数据
组内:消费者组内的所有消费者共同消费同一份数据

若有收获,就点个赞吧
0 人点赞
